1 - Running Your First Query
In this multi-part tutorial, you will go through a full end-to-end example on how to use MotherDuck and DuckDB, push and share data, take advantage of hybrid query execution and query data using SQL through the MotherDuck UI or DuckDB CLI.
MotherDuck currently supports DuckDB 1.4.4. In US East (N. Virginia) - us-east-1, MotherDuck is compatible with client versions 1.3.0 through 1.4.4. In Europe (Frankfurt) - eu-central-1, MotherDuck supports client version 1.4.1 through 1.4.4.
Running your first query
Query from a shared database
Before playing with the dataset we just downloaded, let's run a couple simple queries on the shared sample database. This database contains a series of MotherDuck's public datasets and it's auto-attached for each user, meaning it's accessible directly within your MotherDuck session without any additional setup.
We will query the NYC 311 dataset first. This dataset contains over thirty million complaints citizens have filed with the New York City government. We'll select several columns and look at the complaints filed over a few days to demonstrate the Column Explorer feature of the MotherDuck UI.
SELECT
created_date,
agency_name,
complaint_type,
descriptor,
incident_address,
resolution_description
FROM
sample_data.nyc.service_requests
WHERE
created_date >= '2022-03-27'
AND created_date <= '2022-03-31';Want to explore the full interface? Try running this query in the MotherDuck UI to experience the complete dashboard, visual query builder, and advanced analytics features.
In the MotherDuck UI, the Column Explorer provides quick visual summaries of your data, helping you understand distributions and patterns at a glance.
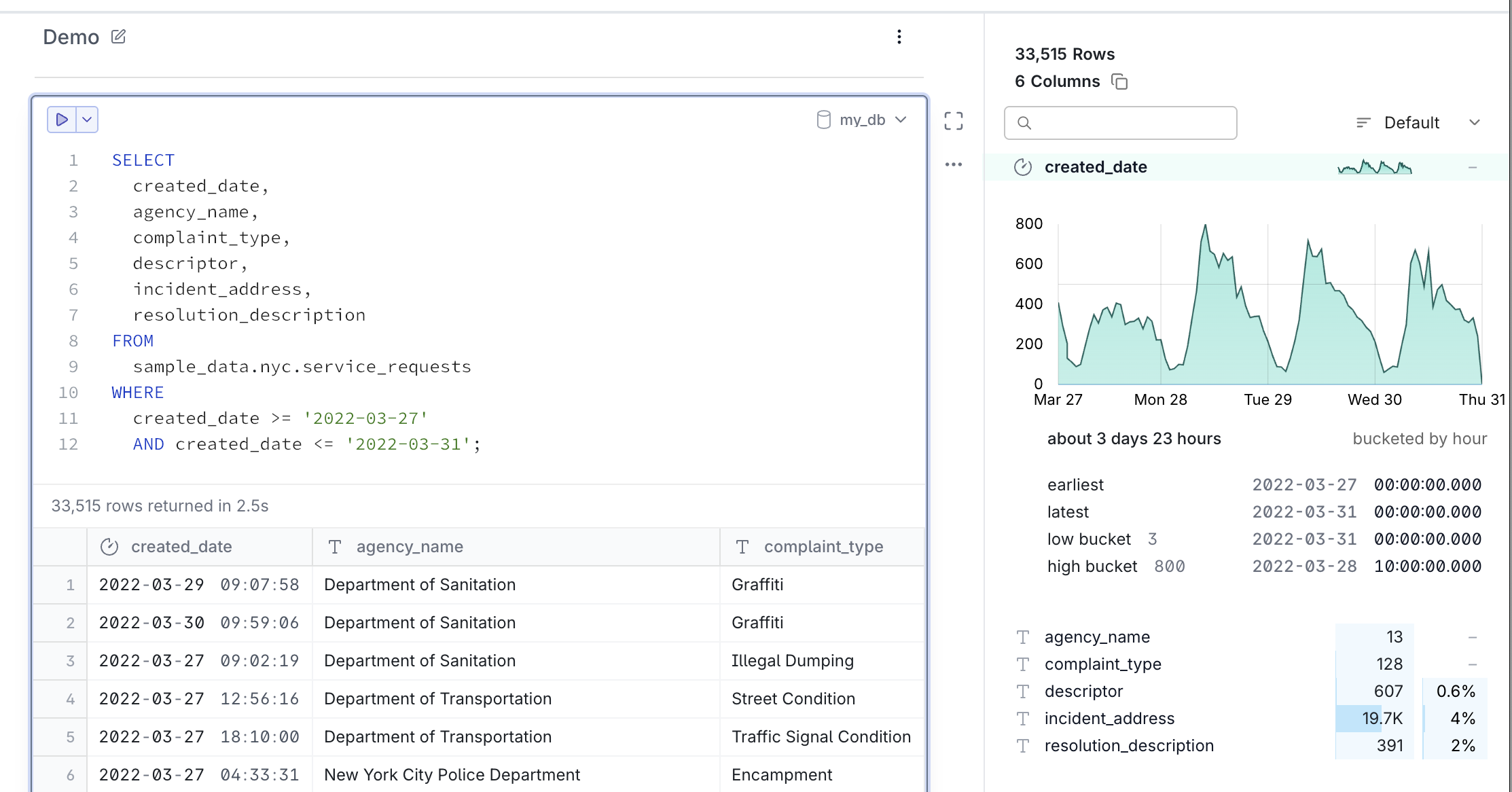
For the remainder of this tutorial, we'll focus on the NYC taxi data and perform aggregation queries representative of the types of queries often performed in analytics databases. We will first get the average fare based on the number of passengers. The source dataset covers data for the whole month of November 2022.
SELECT
passenger_count,
avg(total_amount)
FROM
sample_data.nyc.taxi
GROUP BY
passenger_count
ORDER BY
passenger_count;The sample_data database is auto-attached but for any other shared database you would like to read, you would need to use the ATTACH statement. Read more about querying shared MotherDuck databases.
Using a DuckDB client? You can run these same queries in any of the DuckDB client after connecting with ATTACH 'md:'; - you'll be prompted to authenticate if no motherduck_token is found as environment variable.
Query from S3
Our shared sample database is great to play with but you probably want to use your own data on AWS S3. Let's see how to do that.
The sample database source data is actually available on our public AWS S3 bucket. Let's run the exact same query but instead of pointing to a MotherDuck table, we will point to a parquet file on S3.
For a secured bucket, we need to pass the AWS credentials - check authenticating to S3 for more information.
Here's the updated query while reading from S3:
SELECT
passenger_count,
avg(total_amount)
FROM
's3://us-prd-motherduck-open-datasets/nyc_taxi/parquet/yellow_cab_nyc_2022_11.parquet'
GROUP BY
passenger_count
ORDER BY
passenger_count;DuckDB automatically detects the appropriate reader based on file extension, so there’s no need to explicitly specify a function. However, if you need more control over how files are read, you can use the corresponding functions directly:
SELECT * FROM read_parquet('my_data.parquet');
SELECT * FROM read_csv_auto('my_data.csv');
SELECT * FROM read_json_auto('my_data.json');
These functions allow you to customize parsing behavior or override automatic detection when needed.
Next Steps
Great! You've successfully run your first queries on MotherDuck. You've learned how to:
✅ Query shared databases like sample_data
✅ Read data directly from S3