Multithreading and parallelism
Depending on the needs of your data application, you can use multithreading for improved performance. If your queries will benefit from concurrency, you can create connections in multiple threads. For multiple long-lived connections to one or more databases in one or more MotherDuck accounts, you can use connection pooling.
Connections in multiple threads
If you have multiple parallelizable queries you want to run in quick succession, you could benefit from concurrency.
- Python
Concurrency is supported by DuckDB, across multiple Python threads, as described in the Multiple Python Threads documentation page. However, be mindful when using this approach, as parallelism does not always lead to better performance. Read the notes on Parallelism in the DuckDB documentation to understand the specific scenarios in which concurrent queries can be beneficial.
A single DuckDB connection is not thread-safe. To use multiple threads, pass the connection object to each thread, and create a copy of the connection with the .cursor() method to run a query:
import duckdb
from threading import Thread
duckdb_con = duckdb.connect('md:my_db')
def query_from_thread(duckdb_con, query):
cur = duckdb_con.cursor()
result = cur.execute(query).fetchall()
print(result)
cur.close()
queries = ["SELECT 42", "SELECT 'Hello World!'"]
threads = []
for i in range(len(queries)):
threads.append(Thread(target = query_from_thread,
args = (duckdb_con, query,),
name = 'query_' + str(i)))
for thread in threads:
thread.start()
for thread in threads:
thread.join()
Connection pooling
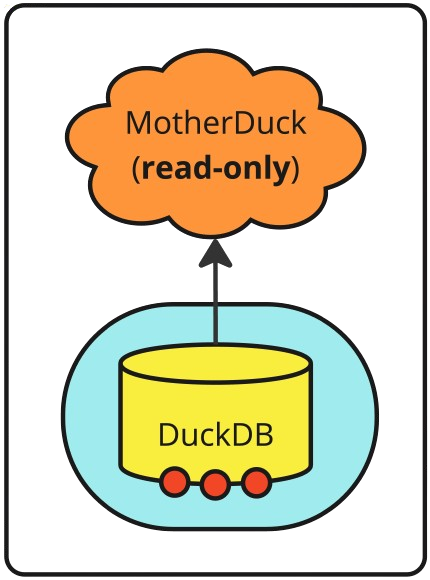
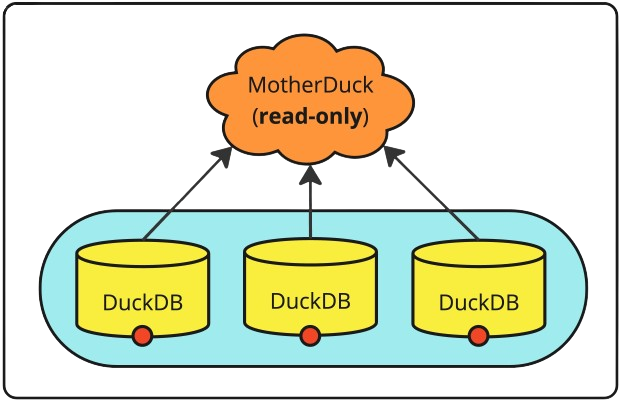
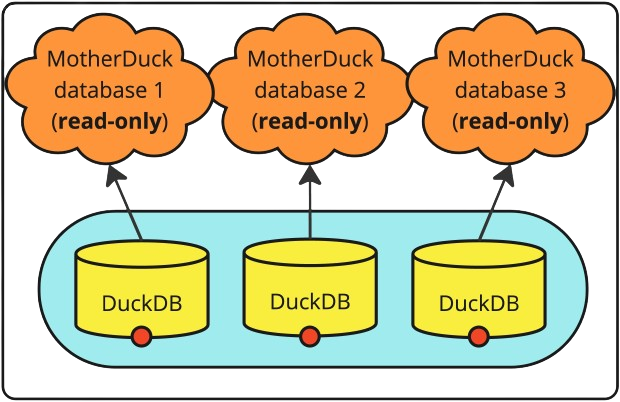
If your application needs multiple read-only connections to a MotherDuck database, for example, to handle requests in a queue, you can use a Connection Pool. A Connection Pool keeps connections open for a longer period for efficient re-use. The connections in your pool can connect to one database in the same MotherDuck account, or multiple databases in one or more accounts.
- Python
For connection pools, we recommend using SQLAlchemy. Below is an example implementation. For this implementation, you can connect to a user account by providing a motherduck_token in your database path.
import logging
from itertools import cycle
from threading import Lock
import duckdb
import sqlalchemy.pool as pool
from sqlalchemy.engine import make_url
_log = logging.getLogger(__name__)
logging.basicConfig(level=logging.DEBUG)
class DuckDBPool(pool.QueuePool):
"""Connection pool for DuckDB databases (MD or local).
When you run con = pool.connect(), it will return a cached copy of one of the
database connections in the pool.
When you run con.close(), it doesn't close the connection, it just
returns it to the pool.
Args:
database_paths: A list of unique databases to connect to.
"""
def __init__(
self,
database_paths,
max_overflow=0,
timeout=60,
reset_on_return=None,
*args,
**kwargs
):
self.database_paths = database_paths
self.gen_database_path = cycle(database_paths)
self.pool_size = kwargs.pop("pool_size", len(database_paths))
self.lock = Lock()
super().__init__(
self._next_conn,
*args,
max_overflow=max_overflow,
pool_size=self.pool_size,
reset_on_return=reset_on_return,
timeout=timeout,
**kwargs
)
def _next_conn(self):
with self.lock:
path = next(self.gen_database_path)
duckdb_conn = duckdb.connect(path)
url = make_url(f"duckdb:///{path}")
_log.debug(f"Connected to database: {url.database}")
return duckdb_conn
How to set database_paths
The DuckDBPool takes a list of database_paths and an optional input argument pool_size (defaults to the number of paths). Each path in the list will get a DuckDB connection in the pool, that readers can use to query the database(s) they connect to. If you have a pool_size that is larger than the number of paths, the pool will return thread-safe copies of those connections. This gives you a few options on how to configure the pool.
To learn more about database instances and connections, see Connect to multiple databases.
- One database
- One database with >1 instances
- >1 Databases on one account
- >1 Databases on >1 accounts
To create a connection pool with 3 connections to the same database, you can pass a single database path, and set pool_size=3:
path = "md:my_db?motherduck_token=<motherduck_token>&access_mode=read_only"
conn_pool = DuckDBPool([path], pool_size=3)
Set access_mode=read_only to avoid potential write conflicts. This is especially important if your pool_size is larger than the number of databases.
You can also create multiple connections to the same database using different DuckDB instances. However, keep in mind that each connection takes time to establish. Create multiple paths and make them unique by adding &user=<n> to the database path:
paths = [
"md:my_db?motherduck_token=<motherduck_token>&access_mode=read_only&user=1",
"md:my_db?motherduck_token=<motherduck_token>&access_mode=read_only&user=2",
"md:my_db?motherduck_token=<motherduck_token>&access_mode=read_only&user=3",
]
conn_pool = DuckDBPool(paths)
Set access_mode=read_only to avoid potential write conflicts. This is especially important if your pool_size is larger than the number of databases.
You can also create multiple connections to separate databases in the same MotherDuck account using different DuckDB instances. However, keep in mind that each connection takes time to establish. Create multiple paths where each uses a different database path:
paths = [
"md:my_db1?motherduck_token=<motherduck_token>&access_mode=read_only",
"md:my_db2?motherduck_token=<motherduck_token>&access_mode=read_only",
"md:my_db3?motherduck_token=<motherduck_token>&access_mode=read_only",
]
conn_pool = DuckDBPool(paths)
Set access_mode=read_only to avoid potential write conflicts. This is especially important if your pool_size is larger than the number of databases.
You can also create multiple connections to separate databases in separate MotherDuck accounts using different DuckDB instances. However, keep in mind that each connection takes time to establish. Create multiple paths where each uses a different database path:
paths = [
"md:my_db1?motherduck_token=<motherduck_token1>&access_mode=read_only",
"md:my_db2?motherduck_token=<motherduck_token2>&access_mode=read_only",
"md:my_db3?motherduck_token=<motherduck_token3>&access_mode=read_only",
]
conn_pool = DuckDBPool(paths)
Set access_mode=read_only to avoid potential write conflicts. This is especially important if your pool_size is larger than the number of databases.
How to run queries with a thread pool
You can then fetch connections from the pool, for example, to run queries from a queue. You can use a ThreadPoolExecutor with 3 workers to fetch connections from the pool and run the queries using a run_query function:
from concurrent.futures import ThreadPoolExecutor
def run_query(conn_pool: DuckDBPool, query: str):
_log.debug(f"Run query: {query}")
conn = conn_pool.connect()
rows = conn.execute(query)
res = rows.fetchall()
conn.close()
_log.debug(f"Done running query: {query}")
return res
with ThreadPoolExecutor(max_workers=3) as executor:
conn_pool = DuckDBPool(database_paths)
futures = [executor.submit(run_query, conn_pool, query) for query in queries]
for future, query in zip(futures, queries):
result = future.result()
print(f"Query [{query}] num rows: {len(result)}")
Reset the connection pool at least once every 24 hours, by closing and reopening all connections. This ensures that you are always running on the latest version of MotherDuck.
conn_pool.dispose()
conn_pool.recreate()