DuckDB Wasm : What Happens When You Put a Database in Your Browser?
2024/06/19 - 7 min read
BYWebAssembly (Wasm) has transformed the capabilities of browsers, enabling high-performance applications without needing anything beyond the browser itself. DuckDB, which can also run in browsers via Wasm, is often referred to as DuckDB Wasm, and it opens up numerous possibilities. In this blog, we'll explore various use cases of DuckDB Wasm and introduce a fun, practical example that you can try yourself, complete with source code.
Why Wasm?
Wasm is a powerful tool that is gaining traction in web development. Popular applications like Figma use Wasm to run complex software written in languages such as C++ or Rust directly in the browser. This allows for fast, lightweight applications that are easy to deploy. As browsers become more capable, even utilizing WebGPU to harness GPU power directly, possibilities such as training machine learning models locally on your machine via a browser link are becoming feasible, eliminating setup hassles.
The key benefit for databases like DuckDB is performing complex analytical queries directly on client-side data, drastically reducing network latency and backend infrastructure needs. Think about the implications: complex data analysis that traditionally required sending data to a server can now happen client-side, leading to faster, more responsive applications, reduced server costs, and enhanced data privacy as sensitive information doesn't need to leave the user's device.
An exciting project in the Wasm ecosystem is pyodide, which ports CPython to WebAssembly, offering a full Python environment in your browser just from a URL, minimizing reliance on cloud resources. Check out the pyodide REPL here.
Current Uses of DuckDB Wasm
DuckDB, being a C++ written, embedded database, is ideal for Wasm. It has been compiled to WebAssembly, allowing DuckDB Wasm to operate inside any browser. You can experience this here by running DuckDB directly in your browser.
DuckDB Wasm is particularly useful in user interfaces requiring lightweight analytic operations, reducing network traffic. Its capability to process data locally minimizes network overhead and enables rich, interactive experiences.
Here are some common scenarios where DuckDB Wasm shines:
Ad-hoc queries on data lakes such as schema exploration or data previews. You can easily explore the schema of files like Parquet, CSV, or JSON stored in cloud storage directly from your browser, or preview data samples without downloading entire datasets.
Dynamic querying in dashboards by adjusting filters on-the-fly. Power interactive dashboards where filtering, aggregation, and other data manipulations happen instantly in the browser as users interact with controls, providing a much smoother user experience compared to round trips to a server for every change.
Educational tools for SQL learning or in-browser SQL IDEs. Create self-contained environments for users to practice and experiment with SQL and data analysis.
Additional emerging applications include client-side data transformation, offline analytical tools, and integrating with the Origin Private File System (OPFS) for high-performance, persistent client-side storage. DuckDB Wasm can even act as a compute engine for simple data pipelines directly within the browser for smaller to medium-sized datasets.
For example, lakeFS has integrated DuckDB Wasm for ad-hoc queries within their Web UI. Similarly, companies like Evidence and Count leverage DuckDB Wasm to enhance performance.
 Running DuckDB, embedded in the lakeFS UI
Running DuckDB, embedded in the lakeFS UI
 Universal SQL Architecture from Evidence: Data -> Storage -> DuckDB Wasm -> Components
Universal SQL Architecture from Evidence: Data -> Storage -> DuckDB Wasm -> Components
DuckDB Wasm as a Firefox extension
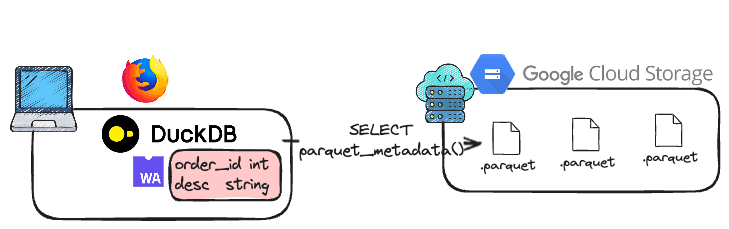
It's pretty common when navigating to object storage (whether it's AWS S3, GCP Cloud Storage, or Azure blob storage), that you want to quickly inspect a file or its schema, whether for debugging or quickly previewing a sample of data. This is a perfect use case where DuckDB Wasm can eliminate the need for a backend service or downloading entire files.
In this small project, we have created a Firefox extension that displays the schema of Parquet files when you hover your mouse over them in GCP Cloud Storage. Here's a short video demo.
The internals are pretty simple - with DuckDB Wasm, we can run directly a query on the client side, which does a query of the remote parquet file, and display its metadata. The architecture is straightforward: the Firefox extension, running in the browser, uses DuckDB Wasm to directly query the remote Parquet file's metadata when a link is hovered.
Let's get a grasp of the main components of the Firefox extension code, written in Javascript.
We instantiate the database in a web worker to avoid blocking the main browser thread:
Copy code
// Function to create and initialize the DuckDB database within a worker.
async function makeDB() {
const logger = new duckdb.ConsoleLogger();
// Create a worker for DuckDB Wasm
const worker = await duckdb.createWorker(bundle.mainWorker);
// Create an asynchronous database instance
const db = new duckdb.AsyncDuckDB(logger, worker);
// Instantiate the database
await db.instantiate(bundle.mainModule);
return db
}
Create a function to handle query results:
Copy code
async function query(sql) {
// Execute the SQL query
const q = await conn.query(sql);
// Convert the result to an array of objects
const rows = q.toArray().map(Object.fromEntries);
// Extract column names from the schema
rows.columns = q.schema.fields.map((d) => d.name);
return rows;
}
And finally a function to handle hover events that extracts the file path and uses DuckDB Wasm's parquet_metadata() function to query the schema without reading the entire file:
Copy code
async function hover(request, sender, sendResponse) {
// Extracting the file from the request
const fileName = request['filename'];
// Extracting the URL from the sender (assuming it's provided)
const url = sender.url;
// Parsing the URL to extract the bucket name
// Assuming the URL format is like "https://console.cloud.google.com/storage/browser/[BUCKET_NAME];..."
const bucketName = url.split('/storage/browser/')[1].split(';')[0];
// Constructing the s3 file path for DuckDB Wasm to access
const filePath = `s3://${bucketName}/${fileName}`;
console.log(filePath);
// Use parquet_metadata() to get the schema efficiently
const schema = await query(`SELECT path_in_schema AS column_name, type FROM parquet_metadata('${filePath}');`);
return Promise.resolve({ schema });
}
As you can see, we are using the parquet_metadata() function to retrieve parquet schema here, powered by DuckDB Wasm. The parquet_metadata() function is particularly useful here as it avoids the need to download the entire Parquet file, significantly improving performance and reducing data transfer. You can find the full SQL reference for the Wasm client in our documentation.
After that what is left is to define the handler and the panel displayed. You can check out the full code here. Check out the complete extension code here, and watch our full livestream with Christophe Blefari discussing DuckDB Wasm and this project.
What about MotherDuck?
The MotherDuck UI uses DuckDB Wasm to ensure responsive querying, especially when manipulating data already loaded locally. This means there is no need to communicate with the cloud, and both data and computing remain on your local machine. When data is already loaded locally, queries are processed directly in the browser via DuckDB Wasm, eliminating the need for cloud communication.
We've also launched our Wasm SDK to enable developers to create data-driven applications using Wasm, powered by DuckDB and MotherDuck. This forms a "1.5-tier architecture" where some processing happens client-side and some in the cloud, offering the best of both worlds.
Moving forward
In this blog, we've seen how Wasm is already reshaping popular web applications. DuckDB Wasm offers a unique opportunity for data professionals to build faster and more efficient analytics applications directly within the browser.
The ability to perform complex SQL queries directly in the browser on various data formats, coupled with features like persistent storage via OPFS and efficient metadata inspection, makes DuckDB Wasm a valuable tool for a wide range of use cases. As Wasm continues to evolve, we can expect even more sophisticated data applications to emerge that run seamlessly in the browser.
Try out MotherDuck for free, explore our Wasm SDK, and keep coding and quacking!
Start using MotherDuck now!

