
Key Takeaways
- Shift to Live Apps: Modern data warehouses (DWH) have evolved from static reporting engines to backends for live applications and interactive dashboards.
- Simplified Stack: You can query the warehouse directly for internal tools and customer-facing analytics, removing the need for an intermediate Postgres layer.
- Hub-and-Spoke: A lean DWH like MotherDuck complements legacy systems (Snowflake/BigQuery) by acting as a high-speed serving layer.
- Real-Time Dashboards: Low-latency query engines enable data warehouse dashboards that refresh in seconds, not hours.
Imagine this common scenario: marketing team needs a live data warehouse dashboard to track live campaign sign-ups. The data resides in the corporate data warehouse, but the BI team explains that a live dashboard is not possible. The system is designed for nightly reports. The only path forward seems to be building a separate, complex data pipeline with a new database just for this one internal tool. This friction is a clear sign that the data warehouse is acting as a data bottleneck, not a data engine.
For years, data warehouses were heavyweight systems, optimized for massive, scheduled queries that powered executive-level business intelligence. But the rise of serverless architectures and hyper-fast analytical engines like DuckDB has created a new category: the lean, modern data warehouse.. This is not just a place to store data for reports. It is a programmable, high-performance backend for a new class of data applications, and the core of what we're building at MotherDuck.
Without this modern approach, companies are forced to build and maintain multiple, fragmented data stacks. This leads to data silos, inconsistent metrics, high infrastructure costs, and slow development cycles, preventing teams from getting the data they need, when they need it.
This article breaks down four powerful use cases for a modern data warehouse that go far beyond traditional BI. By the end, you will understand how to:
- Build Lightweight Internal Applications: Rapidly create internal tools that query the warehouse directly, without needing a separate backend database.
- Supercharge Data Science Exploration: Enable data scientists to analyze terabytes of data directly in their notebooks, eliminating the need to manage separate compute clusters.
- Deliver Simple Operational Analytics: Power dashboards that monitor business operations in near real-time, closing the gap between action and insight.
- Launch Customer-Facing Analytics: Embed fast, interactive dashboards and data exploration features directly into your product, creating value for your customers.
Modern vs. Traditional Data Warehouse: From BI Engine to Application Backend
The fundamental difference between a traditional and a modern data warehouse is not just speed, but a shift in purpose. It is a move from a system designed for a small group of analysts running scheduled reports to a platform built for developers to power live applications.
Traditional warehouses were architected around provisioned clusters and batch ETL (Extract, Transform, Load) processes. Their cost models and query planners were optimized for a small number of very large, complex jobs running overnight, typical of traditional petabyte-scale benchmarks. This design made them powerful for their intended purpose, but ill-suited for the interactive, low-latency demands of an application. Trying to use one as an application backend often results in a "Big Data Tax" of high query latency, stale data, and inflated costs.
The lean, modern data warehouse inverts this model. Built on serverless principles and powered by efficient vectorized query engines, it separates storage from compute and is designed for programmatic access. It excels at handling many concurrent, small-to-medium-sized analytical queries with sub-second latency. This makes it an ideal backend for applications that need to ask complex questions of data and get answers immediately.
The following table clarifies the trade-offs by comparing the two models based on their optimized workloads.
| Characteristic | Traditional Data Warehouse (e.g., Redshift, BigQuery, Snowflake) | Modern Lean Warehouse (e.g., MotherDuck) |
|---|---|---|
| Primary Workload | Planet-scale batch transformations and scheduled BI reporting. | Interactive queries for live applications and ad-hoc analysis. |
| Query Latency | Optimized for high-throughput batch. Can have high "cold start" latency for interactive queries. | Optimized for low-latency interactive queries (sub-second to seconds). |
| Cost Model | Provisioned clusters (pay-for-idle) or serverless models with minimums, optimized for heavy jobs. | Serverless, per-query pricing with zero idle cost, optimized for bursty, interactive workloads. |
| Data Freshness | Typically hours to days, updated via nightly or hourly batch ETL jobs. | Seconds to minutes, enabled by modern ingestion patterns. |
| Developer Experience | Primarily SQL-based for BI analysts. Programmatic access can be complex. | SDK-first (Python, Java, etc.) with a rich API, designed for developers. |
| Ideal User | Central BI teams, data engineers running large-scale ETL. | Application developers, data scientists, and internal tool builders. |
This distinction is not about one being "better" than the other. Instead, it is about workload optimization. A traditional warehouse excels at transforming 10 terabytes of raw data once a day, while a lean warehouse excels at running ten thousand small queries per hour to power a live dashboard.
How a Modern Data Warehouse Augments Your Existing Data Stack
A common and critical question for any organization with an existing data platform is whether this new model requires a "rip and replace" of their current data warehouse. The answer is almost always no. Instead, the lean warehouse fits into a modern "hub-and-spoke" or "two-tier" architecture, augmenting the existing system.
In this model, the traditional data warehouse (like Snowflake, BigQuery, or Redshift) remains the central "hub" or "cold" storage layer. It acts as the single source of truth, handling massive, enterprise-scale data transformations, governance, and batch processing. It continues to be the engine for large-scale BI and reporting.
The lean, modern warehouse serves as a high-performance "spoke" or "hot" serving layer. It is designed for the interactive workloads that the central warehouse struggles with. Typically, data is prepared and transformed by the central warehouse and then landed in an open, columnar format like Apache Parquet in cloud object storage (e.g., Amazon S3, Google Cloud Storage). The lean warehouse can then query this data directly, serving low-latency requests for applications without impacting the central system.
Figure 1: A two-tier architecture where a lean warehouse acts as a high-performance serving layer for applications, querying data prepared by a traditional DWH.
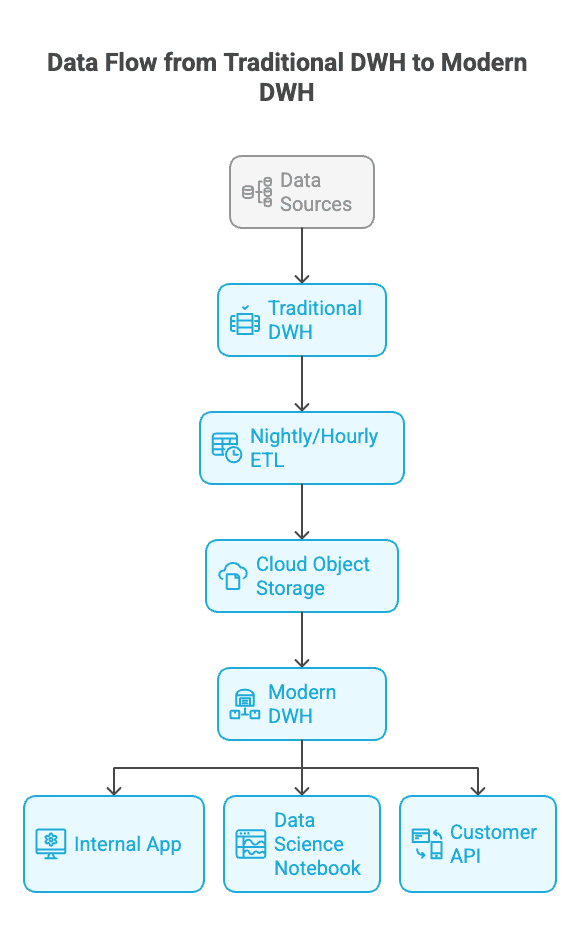
This architecture provides the best of both worlds. It uses the scale and maturity of the existing data warehouse for heavy lifting while introducing a specialized, cost-effective layer for the speed and concurrency required by live data applications.
Modern Data Ingestion Patterns for Near Real-Time Analytics
A warehouse is only as useful as the freshness of its data. While traditional systems relied on nightly ETL jobs, a lean warehouse serving live applications requires more current data. This is achieved through modern ingestion patterns that move beyond monolithic, once-a-day updates.
The first and simplest pattern is Direct Query on Object Storage. In many analytical use cases, "ingestion" is no longer a separate step. Modern query engines can efficiently query collections of Parquet or CSV files directly in cloud storage. The process of getting data into the warehouse is simply the process of landing a new, fresh file in the correct location. This approach, often used in lakehouse architectures, minimizes data movement and complexity.
For data that requires transformation, Micro-batching provides a near-fresh alternative to nightly ETL. Using tools like dbt in conjunction with orchestrators such as Airflow or Dagster, data transformation jobs can run on frequent schedules, perhaps every 5 to 15 minutes. These jobs read raw data, apply business logic, and write fresh, analytics-ready files to object storage, where they are immediately available for querying by the lean warehouse.
Finally, for true real-time needs, Streaming Ingestion offers the lowest latency. This involves connecting the warehouse directly to an event stream like Apache Kafka or AWS Kinesis. The warehouse can either ingest events into an internal table or query the stream directly. This pattern is more complex to implement but provides sub-second data freshness for critical operational monitoring or real-time personalization features.
Use Case #1: Powering Lightweight Internal Applications
Internal tools, such as custom CRM views, support ticket analyzers, or financial health dashboards, are often a source of immense architectural pain. The default path requires provisioning a separate application database (like PostgreSQL), building a data pipeline to copy and transform data from the warehouse, and writing a backend service to expose it. This creates significant maintenance overhead for what should be a simple tool.
The modern solution radically simplifies this stack. An application framework like Streamlit, Retool, or a simple Flask API can use a native SDK, like the DuckDB Python SDK, to query the lean data warehouse directly. The warehouse itself becomes the analytical backend for the application. There is no need for a separate database or a fragile data pipeline, as the tool has direct access to the most up-to-date data available.
This architectural pattern is straightforward: the internal application's backend makes authenticated calls to the warehouse via an SDK, runs a SQL query, and visualizes the results.
For example, a simple Streamlit application to monitor user sign-ups could be built with just a few lines of Python. This script connects to the warehouse, executes a query to count sign-ups by day, and renders the result as a chart.
Copy code
import streamlit as st
import duckdb
import pandas as pd
# Use Streamlit secrets to securely store the MotherDuck token
md_token = st.secrets["MOTHERDUCK_TOKEN"]
st.title('Live Data Warehouse Dashboard: User Sign-ups')
try:
# Connect to MotherDuck. The token provides authentication.
con = duckdb.connect(f'md:my_database?motherduck_token={md_token}')
# The SQL query runs directly against the warehouse
sql_query = """
SELECT
DATE_TRUNC('day', signup_timestamp)::DATE AS signup_day,
COUNT(user_id) AS num_signups
FROM users
WHERE signup_timestamp >= NOW() - INTERVAL '30 days'
GROUP BY 1
ORDER BY 1;
"""
# Execute the query and fetch results into a Pandas DataFrame
df = con.sql(sql_query).df()
st.write("User Sign-ups Over the Last 30 Days")
st.line_chart(df.set_index('signup_day'))
except Exception as e:
st.error(f"An error occurred: {e}")
finally:
if 'con' in locals() and con:
con.close()
The benefits are immediate: a vastly simplified architecture, guaranteed access to the freshest data, zero data duplication, and a much faster time-to-market for building the tools that help the business run.
Use Case #2: Supercharging Ad-Hoc Data Science with a Modern Data Warehouse
Data scientists often face a frustrating dilemma when working with large datasets. The data is too large to fit into a local machine's memory, forcing them to either work with heavily down-sampled data (risking inaccurate conclusions) or request access to a distributed computing cluster like Spark. This "request-wait-analyze" cycle introduces significant friction and slows down the pace of exploration and discovery.
A modern data warehouse changes this workflow by making the data scientist's notebook a powerful, direct client to terabytes of data. Using a Python library like duckdb, a data scientist can connect to the warehouse from a Jupyter or Hex notebook and execute complex SQL queries against massive datasets stored in cloud object storage. The heavy computation happens in the cloud, and only the relatively small result set is returned to the notebook as a Pandas DataFrame, ready for visualization or modeling.
This pattern uses hybrid execution, a key capability of modern analytical systems. The query engine can intelligently decide which parts of a query to execute locally on the user's machine—or even directly within web-based exploration tools using [DuckDB Wasm](https://motherduck.com/blog/duckdb-wasm-in-browser/)—and which parts to push down to the powerful cloud backend (e.g., scanning terabytes of Parquet data). This optimizes for both performance and cost.
The following notebook cells demonstrate this workflow. A data scientist can install the library, connect, and immediately begin analyzing a large public dataset, such as the NYC taxi dataset stored in S3.
Copy code
# Cell 1: Installation
%pip install duckdb --quiet
Copy code
# Cell 2: Connect and Query
import duckdb
import os
# Securely connect using an environment variable for the token
md_token = os.environ.get("MOTHERDUCK_TOKEN")
con = duckdb.connect(f'md:?motherduck_token={md_token}')
# This query runs against a large public dataset in S3.
# The computation happens in MotherDuck's cloud service.
sql = """
SELECT
hvfhs_license_num,
COUNT(*) AS trip_count,
AVG(trip_miles) AS avg_trip_miles
FROM 's3://us-east-1.motherduck.com/nyc-taxi/fhvhv_tripdata_2022-*.parquet'
GROUP BY 1
ORDER BY 2 DESC
LIMIT 10;
"""
# The %%time magic command measures the execution time
%time taxi_df = con.sql(sql).df()
Copy code
# Cell 3: Analyze the result
# The result is a small, manageable Pandas DataFrame, ready for local analysis.
print(taxi_df)
This approach frees data scientists from infrastructure management and eliminates the need for costly, dedicated clusters for exploratory analysis. They can work with full datasets from the comfort of their preferred tools, leading to faster insights and more accurate models.
Use Case #3: Operational Analytics with Real-Time Data Warehouse Dashboards
There is a critical distinction between traditional Business Intelligence (BI) and Operational Analytics. BI focuses on what happened, analyzing historical data to understand long-term trends, such as quarterly sales performance. Operational analytics focuses on what is happening right now, monitoring key business metrics to inform immediate action, such as tracking failed payment transactions in the last 15 minutes.
Traditional data warehouses are poorly suited for operational analytics for several reasons. Their high query latency means dashboards can take minutes to load. The data freshness lag, often measured in hours or days, makes the information too stale for real-time decision-making. Finally, their cost models can make the high frequency of queries required for a constantly refreshing dashboard prohibitively expensive.
A lean, low-latency warehouse is an ideal engine for these operational dashboards. Because queries complete in seconds and are individually inexpensive, it becomes technically and economically feasible to build dashboards that auto-refresh every minute. This provides operations teams with a near real-time view of the business.
For example, a logistics company can power a dashboard for its dispatch center showing package delivery statuses. A simple query can be executed every 60 seconds to provide an up-to-the-minute summary:
Copy code
SELECT
status,
COUNT(*) AS package_count
FROM shipments
WHERE event_timestamp > NOW() - INTERVAL '1 hour'
GROUP BY status;
This query quickly summarizes recent activity, allowing the team to spot anomalies, like a spike in "Delayed" packages, and take immediate action. This closes the gap between insight and action, a core goal that traditional BI struggles to achieve.
Use Case #4: Customer-Facing Analytics via Embedded Data Warehouse Dashboards
Perhaps the most powerful application of a lean, modern warehouse is embedding analytics directly into a product for customers. Building fast, reliable, and secure in-app dashboards is a notoriously difficult engineering challenge. The common approaches both have major drawbacks: querying a production OLTP database directly risks performance degradation and is not designed for analytical loads, while building a separate sidecar analytics system is complex, expensive, and introduces data synchronization challenges.
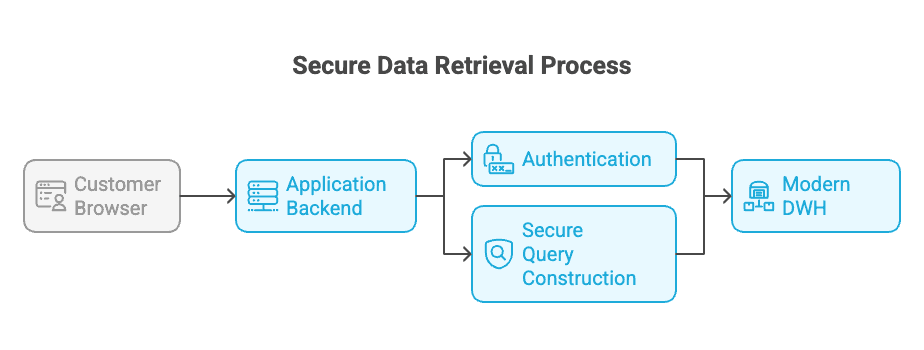
A modern warehouse provides a clean architectural solution. The customer's browser interacts with your application's backend API. The backend is responsible for authenticating the user and then acting as a secure intermediary to the data warehouse. It constructs a SQL query, crucially including a WHERE clause to enforce data tenancy, and executes it against the warehouse. The results are returned as JSON to the frontend for rendering.
Dashboarding Tools Ecosystem
While building a custom frontend is powerful, you can also leverage the modern data stack ecosystem. Tools like Evidence.dev, Streamlit, and Preset (Superset) connect natively to MotherDuck. This allows you to build a 'data warehouse dashboard' using code-first workflows (BI-as-Code) while maintaining the performance benefits of a columnar engine.
This architecture succeeds because it meets the strict requirements of customer-facing analytics:
- Low Latency: Queries must return in under a second to provide an interactive user experience.
- Concurrency: The system must handle simultaneous requests from hundreds or thousands of users without degrading performance.
- Scalability: The infrastructure must scale automatically as the user base grows.
The serverless nature of the modern warehouse handles the concurrency and scalability challenges automatically, while the underlying query engine provides the necessary low latency.
Secure Multi-Tenancy for Customer-Facing Analytics
Presenting data to external customers demands a robust security model. Simply adding a WHERE customer_id = ? clause is a necessary first step for tenancy, but it is not a complete security architecture. A secure implementation relies on the application backend to act as a trusted gatekeeper.
First, API Gateway Authentication is critical. Before any query is run, the backend must validate the user's session, typically via an auth token or session cookie. Anonymous or unauthorized requests should never reach the database layer.
Second, the backend must use Parameterized Queries to prevent SQL injection attacks. The customer_id and any other user-provided filter values must be passed as parameters to the database driver, not formatted directly into the SQL string. This ensures that user input cannot alter the structure of the query.
Correct (Parameterized):
Copy code
# customer_id is passed as a safe parameter
query = f"SELECT * FROM usage_events WHERE customer_id = $1"
result = con.execute(query, [customer_id]).fetchall()
Incorrect (Vulnerable to SQL Injection):
Copy code
# Never format user input directly into a SQL string
query = f"SELECT * FROM usage_events WHERE customer_id = '{customer_id}';" # DANGEROUS
result = con.execute(query).fetchall()
Finally, for more complex security requirements, some databases offer a defense-in-depth feature called Row-Level Security (RLS). RLS allows administrators to define security policies directly within the database, ensuring that even if a query is flawed, a user can only ever access rows that they are explicitly permitted to see. The application backend remains the primary line of defense, but RLS provides an important secondary safeguard.
Conclusion
The evolution of the data warehouse represents a shift from a monolithic, single-purpose system to a flexible, high-value component in the modern data stack. By embracing speed, developer-friendly interfaces, and programmatic access, a lean warehouse unlocks analytical capabilities that were previously too complex or expensive for many organizations to build.
This approach is not a replacement for the traditional data warehouse but a powerful complement, creating a two-tier architecture optimized for both massive batch processing and low-latency interactive applications.
You should consider a lean, modern data warehouse when your project involves:
- Interactivity: Users or applications need answers in seconds, not minutes.
- Developer-led initiatives: Developers or data scientists are the primary builders, requiring robust SDKs and APIs.
- Simplified Architecture: The goal is to reduce data pipelines and avoid creating separate databases for every new analytical feature.
By using these new capabilities, teams can move faster, simplify their infrastructure, and deliver the live data experiences that users now expect. To get started, you can sign up for MotherDuck for free.
Start using MotherDuck now!
FAQS
What is the main difference between a modern and a traditional data warehouse?
The primary difference is the optimized workload. Traditional data warehouses (like Snowflake, BigQuery) are built for large-scale, scheduled batch jobs that power historical BI reports. A modern, lean data warehouse (like MotherDuck) is optimized for low-latency, high-concurrency interactive queries, making it ideal for powering live data applications.
Can MotherDuck replace my existing data warehouse?
No, MotherDuck is designed to augment, not replace, your existing data warehouse. In a common "two-tier" architecture, a traditional warehouse handles large-scale data transformation (the "cold" layer), while MotherDuck serves as a fast, interactive "hot" layer for applications, querying analytics-ready data from object storage.
Is a modern data warehouse suitable for real-time analytics?
It is ideal for near real-time operational analytics. Using modern ingestion patterns like micro-batching or direct queries on object storage, data can be kept fresh to within minutes or even seconds. This enables live dashboards that monitor current business operations, a task for which traditional warehouses with hours-long data latency are ill-suited.
Can I build a dashboard directly on a data warehouse?
Yes, modern data warehouses like MotherDuck support direct querying by dashboarding tools (such as Streamlit, Evidence, or Superset) or custom front-ends, eliminating the need for a separate serving database.
What are the best data warehouse use cases for startups?
Startups leverage modern data warehouses for embedded customer-facing analytics, internal operational dashboards, and AI agent training without the overhead of enterprise-scale data stacks.
