PostgreSQL and Ducks: The Perfect Analytical Pairing
2025/06/16 - 10 min read
BYPostgreSQL's row-oriented storage and MVCC design make it perfect for transactional workloads. Those same features become liabilities when you're scanning terabytes for analytical queries. The result: degraded performance for both your analytics and your production applications—a lose-lose scenario that forces difficult architectural decisions as you hit the "Postgres wall".
The good news? You don't need to waddle through a complex data warehouse setup or build elaborate ETL pipelines. This is where DuckDB and MotherDuck can help you ake flight with your analytical needs, enabling a hybrid architecture for embedded analytics while letting PostgreSQL continue to excel at what it does best.
Let's dive into how these technologies can work together, exploring the options available to you based on your specific needs, technical constraints, and how much you care about your database admin's stress levels.
Duck-Based Integration Options: The Three Paths
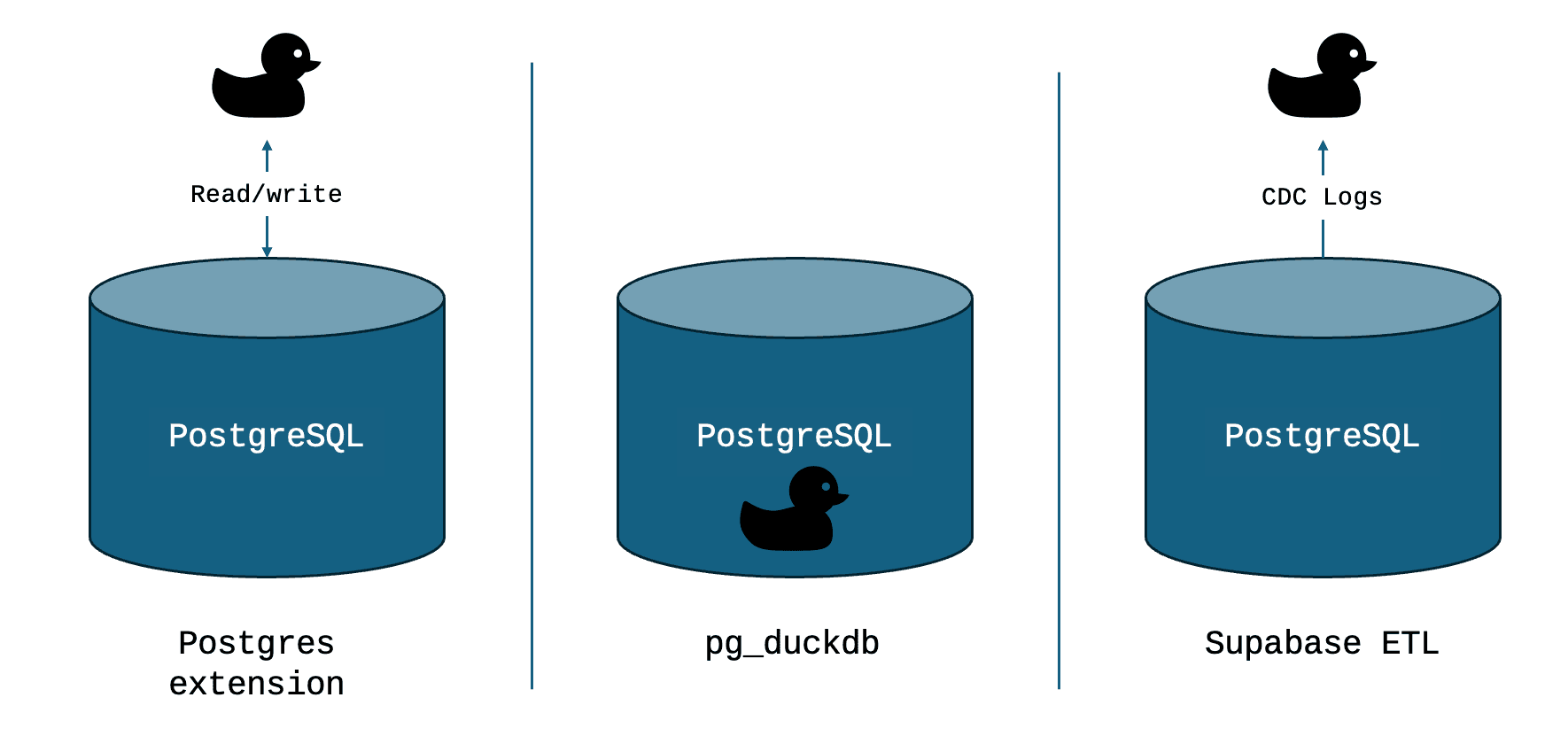
When it comes to connecting PostgreSQL with the MotherDuck ecosystem, there are three distinct postgres-native approaches to consider:
DuckDB Postgres Extension: Think of this as DuckDB (either on your local machine or in MotherDuck) reaching out to your PostgreSQL database and pulling in the data it needs for analysis. DuckDB essentially "scans" your PostgreSQL data remotely.
pg_duckdb: This approach embeds a DuckDB instance directly within your PostgreSQL server process by installing the pg_duckdb extension. This lets you run DuckDB queries right inside PostgreSQL, accessing both your local data and potentially MotherDuck or other external sources.
Supabase’s etl (fka pg_replicate) (CDC): This is a Change Data Capture approach that creates a continuous data pipeline, replicating changes from PostgreSQL to another system (like MotherDuck) in near real-time using PostgreSQL's logical decoding capabilities.
INFO: Supabase etl v1 to v2 migration As part of their migration, the `etl` project has temporarily disabled support for DuckDB. They have plans to add it back soon!Each method has its own set of tradeoffs in terms of setup complexity, performance characteristics, resource impact, and operational overhead. Let's break them down one by one.
DuckDB Postgres Extension: The Simplest Path Forward
The Postgres Extension for DuckDB is straightforward and requires minimal changes to your existing setup. It operates directly with the Postgres protocol and as such as is mostly “plug and play”.
How It Works:
You load the postgres extension in your DuckDB environment, connect to your PostgreSQL database using a standard connection string, and then either attach the entire database or query specific tables. Behind the scenes, DuckDB uses PostgreSQL's efficient binary transfer protocol to read data with minimal overhead.
Copy code
-- Example using DuckDB CLI or a client library
-- First, install and load the Postgres extension in DuckDB
INSTALL postgres;
LOAD postgres;
-- Option 1: Attach the entire database (exposes tables as views in DuckDB)
ATTACH 'dbname=postgres user=postgres host=127.0.0.1' AS db (TYPE postgres, READ_ONLY) as pg;
SELECT count(*) FROM pg.your_pg_table WHERE status = 'active';
-- Option 2: Query a single table directly
-- Use postgres_execute to attempt filter/projection pushdown
ATTACH 'dbname=postgres user=postgres host=127.0.0.1' AS db (TYPE postgres, READ_ONLY) as pg;
CALL postgres_execute('pg', 'SELECT * FROM public.your_pg_table WHERE status = 'active');
The Good Stuff:
- Simplicity: No changes needed on your PostgreSQL server. Just credentials and network access. Works perfectly with managed services like AWS RDS or Google Cloud SQL.
- Flexibility: Run DuckDB wherever you want—laptop, on-premise, or in the cloud. All the analytical heavy lifting happens on the DuckDB side.
- Isolation: Your production PostgreSQL server doesn't have to break a sweat handling complex analytical workloads.
- Consistent Reads: Uses transactional snapshots to ensure you're getting a consistent view of your data.
- Easy Exports: Quickly move data from PostgreSQL to other formats like Parquet, even writing directly to S3.
The Trade-offs:
- Network Bottleneck: Data travels over the network from PostgreSQL to DuckDB, which can slow things down for large tables.
- Limited Pushdown: While it supports some projection and filtering pushdown, when complex operations cannot be pushed down to PostgreSQL, they happen on the DuckDB side, potentially requiring more data to be transferred than necessary.
- Performance Ceiling: It's often faster than native PostgreSQL for complex analytics, but slower than if that same data were in DuckDB's native storage format.
Ideal For:
This approach quacks just right in a few scenarios: (1) quick, ad-hoc analysis for exploring data and working with smaller tables, (2) for building a simple full-refresh data pipeline, and lastly (3) when you can’t (or don’t want to) install extension in your PostgreSQL server. It’s a low commitment entrypoint into DuckDB Analytics on Postgres data.
pg_duckdb: Bringing Analytics Inside PostgreSQL
pg_duckdb takes a different approach by embedding DuckDB directly inside your PostgreSQL server process. It's like inviting a performance specialist to sit right next to your database and help it with the difficult analytical tasks. This project is a collaborative effort between Hydra and MotherDuck.
This approach comes in two flavors:
Local pg_duckdb (Without MotherDuck)
In this configuration, DuckDB instances run as part of your PostgreSQL server. You can query PostgreSQL tables through the DuckDB engine or access external data files that your PostgreSQL server can see.
Copy code
-- Example using psql connected to your PostgreSQL database with pg_duckdb available in your postgresql.conf
CREATE EXTENSION pg_duckdb;
-- Use DuckDB engine to query a Postgres table directly
SELECT count(*) FROM your_pg_table WHERE status = 'active';
-- Use DuckDB engine to query an external Parquet file accessible from the PG server
SELECT COUNT(*) FROM read_parquet('file.parquet');
-- Install and use a DuckDB extension within PG DuckDB (e.g., Iceberg)
SELECT duckdb.install_extension('iceberg');
SELECT COUNT(*) FROM iceberg_scan('data/iceberg/table');
Key Resource Consideration:
This is critically important: DuckDB is designed to aggressively use available CPU and memory to deliver speed. Running this directly on your production PostgreSQL primary instance is like trying to fit a grand piano into a tiny studio apartment—you might get it in, but there won't be room for anything else.
Best Practice: Install and use pg_duckdb on a dedicated PostgreSQL read replica. This isolates the analytical workload, ensuring that if a DuckDB query gets too resource-hungry, it only affects the replica, not your production database.
Performance Notes:
- Queries using DuckDB via pg_duckdb can be dramatically faster than native PostgreSQL for complex analytical workloads—one TPC-DS query showed a 1500x speedup in testing.
- DuckDB's vectorized engine works surprisingly well even on row-oriented PostgreSQL data.
- Queries on columnar formats like Parquet will perform exceptionally well, as they're already in an analytics-friendly format.
pg_duckdb with MotherDuck Integration
This extends pg_duckdb by connecting it to your MotherDuck database. Now you can run hybrid queries that join data from your PostgreSQL tables with data stored in MotherDuck (which might include data in S3, GCS, or other cloud storage).
Copy code
-- Example using psql with pg_duckdb and MotherDuck configured
-- Load the extension (assuming shared_preload_libraries is set)
-- ... configure MotherDuck connection via postgresql.conf or env vars ...
-- Query combining data from a Postgres table and a MotherDuck table
SELECT
c.customer_name,
sum(md_o.order_total) as total_spent
FROM
ddb$my_db$main.customers c -- Accessing the DuckDB 'customers' table
JOIN
ddb$my_db$main.orders md_o ON c.customer_id = md_o.customer_id -- Accessing the MotherDuck 'orders' table
GROUP BY 1;
-- Example of creating tables
CREATE TABLE my_pg_table AS SELECT ...; -- Creates a standard PostgreSQL table
CREATE TABLE my_md_table USING duckdb AS SELECT ...; -- Creates a MotherDuck table via pg_duckdb
Performance and Data Sync:
- Hybrid queries let you combine operational data with potentially massive datasets stored in MotherDuck, with the analytical heavy lifting handled by MotherDuck's serverless compute.
- Predicate pushdown is crucial. For hybrid queries with large PostgreSQL tables, ensuring filters are pushed down effectively to PostgreSQL minimizes data transfer.
- While you can query large PostgreSQL tables through pg_duckdb, for the best performance on truly massive datasets, you'll likely want a separate process to periodically move that data into a Star Schema in MotherDuck.
Pros (for either Local or MotherDuck Integrated PG DuckDB):
- Analytical Performance: DuckDB's engine can deliver impressive speedups for complex analytical workloads compared to native PostgreSQL.
- Data Locality (Local mode): No network overhead for data already in PostgreSQL.
- Hybrid Queries (MotherDuck mode): Seamlessly join operational PostgreSQL data with cloud data in a single query.
- Columnar Access: Easily query Parquet, Iceberg, and other analytics-friendly formats directly from PostgreSQL.
Cons:
- Resource Risk: Significant chance of impacting PostgreSQL server performance if not isolated on a dedicated replica.
- Extension Required: You'll need to install the pg_duckdb extension on your PostgreSQL servers, which might not be possible on all managed services.
- Operational Complexity: You'll need to manage the extension and monitor resource usage carefully.
Supabase’s ETL (fka pg_replicate): Change Data Capture for Real-time Analytics
Unlike the previous methods that focus on querying data where it lives,pg_replicate is about moving data continuously. It captures changes from PostgreSQL's Write-Ahead Log (WAL) and streams them to another destination like MotherDuck, enabling near real-time analytics. Supabase's pg_replicate is a newer option in this space; Debezium is a more established alternative often used with Kafka.
How It Works:
This method taps into PostgreSQL's logical decoding feature. A process connects to PostgreSQL, reads the WAL, decodes the changes, and streams them to a downstream system.
Conceptual steps (actual implementation depends heavily on the CDC tool and destination)
- Configure PostgreSQL for logical replication/decoding
- Install and configure the CDC tool (e.g., PG Replicate, Debezium)
- CDC tool reads WAL and streams changes
- Downstream system (e.g., MotherDuck via a loading process) consumes changes
Technical Considerations:
- WAL Impact: CDC increases the WAL detail level, slightly increasing disk I/O and storage requirements.
- Processing Load: The CDC process adds some CPU load, and risks falling behind during high-volume write periods.
- Operational Complexity: You need to set up, monitor, and maintain a continuous pipeline, handling network issues, processing lag, and error conditions.
- Extension Requirements: Like pg_duckdb, CDC tools often require installing extensions on your PostgreSQL server.
- Managed Service Support: Support varies by cloud provider. AWS RDS supports logical replication with specific output plugins, while other providers may have different limitations.
Ideal For:
This approach shines when you need low-latency, near real-time data updates for dashboards or operational analytics. It completely separates the analytical workload from PostgreSQL once the data is moved.
Tool Comparison:
- Debezium: Mature, open-source platform supporting many databases, typically used with Kafka. Requires more infrastructure but is battle-tested.
- ETL: Newer, PostgreSQL-specific tool from Supabase. Potentially simpler setup than Debezium/Kafka but less mature.
Making the Right Choice: Strategic Recommendations
Your perfect match depends on your specific needs, constraints, and operational capabilities:
Choose DuckDB Postgres Extension when:
- You need simple setup without PostgreSQL extensions
- You're doing ad-hoc analysis, exploration, or data export
- The data is small enough that a full-refresh is cost-effective for data loading
- Network latency is acceptable
Choose PG DuckDB when:
- You can install extensions and manage the PostgreSQL environment
- You need high-performance analytics on PostgreSQL data
- Critical: You can provision a dedicated read replica for isolation
- You want to query external columnar files from PostgreSQL
Choose Supabase ETL (CDC) when:
- You need near real-time data synchronization
- You can handle the operational complexity of a continuous pipeline
- You have the necessary permissions for logical decoding setup
Operational Best Practices:
Whatever path you choose (except perhaps the simplest extension use cases), careful resource planning and isolation are key:
- Use Replicas: For pg_duckdb especially, a dedicated read replica is highly recommended
- Monitor Resources: Keep a close eye on CPU, memory, I/O, and network usage
- Profile Your Queries: Understand where bottlenecks lie and leverage optimization capabilities where possible
The Bottom Line
Integrating PostgreSQL with DuckDB and MotherDuck offers practical ways to enhance your analytical capabilities without migrating all your data or building an entire data warehouse from scratch.
The DuckDB Postgres Extension gives you an easy entry point for remote querying. pg_duckdb delivers high-performance analytics within PostgreSQL (best used on a dedicated replica). Supabase ETL addresses the need for low-latency, continuous data movement.
Understanding the characteristics and tradeoffs of each approach is essential for making the right choice for your specific situation. By considering your performance requirements, operational capacity, and resource constraints, you can effectively combine PostgreSQL's reliability with DuckDB's analytical prowess.
I'd encourage you to start small, perhaps with the Postgres Extension approach, and then explore the other options as your needs evolve. After all, even the mightiest duck starts with a single paddle.
Learn More & Get Started
Start using MotherDuck now!

