Quack Notes
Often you will have spreadsheets that you want to mash up with other spreadsheets, or data in your database, or some random files on your desktop. With MotherDuck, you can easily handle all of these scenarios. In this series of post, you will learn how to read from Google Sheets in two ways: (1) with publicly-shared sheets and (2) with private sheets.
Publicly-Shared Sheets
For Google Sheets that are shared with a public link, extracting the sheet data is as simple as using the read_csv function and passing the URL. There are two things to note here - you will want to make sure to set the format as ‘csv’ and the gid as the tab that you want to load.
Copy code
FROM read_csv('https://docs.google.com/spreadsheets/d/{sheet_id}/export?format=csv&gid={tab_id}')
As a practical example, you can extract the sheet id and tab id from the URL, as seen in the screenshot below.
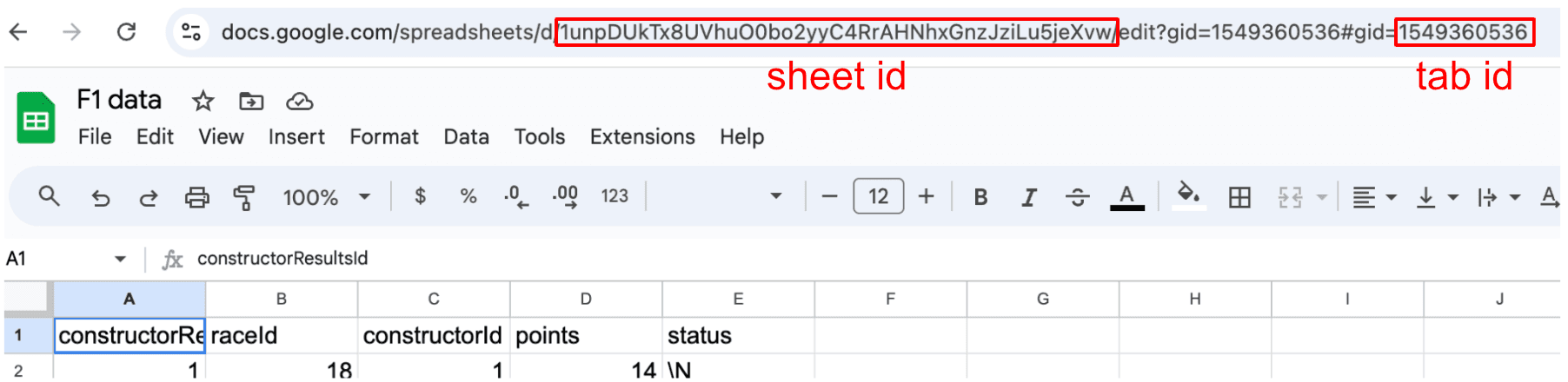
I have loaded some F1 data from kaggle into a Google Sheet and made the link public. This Google Sheet has id '1unpDUkTx8UVhuO0bo2yyC4RrAHNhxGnzJziLu5jeXvw' with the following tabs:
Depending on the use case, we can use either views or tables. If you want to keep things in sync with the spreadsheet, a view will work best. If you want to do more complex analysis, materializing as a table (or a temp table for this session) are great ideas for better performance.
The code example below creates the destination schema and then loads the data into MotherDuck:
Copy code
CREATE SCHEMA IF NOT EXISTS f1;
CREATE OR REPLACE TABLE f1.races AS
FROM read_csv('https://docs.google.com/spreadsheets/d/1unpDUkTx8UVhuO0bo2yyC4RrAHNhxGnzJziLu5jeXvw/export?format=csv&gid=2031195234');
CREATE OR REPLACE TABLE f1.constructors AS
FROM read_csv('https://docs.google.com/spreadsheets/d/1unpDUkTx8UVhuO0bo2yyC4RrAHNhxGnzJziLu5jeXvw/export?format=csv&gid=0');
CREATE OR REPLACE TABLE f1.constructor_results AS
FROM read_csv('https://docs.google.com/spreadsheets/d/1unpDUkTx8UVhuO0bo2yyC4RrAHNhxGnzJziLu5jeXvw/export?format=csv&gid=1549360536');
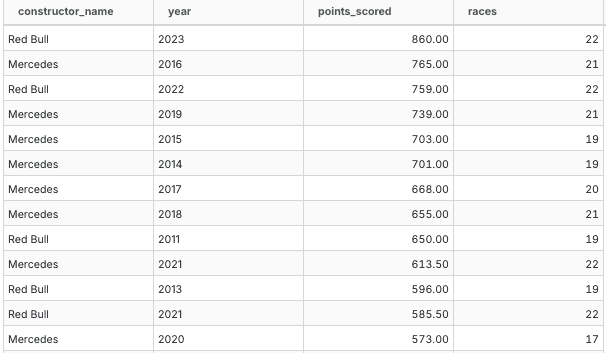
This allows easy subsequent analysis, for example, identifying the top scoring teams in the constructors championship each year.
Copy code
SELECT
c."name" as constructor_name,
r.year::text as year,
sum(cr.points) as points_scored,
count(*) as races
FROM f1.constructor_results cr
LEFT JOIN f1.races r on r.raceid = cr.raceid
LEFT JOIN f1.constructors c on c.constructorid = cr.constructorid
GROUP BY ALL
HAVING points_scored > 0
ORDER BY points_scored desc
Private Sheets
In order to load private sheets into MotherDuck, we need to handle Google Authentication. This is a complex topic, so I'll leave the details to this tutorial by Saturn Cloud.
The high-level overview is that you need to do the following:
- Create a Service Account in Google Cloud
- Create an Access Token for that Service Account
- Add the Service Account as user with access to your Google Sheet
- Create an Access Token for MotherDuck
That being said, importing a table into MotherDuck is simple as this bit of code. It should be noted this assumes that you store your Tokens in your .env file.
Copy code
import pandas as pd
from google.oauth2 import service_account
from googleapiclient.discovery import build
import duckdb
import os
import json
# create & load creds
creds_dict = json.loads(os.getenv('GOOGLE_CREDENTIALS_JSON'))
creds = service_account.Credentials.from_service_account_info(
creds_dict,
scopes=['https://www.googleapis.com/auth/spreadsheets.readonly']
)
# create the service
service = build('sheets', 'v4', credentials=creds)
sheet = service.spreadsheets()
# note that we use literal tab name instead of gid
result = sheet.values().get(spreadsheetId='1unpDUkTx8UVhuO0bo2yyC4RrAHNhxGnzJziLu5jeXvw', range = 'Constructors').execute()
# create the df with the column headers based on the values in the first row of the sheet
df = pd.DataFrame(result.get('values', [])[1:], columns=result.get('values', [])[0])
# create a duck connection
con = duckdb.connect(database='md:my_db?motherduck_token=' + os.getenv('MOTHERDUCK_TOKEN'))
# create a table
con.query("create or replace table main.google_sheets as select * from df")
You will note that in this case that tables, not views, are used - because python runtime is outside of MotherDuck, views are not possible, as they will reference objects that the user's scope will not have access to.
Getting started with MotherDuck
Try out MotherDuck for free, explore our integrations like the one with Google Sheets, and keep coding and quacking!
Start using MotherDuck now!
PREVIOUS POSTS

2024/08/29 - Sheila Sitaram
Small Data SF: The Agenda is now live…with *NEW* hands-on workshops
We had such an awesome response to Small Data SF after launch: It was so great that we decided to add an additional day of hands-on workshops! Learn more about the full lineup on 9/23 - 9/24 and grab a ticket before it's too late.
