
2023/03/23 - Marcos Ortiz
This Month in the DuckDB Ecosystem: March 2023
DuckDB news: JSON extension queries nested data as tables. Spatial analysis runs on AWS Lambda. JupySQL enables large dataset plotting. Streamlit integration.
Greetings, Python enthusiasts! As you may know, PyCon is a global phenomenon that brings together the brightest minds in the Python programming world. Originating in the United States in 2003, this event has since spread its wings and now takes place in numerous countries across the globe. Each PyCon event showcases the latest developments, innovations, and trends in Python, all while fostering collaboration, networking, and learning within the community.
It's astounding to witness the numerous volunteers who contributed to organising the event. Even the person handing you your ticket might be a senior data engineer!
In this blog post, I’ll share my data engineering highlights from PyCon DE, where over 1,300 (plus 400 joining remotely) Python enthusiasts gathered to exchange ideas and share knowledge.

There were a lot of talks, workshops dedicated to Pandas and Polars. These two dataframes libraries are indeed in front of the data Python recently with some major new features.
This release was officially launched on April 3rd, and there was plenty to discuss.
Two major improvements that significantly increased efficiency include:
Apache Arrow is beginning to dominate the data world, providing a method to define data in memory. For Pandas, Arrow serves as an alternative data storage format. Being a columnar format, it interacts seamlessly with Parquet files, for example.
Even when discussing competitors libraries (more on that below), some people acknowledge that Arrow has resolved many issues.

Copy-on-write is a smart method for working with modifiable resources, like Pandas dataframes. Instead of making a copy of the data right away, Pandas simply refers to the original data and waits to create a new copy until it's really needed. This approach helps save memory and improves performance, all while avoiding unnecessary data copies.
Talks :
Polars is making waves as the new go-to library for fast data manipulation and analysis in Python. Built in Rust, its primary distinction lies in the performance features it brings to the table:
The lazy feature in Polars offers substantial performance and resource management benefits. Lazy evaluation, a technique where expressions or operations are delayed until explicitly requested, allows Polars to smartly optimize the execution plan and conduct multiple operations in a single pass.
However, it's worth noting that Polars may not fully replace Pandas in certain cases. The existing Python data ecosystem, built on Pandas over the years, remains robust, particularly for visualization.

What about DuckDB? To be honest, SQL isn't everyone's favorite language. It appears that many Python enthusiasts are not even aware of DuckDB's relational API. Despite this, you can maintain a Python-based workflow and take advantage of DuckDB's key features, such as extensions and file formats. Additionally, DuckDB is compatible with your existing dataframe libraries, thanks to Arrow.
Talks :
Fun that we get to hear more Rust at a Python conference. This is typical since Rust is incredibly powerful when developing Python keybindings. Many major Python data projects, such as Delta-rs (Delta lake Rust implementation), have Rust implementations. Pydantic and Polars work in a similar way, boosting Python performance by rewriting some core components in Rust while maintaining the beautiful simplicity of Python as the main interface.
Robin Raymond created a fantastic slides summary to demonstrate that even though Rust delivers excellent performance, writing better Python is also a viable option.
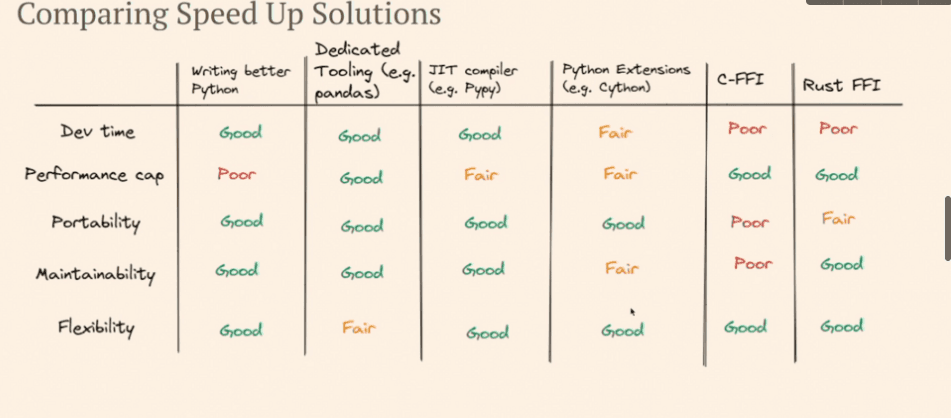
Talk :
I’ve been advocating for a long time about the confusion of data roles. Especially around data engineering.
In this talk, Noa Tamir covers the story about the data science role and how it has evolved.
What I found particularly interesting was the comparison between data science management and management in general, as well as with software engineering. If we recognise the differences, I believe we are one step further to get better at managing data science teams and project.
Talk : How Are We Managing? Data Teams Management IRL by Noa Tamir
My favorite keynote as I learned more about learned databases!
The speaker presented two intriguing techniques, data-driven learning and zero-shot learning, which address some of the limitations of current learned DBMS approaches.
Data-driven learning caught my attention as it learns data distributions over complex relational schemas without having to execute large workloads. This method is promising for tasks like cardinality estimation and approximate query processing. However, it has its limitations, which led the speaker to introduce zero-shot learning.

Talk :
PyCon talks are usually all available on YouTube, and I’ll be curious to catchup on some talks when the PyCon US releases them. I expect however to see the same trends on the data engineering side : Pandas & Polars wars, Arrow and Rust FTW.
May the data conference be with you.
2023/03/23 - Marcos Ortiz
DuckDB news: JSON extension queries nested data as tables. Spatial analysis runs on AWS Lambda. JupySQL enables large dataset plotting. Streamlit integration.

2023/04/17 - Marcos Ortiz
DuckDB news: Mode adopts DuckDB for visual data exploration. DataCamp Workspace adds SQL-first tool. LangChain Document Loader integration. dbt extension launches.