
2023/05/11 - Jordan Tigani
The Simple Joys of Scaling Up
Explores why scale-out became so dominant, whether those rationales still hold, and some joyful advantages of scale-up architecture.
Everybody knows that DuckDB quacks SQL. But how does it fit within a Python environment?
When talking to Python data folks at Pycon DE, it seems that there is a lot of confusion about what DuckDB can do with/versus Pandas and Polar libraries.
Looking online, you can see the same sentiment :


So where does DuckDB stand in the Python ecosystem? In this blog post, we will cover the main features of Pandas, Polars, and DuckDB and what each one brings to the table.
We will then cover a simple analytics use case using each of these frameworks to compare installation, syntax, performance, and versatility.
Oh, and if you are too lazy to read this, don’t worry, I also made a video about this topic.
People often associate the word “database” with something heavyweight. As Hadley Wickham, Chief Scientist @RStudio quoted :
If your data fits in memory, there’s no advantage to putting it in a database: it will only be slower and more frustrating
But what happens when your data doesn't fit in memory? This is where a hybrid analytics approach becomes powerful, blending the convenience of local tools with the scale of the cloud. The big difference with traditional OLAP databases is that DuckDB is an in-process database that can, within the python world, just be installed through a pip install.
DuckDB is fast. It contains a columnar-vectorized query execution engine, where queries are still interpreted, but a large batch of values (a “vector”) are processed in one operation.
DuckDB has a lot of built-in features or rather extensions, like JSON support, reading over AWS S3 , spatial data support, and so forth. These extensions are nice because it prevents you from thinking of what Python package you need for some action. These extensions add dependencies, but it’s really lightweight, and it’s not Python dependencies; they are downloaded and loaded directly in DuckDB.
Finally, DuckDB can query Apache Arrow datasets directly and stream query results back to Apache Arrow.
This is a neat feature that makes compatibility with the other framework seamless; more on that below.
If you are a Python developer and working with data, chances are high that you came across the Pandas library. The development of pandas integrated numerous features into Python that facilitated DataFrame manipulation, features that were previously found in the R programming language.
Released in 2008, this library has been maturing and adopted widely by the data community. It had a significant release in 2023, Pandas 2.0. Including support for Apache Arrow as its backend data.
Because it was one of the first to bring the dataframe concept in Python, it has been supported by many data visualization libraries like Seaborn, Plotly, Bokeh, ggplot and so forth.
Polars is fast. For multiple reasons.
It leverages Rust in the backend to multithread some parts of the process. It also uses Apache Arrow Columnar Format as the memory model.
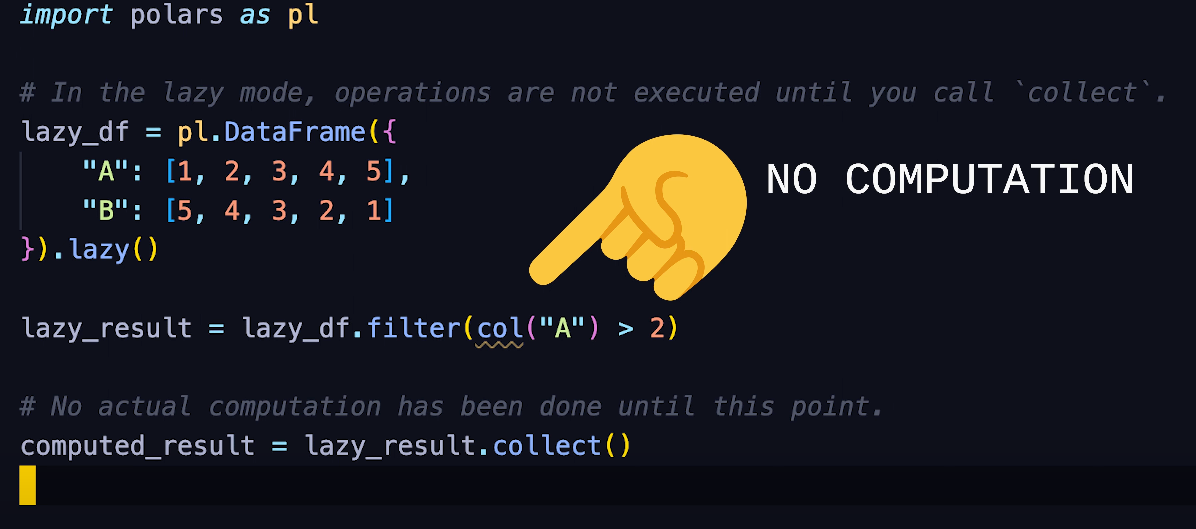
Next to that, it employs lazy evaluation to optimize query execution, which can result in faster operations, particularly when working with large datasets.
Lazy evaluation is a technique where certain operations or computations are delayed until they are absolutely necessary. So if you do filtering, ordering on your dataset, and using lazy Dataframe, these would not be executed until you do the call, which will prevent creating and store intermediate results in memory.
Here is a quick example of how this works.
It’s a newer library, which allows it to learn from the design decisions and limitations of Pandas, potentially leading to a more streamlined and efficient implementation.
We are going to cover a simple use case where we read data locally, do a couple of transformation and write the output dataset to AWS S3.
All the code and dataset are available on the GitHub repository.
For each framework, we have a dedicated subfolder (/duckdb, /pandas, /polars) with its own python dependencies requirements using poetry.
And because this needs to be fun, we are going to answer the following question : which website feed the most Hacker News ?
Hacker News, is essentially a chill hangout spot on the web where tech enthusiasts and entrepreneurial spirits share and engage in conversations around computer science, startups, and all things tech.
Our dataset contains Hacker News data from 2006 to 2022. It fits into 1 parquet file compressed of ~5 GB data and it’s about 33M rows.
All are Python libraries that can be installed through pip. That being said, both polars and pandas rely on other python dependencies for some extra features like read/write to AWS S3.
For DuckDB, that’s not the really the case as such features are covered by the built-in extensions.
Let’s have a look at the site-packages to give us an idea on how much space python dependencies are taking for each project. I’m linking for each one the pyproject.toml so that you can inspect what’s in it.
The difference is impressive, a few comments :
httpfs for reading/writing to S3), but we would still be around ~80M if we do so.pyarrow which is pretty large but also needed for read/writing to AWS S3Beyond conserving space in your build and container image, having fewer dependencies and less code can be beneficial in general. The less code you have, the fewer issues you'll encounter.
As we mentioned, DuckDB can be used outside Python. You have a CLI with SQL interface but also binding for Rust, Java, and even recently Swift, enabling DuckDB for mobile.
Polars outside Python and Rust has just released a CLI written in Rust to execute a couple of SQL action - I haven’t tried it and it’s still really early.
Pandas is sticked to Python but it has a wide range of data visualisation library supports like Bokeh, Seaborn, Plotly, etc.
However, due to Apache Arrow's flexible format and the fact that all these framework supports Arrow, they can easily integrate to each others with negligible performance cost and zero copy of the data.
For instance DuckDB can provide data as either a Pandas Dataframe :
Copy code
import pandas as pd
import duckdb
mydf = pd.DataFrame({'a' : [1, 2, 3]})
print(duckdb.query("SELECT SUM(a) FROM mydf").to_df())
Or as a Polars Dataframe :
Copy code
import duckdb
import polars as pl
df = duckdb.sql("""
SELECT 1 AS id, 'banana' AS fruit
UNION ALL
SELECT 2, 'apple'
UNION ALL
SELECT 3, 'mango'""").pl()
print(df)
In Polars, there’s a built-in command to convert to a pandas dataframe
Copy code
import pandas
import polars as pl
df1 = pl.DataFrame(
{
"foo": [1, 2, 3],
"bar": [6, 7, 8],
"ham": ["a", "b", "c"],
}
)
pandas_df1 = df1.to_pandas()
DuckDB is built on SQL. So you can do everything using that. That being said, there’s a relational API for a couple of methods to have a more pythonist approach.
Going back to our initial use case, here’s how we would do it using DuckDB. We extract the domain url from a post on Hacker News. We are doing some regex, and count the appearance using a groupby :
Copy code
# Using DuckDB
def extract_top_domain(conn: DuckDBPyConnection):
top_domains = (
conn.view("hacker_news")
.filter("url is NOT NULL")
.project("regexp_extract(url, 'http[s]?://([^/]+)/', 1) AS domain")
.filter("domain <> ''")
.aggregate("COUNT(domain) AS count, domain", "domain")
.order("count DESC")
.limit(20)
)
# Register the result DataFrame as a new table
conn.register("top_domains", top_domains)
The above code is using the Python Relational API, and looks quite similar to what we’ll see in Pandas and Polars, but note that you can do everything in SQL :
Copy code
# Using DuckDB SQL
def extract_top_domain_sql(conn: DuckDBPyConnection):
""" Equivalent of extract_top_domain but using pure SQL"""
conn.sql(
"""CREATE TABLE top_domains AS
SELECT regexp_extract(url, 'http[s]?://([^/]+)/', 1) AS domain,
COUNT(*) AS count
FROM hacker_news
WHERE url IS NOT NULL AND regexp_extract(url, 'http[s]?://([^/]+)/', 1) <> ''
GROUP BY domain
ORDER BY count DESC
LIMIT 20;
"""
)
Pandas doesn’t have a SQL interface, and it’s more Dataframe style :
Copy code
# Using Pandas
def extract_top_domains(df:pd.DataFrame)->pd.DataFrame:
return (
df.loc[df["url"].notna()]
.assign(
domain=df["url"].apply(
lambda x: re.findall(r"http[s]?://([^/]+)/", x)[0]
if x and re.findall(r"http[s]?://([^/]+)/", x)
else ""
)
)
.query('domain != ""')
.groupby("domain")
.size()
.reset_index(name="count")
.sort_values("count", ascending=False)
.head(20)
)
You can query Pandas with SQL using other python package, or… DuckDB as we saw in the snippet above.
Polars while being also a Dataframe oriented library do have a SQL interface released recently. So you can also combine both.
Here’s the same function using Polars :
Copy code
# Using Polars
def extract_top_domains(df: LazyFrame) -> DataFrame:
return (
df.filter(pl.col("url").is_not_null())
.with_columns(pl.col("url").str.extract(r"http[s]?://([^/]+)/").alias("domain"))
.filter(pl.col("domain") != "")
.groupby("domain")
.agg(pl.count("domain").alias("count"))
.sort("count", descending=True)
.slice(0, 20)
.collect()
)
Here the time each script took when running on my Macbook Pro m1 with 16GB of RAM :
2.3s3.3sA few comments :
Here is the top result of the website feeding Hacker News. Most of the links come out from Medium and GitHub. Which makes sense as it’s mostly a tech news website.
Copy code
| count int64 | domain varchar |
|-------------|------------------------|
| 132335 | github.com |
| 116877 | medium.com |
| 99232 | www.youtube.com |
| 62805 | www.nytimes.com |
| 47283 | techcrunch.com |
| 38042 | en.wikipedia.org |
| 36692 | arstechnica.com |
| 34258 | twitter.com |
| 30968 | www.theguardian.com |
| 28548 | www.bloomberg.com |
| 26010 | www.theverge.com |
| 23574 | www.wired.com |
| 20638 | www.bbc.com |
| 18541 | www.wsj.com |
| 18237 | www.bbc.co.uk |
| 17777 | www.washingtonpost.com |
| 15979 | www.theatlantic.com |
Here are a recap of our experiment.

DuckDB is way more versatile than Polars or Pandas. The reason is that the scope of DuckDB is just bigger, it’s a full OLAP database and it has different Client APIS.
Through our specific use case with Hacker News, we found that DuckDB was indeed faster, putting polars in #2 and Pandas wasn’t able to get it through.
We also discussed that thanks to Apache Arrow, we can actually use one or more of these framework together as we can easily convert back and forth the Dataframes with little to no performance degradation.
And that’s the best part. You can leverage the best of each framework depending on your use case without locking down yourself too much.
Keep quacking, keep coding.
2023/05/11 - Jordan Tigani
Explores why scale-out became so dominant, whether those rationales still hold, and some joyful advantages of scale-up architecture.

2023/05/24 - Marcos Ortiz
DuckDB news: v0.8.0 brings Pivot/Unpivot and time series joins. Project hits 10,000 GitHub stars. Spatial extension and native Swift API launch.