Ed. note: This blog post is a recap of the dbt+MotherDuck workshop at Small Data SF. For event info and to learn about the next one, hit the website.
Quick Summary
In this blog, we will hit on the learnings and unique bits of kit that are a part of DuckDB & MotherDuck to build performant data pipelines in dbt. The final github repository can be found here. This article is not introductory level, and assumes that you have some experience with dbt.
The key bits, in order of DAG execution:
- the read_blob() function
- pre_hooks & variables + array_agg()
- incremental models & read_csv()
- unnest() + arg_max()
The goal of this exercise is to read a list of files, and then update the dbt models based on this list. The rough data flow looks like this:
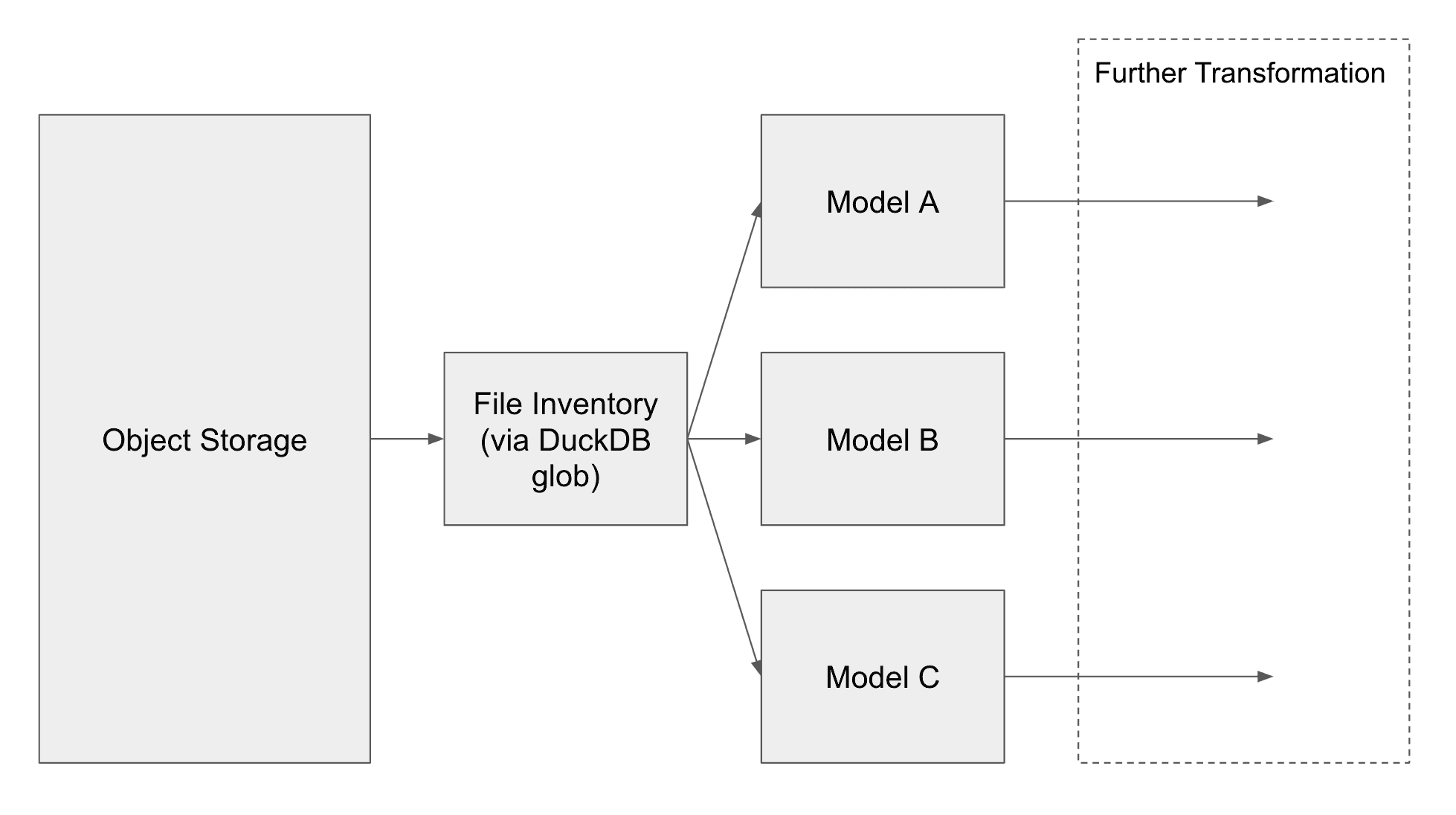
In order to build a pipeline that can run on top of our data lake, we need to understand what file operations are available in MotherDuck and how to utilize them best inside of a dbt pipeline.
The read_blob function
Read Blob is the first function required to make this pipeline work. It takes a path as a parameter and returns a table with filenames, file size, schema, and last modified date. To assure that other files do not randomly get inserted into our pipeline while it is running, we are going to materialize this as a table and use it as the starting point for the pipeline.
Copy code
select
"filename" as "file",
regexp_extract("filename", 'data/(.+?)_\d+\.csv', 1) as entity,
last_modified as modified_ts
from read_blob('data/*.csv')
In this example, DuckDB is inspecting local data. But DuckDB also includes capabilities to interact with Object Stores, which means this functionality can easily be extended to data lakes.
Pre-hooks & variables + array_agg
The next set of models will be broken into two parts - the pre-hook and then the incremental mode. First we will discuss the pre-hook, which leverages a new concept in Duckdb 1.1, variables. Variables allow us to insert arbitrary values into them with the set variable command and then pass arbitrary values into sql queries with getvariable(). Variables only support scalar values, but since DuckDB supports structs (that is - custom data structures), those can also be used with variables. DuckDB also contains a sets of functions to handle structs, like array_agg() which is used to turn a table column into a list.
These concepts can be used together like the example below.
Copy code
{{
config(
pre_hook="""
set variable my_list = (
select array_agg(file)
from {{ ref('files') }}
where entity = 'ticker_info'
)
""",
materialized="incremental",
unique_key="id",
)
}}
Incremental models & read_csv
dbt has the notion of “Incremental Materializations” - models that are handled in a different flow and require more explicit definition, and thus can be built incrementally. These models usually require a unique_key, if no key is provided, the model is treated as “append only”.
Furthermore, incremental models must define which pieces of the model run incrementally.
When invoked in normal dbt build or dbt run, incremental models will do the following:
- Insert new data into a temp table based on the defined increment.
- Delete any data from the existing model that matches the unique_key defined in the config block.
- Insert data from the temp table into the existing model.
This obviously means that changes to the schema of your model need to be carefully considered - new columns mean that the model must be rebuilt entirely. A rebuild of the model is called a “full refresh” in dbt can be invoked with the full-refresh flag in the CLI.
As described in the pre_hook, the variable my_list contains a list of files to process, and the config block also contains the relevant information for the model type and key.
Copy code
select
info.symbol || '-' || info.filename as id,
info.*,
files.modified_ts,
now() at time zone 'UTC' as updated_ts
from read_csv(getvariable('my_list'), filename = true, union_by_name = true) as info
left join {{ ref("files") }} as files on info.filename = files.file
{% if is_incremental() %}
where not exists (select 1 from {{ this }} ck where ck.filename = info.filename)
{% endif %}
This also introduces the concept of {{ this }}, which is a dbt relation and is a reference to the current model.
Unnest + arg_max
In any data warehouse, the presence of duplicate data is almost inevitable. This can occur due to various reasons, but that doesn’t make it any less painful.
- Data Integration: When combining data from multiple sources, inconsistencies and overlaps can lead to duplicates.
- REST API sources: Many data sources don’t allow for incremental updates, which means that every time you get new data, it difficult or impossible to handle it with creating duplicates.
In order to handle de-duplication in the dbt models, we can use arg_max() and unnest(). Arg_max() allows users to pass a table reference and a numeric column (including dates & timestamps) and returns a single row as a struct. Since it returns this data type, unnest() is used in order to get a single row from the arg_max() function.
Copy code
with
cte_all_rows as (
select
symbol,
* exclude(id, symbol),
modified_ts as ts
from {{ ref("company_info") }}
)
select unnest(arg_max(cte_all_rows, ts))
from cte_all_rows
group by symbol
As an aside - why use arg_max() instead of a window function? The short answer is that arg_max() uses Radix sort, which leverages SQL group by to identify the groups in which to find the max. The time complexity of Radix sort is O (n k), whereas comparison- based sorting algorithms have O (n log n) time complexity.
Closing Thoughts
In conclusion, dbt and MotherDuck together offer a powerful framework for efficient data transformations and analysis. By leveraging tools like read_blob() for data ingestion, utilizing pre_hooks and variables to streamline logic with functions like array_agg(), and implementing incremental models with read_csv() for optimal performance, you can significantly enhance your data workflows. Additionally, advanced techniques like unnest() combined with arg_max() allow for more sophisticated data manipulation, unlocking even greater efficiency in your analyses. When used effectively, dbt & motherduck can transform your approach to data, enabling both speed and accuracy in your Star Schema models. A working demo & instruction that can be found in this github repo. Good luck and happy quacking!
Start using MotherDuck now!
PREVIOUS POSTS

2024/10/01 - Jerel Navarrete
MotherDuck at Coalesce 2024: Your Ultimate Guide to Quack-tastic Fun!
Get ready to make a splash at Coalesce 2024! 🦆 MotherDuck is bringing the fun to Las Vegas, and we can't wait to see you there. Whether you're a seasoned Coalesce pro or a first-timer, we've got everything you need to make this year's event unforgettable.
