
2024/03/28 - Mehdi Ouazza
This Month in the DuckDB Ecosystem: March 2024
DuckDB news: Federated queries join PostgreSQL and blockchain data. PuppyGraph adds graph modeling on MotherDuck. End-to-end dbt pipelines. Co-creator Hannes interview.
Announcing Data Outpost - The conference for data people in a world being rebuilt by AINov 4-5 | San Francisco
- 7 min read
BY- 7 min read
BYDevelopers across every industry are increasingly embedding powerful insights directly into their applications using interactive, data-driven embedded analytics tools.
Data generated inside any application can help provide actionable insights, reduce costs, and increase operational efficiency. But that data must first be collected, processed, enriched, and centralized for consumption. Historically, this data may have existed in disparate systems or BI dashboards, requiring users to jump between applications to operationalize this valuable data. Using analytics components, this data is surfaced back into the application itself, reducing context-switching and empowering better decision-making.
While once considered nice-to-have features inside niche industries, analytics components now represent a powerful competitive advantage and are quickly becoming table stakes across enterprise and consumer applications alike. Whether powering embedded dashboards or serving as an analytics database for AI agents, all applications are becoming data applications.
Take, for example, an e-commerce application that wants to show merchants their stores’ sales by day and by state for the last 30 days to help them gain some directional awareness about their sales performance across the country.
We could run this query directly against the application’s transactional database, but we quickly realize transactional databases are not optimized for these sorts of Star Schema queries.
Copy code
select d.d_date as sale_date,
ca.ca_state as state,
sum(cs.cs_net_paid)as total_sales
from catalog_sales cs
inner join customer c
on c.c_customer_sk = cs.cs_ship_customer_sk
inner join customer_address ca
on ca.ca_address_sk = c.c_current_addr_sk
inner join date_dim d
on cs.cs_sold_date_sk = d.d_date_sk
where d.d_date between current_date - interval '30' day and current_date
and merchant_id = 'a3e4400'
group by d.d_date,
ca.ca_state
order by d.d_date,
ca.ca_state;
This query, which involves a modest sales table of just 40M records, will take over eight seconds on a decently sized machine! Today's end users won’t wait around for insights that take far too long to load. Worse yet, these types of queries can hog precious resources in our transactional database and may even disrupt critical operations like writing or updating records.
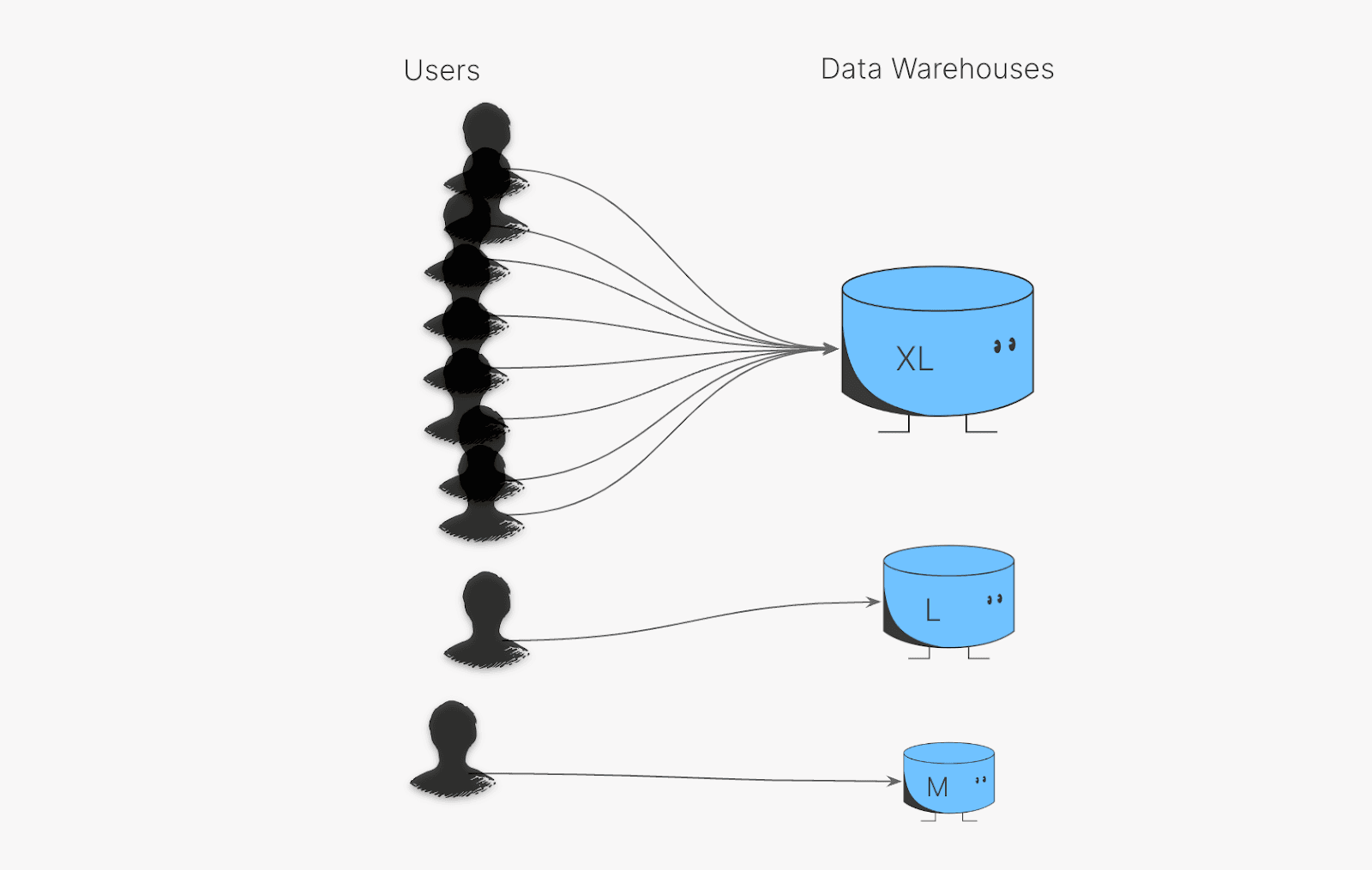
In an effort to decrease latency, we might move these queries over to a cloud data warehouse: after all, they’re optimized for analytics. This same query now takes about three seconds against a modern cloud data warehouse. But as we increase the number of concurrent queries, we start to see that even a well provisioned cloud data warehouse can only handle a few of these queries at once.
This latency and concurrency limit may be useable for an internal BI dashboard, but it won’t scale to hundreds or thousands of users who might be in an application at any given moment. Serving hundreds or thousands of concurrent users of a customer-facing analytics application with a cloud data warehouse requires serious engineering effort to balance concurrency, latency, and cost.
Delivering performance to users of all shapes and sizes likely requires routing some of them to dedicated, right-sized resources while bin-packing the rest in a large mainframe-like box, all while scaling these resources up and down to handle an influx in traffic. The operational overhead of managing this deployment at scale can quickly become cumbersome and expensive. Under-provisioning resources results in higher latency, and over-provisioning results in higher costs.At its core, slow query performance is a physics problem with a predictable hierarchy of bottlenecks that begins with inefficient data access.
Even after we optimize the way these queries are handled, developers still have to build an enormous amount of application code to power data-driven components. The client must encode a series of metrics, dimensions, and filters as a request to a server endpoint. The server handles this request by generating the equivalent SQL and executing the query against the data store, returning a serialized version of the data set. The client parses this response and passes the resulting data to the component for its initial rendering.
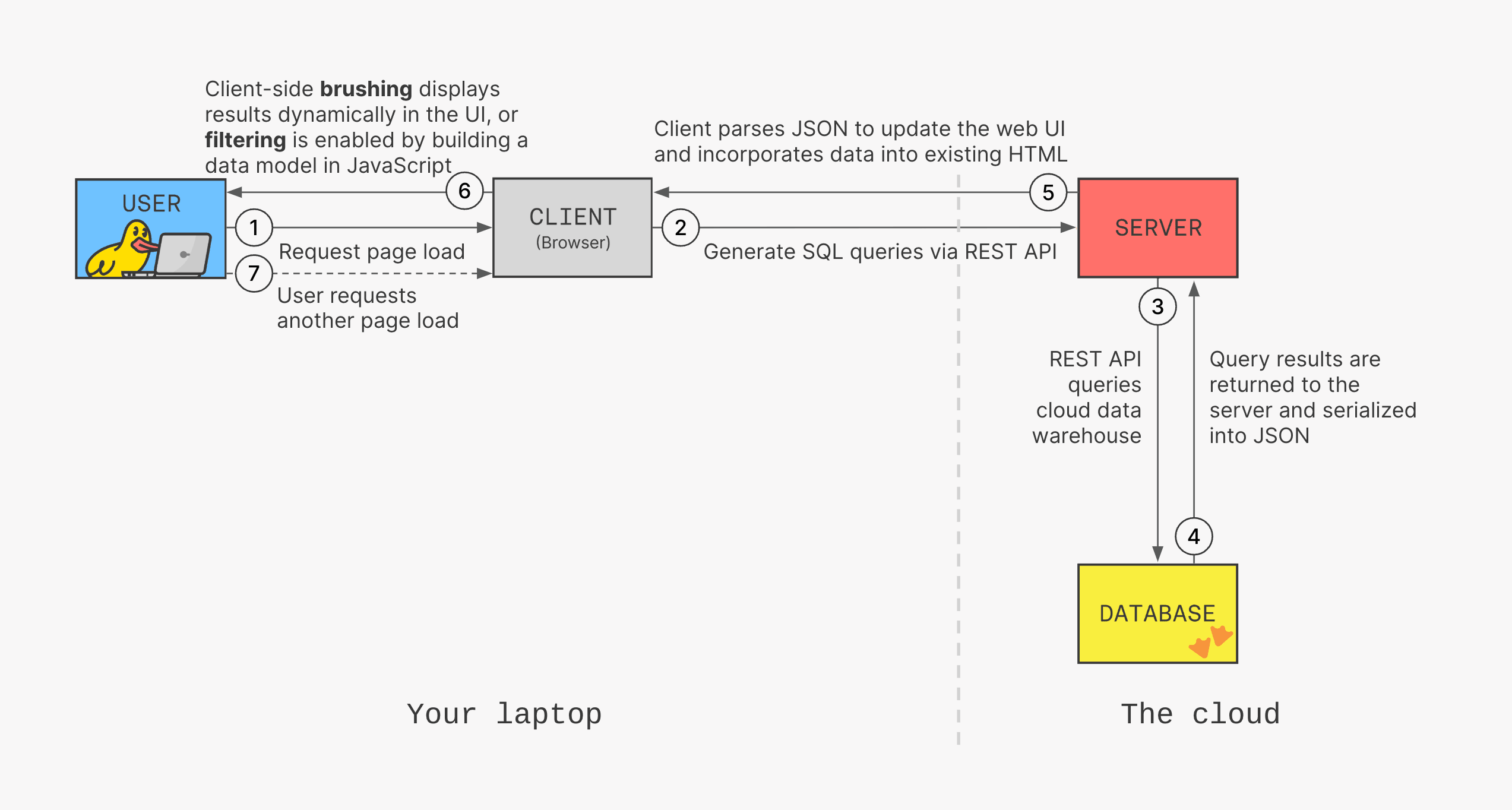
The interactive nature of these components means that users can typically manipulate the data by filtering or slicing and dicing it by different dimensions. Each interaction could potentially trigger another expensive, slow round-trip request to the server, often resulting in 5 to 10 seconds for a component to refresh. This latency might be acceptable in traditional BI dashboards but is often too slow for actionable insights in a data application.
In an effort to reduce the costly round-trip request on every interaction, developers will have to build a client-side data model that can efficiently apply transformations to the data set to prevent this request lifecycle from happening again. This requires duplicating a lot of the server's functionality, but often without a powerful SQL engine to apply these transformations.
While data-driven functionality has become table stakes, building data applications today is still an arduous effort for engineering teams. The resulting features are slow, brittle, and expensive to build and maintain.
What if you could deliver data applications capable of refreshing 60 times per second against large-scale data sets - faster than you can blink? What if you could make your dashboards as interactive as video games? What if you could run this workload for a fraction of what it would normally cost you, with fewer headaches? MotherDuck’s unique hybrid architecture is the future, and we invite you to join us in building the data applications of the future that haven't even been feasible until now!
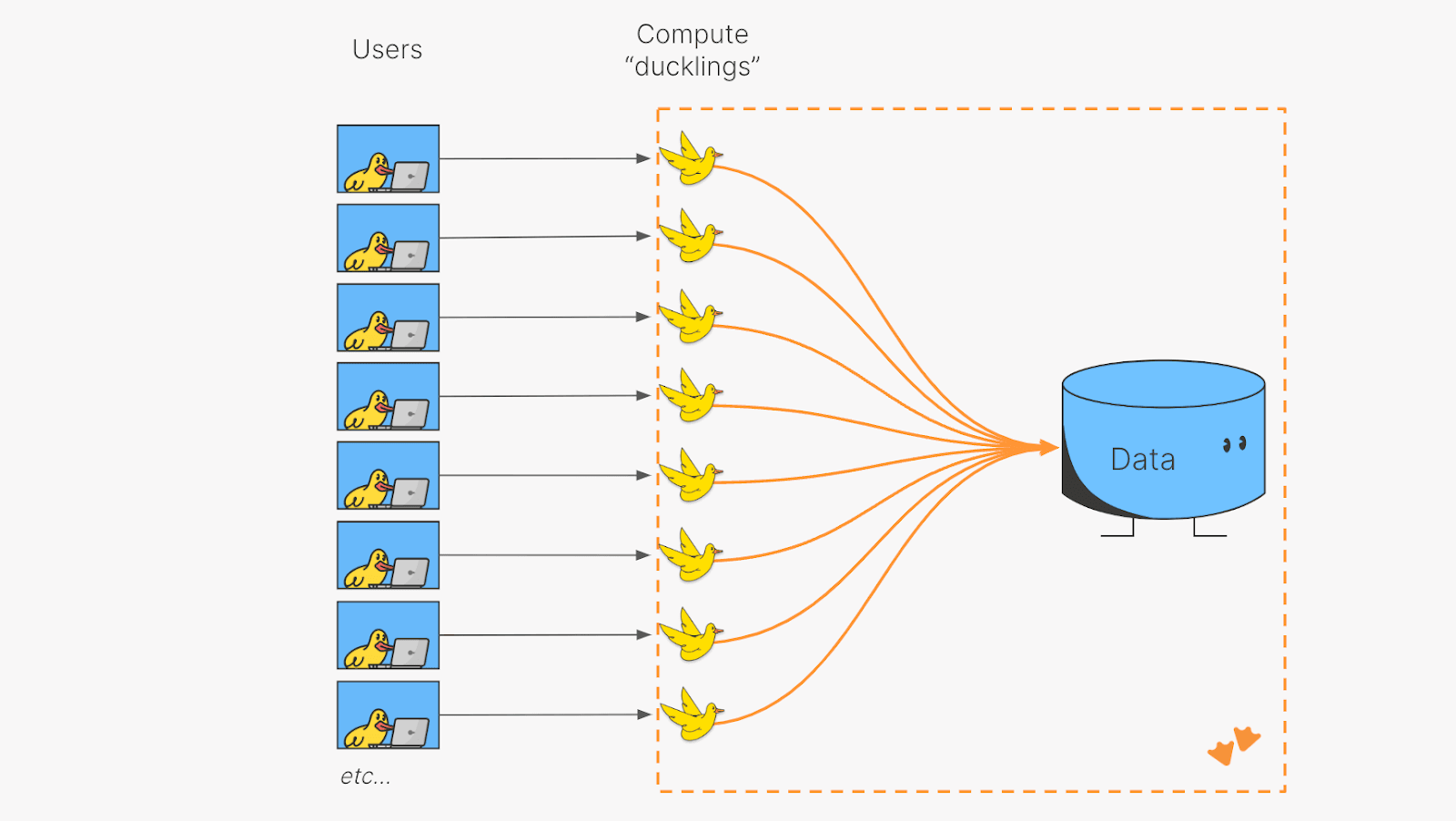
MotherDuck provides every user of a data application with their own vertically scaling instance of DuckDB, a fast, in-process analytical database, and executes queries against MotherDuck’s scalable, fully managed, and secure storage system that unifies structured and unstructured data.
Giving each user their own instance of DuckDB, or "duckling," allows complex analytics queries to be executed faster and more efficiently, with higher concurrency than traditional warehouses.
Further, MotherDuck only charges you for the seconds that any given user is querying data. Developers no longer have to worry about ensuring enough compute resources are available, if users are being routed to appropriately sized resources, or if under utilized resources are lingering around.
The MotherDuck Wasm SDK introduces game-changing performance and developer ergonomics for data applications. Just install the SDK, and suddenly your client speaks the lingua franca of analytics: SQL.
Copy code
import { MDConnection } from '@motherduck/wasm-client';
const conn = MDConnection.create({
mdToken: "...",
});
const result = await conn.evaluateStreamingQuery(`
select d.d_date as sale_date,
ca.ca_state as state,
sum(cs.cs_net_paid)as total_sales
from catalog_sales cs
inner join customer c
on c.c_customer_sk = cs.cs_ship_customer_sk
inner join customer_address ca
on ca.ca_address_sk = c.c_current_addr_sk
inner join date_dim d
on cs.cs_sold_date_sk = d.d_date_sk
where d.d_date between current_date - interval '30' day and current_date
and merchant_id = 'a3e4400'
group by d.d_date,
ca.ca_state
order by d.d_date,
ca.ca_state;
`);
A dual engine, hybrid execution model directly queries MotherDuck’s performant and secure infrastructure for large data sets while utilizing your powerful laptop to operate on local data. With MotherDuck's novel, Wasm-powered 1.5-tier architecture, DuckDB runs both in the browser and on the server, enabling components to load faster to deliver instantaneous filtering, aggregation, or slicing and dicing of your data.
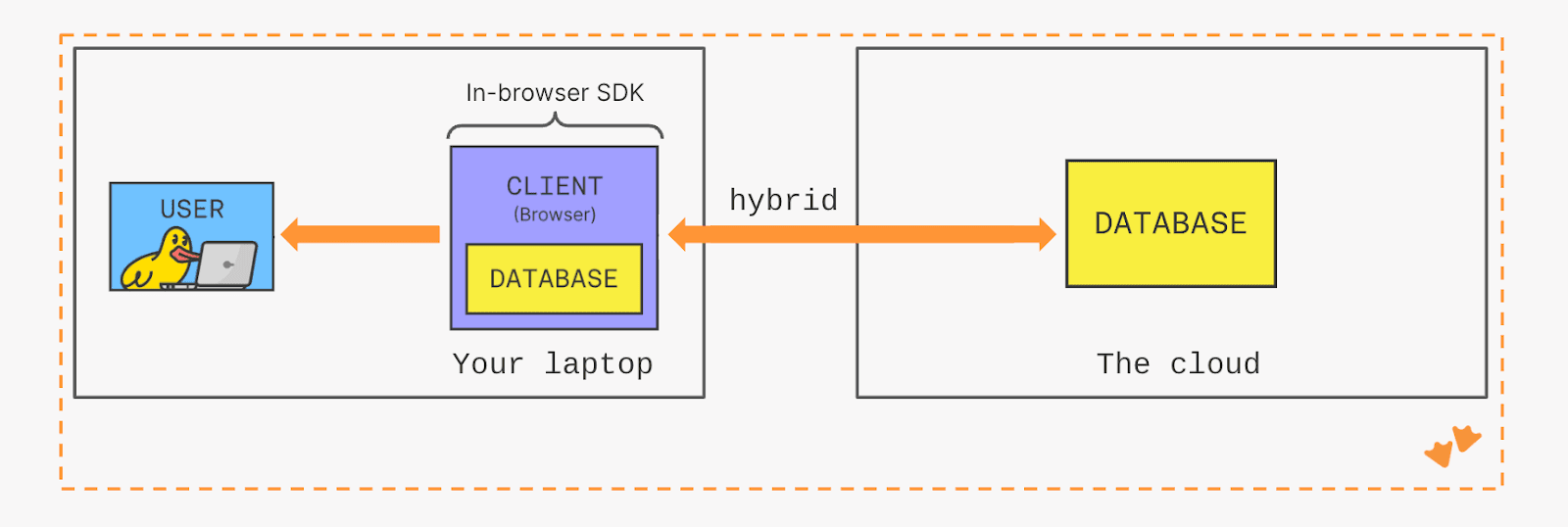
Current MotherDuck users can see the SDK in action by trying out the Column Explorer or viewing our interactive analytics demo. Refer to the documentation to learn how to retrieve a service token and view the demo.
To get started, head over to the docs. Feel free to share your feedback with us on Slack! If you’d like to discuss your use case in more detail, please connect with us - we’d love to learn more about what you’re building.
2024/03/28 - Mehdi Ouazza
DuckDB news: Federated queries join PostgreSQL and blockchain data. PuppyGraph adds graph modeling on MotherDuck. End-to-end dbt pipelines. Co-creator Hannes interview.

2024/04/19 - Adithya Krishnan
Discover the power of AI search by using vector embeddings in natural language processing in the first blog in our informative three-part series! We'll cover the basics of vector embeddings and cosine similarity using DuckDB and MotherDuck.