
Hey, friend 👋
It’s Marcos again, aka “DuckDB News Reporter” with another issue of “This Month in the DuckDB Ecosystem for September 2023.
I'm super excited that DuckDB 0.9 has been released, with significant performance improvements already being discussed on Twitter, plus support for Azure storage and Iceberg files.
It has been a busy month for all, not only for the DuckDB ecosystem but for the MotherDuck team as well, especially after the great news of the new funding round led by Felicis, and of course the opening of the platform to anyone who wants to try it. It’s time to play with magic here, with 0.9 support in MotherDuck coming in a week or two.
This proves once again our point: the “Quack Stack” is thriving and organizations of all sizes (from small start-ups to big enterprises) are more and more interested in it.
As always we share here, this is a two-way conversation: if you have any feedback on this newsletter, feel free to send us an email to duckdbnews@motherduck.com.
Featured Community Member

Niels Claeys
Niels Claeys is a lead data engineer at Data Minded. From an early age he was passionate about large scale distributed systems. He has over 6 years of experience building batch and streaming data pipelines using Spark, kafka and SQL. He recently contributed to the dbt adapter for DuckDB and made some noise with his blog post “Use dbt and Duckdb instead of Spark in data pipelines”.
Top DuckDB Links this Month
MotherDuck + dbt: Better Together

dbt has become an indispensable tool for Data Engineers these days. Sung Wong Chung shares a simple but valuable way to combine it with the power of DuckDB and MotherDuck.
Vector similarity search with duckdb
If you want to combine the power of PostgreSQL extension ecosystem with DuckDB, this is a primary example. Great work Chang She.
Duckdb – A Fascinating Comprehensive Guide
It’s always great to see simple guides like this one to understand why you need to learn DuckDB. One of people’s favorite features of DuckDB: is the vectorized query execution engine. Let’s use Torry’s words on this one:
Another groundbreaking feature of DuckDB is its vectorized query execution engine. This engine processes data in batches, applying operations to multiple data points simultaneously, thus leveraging the inherent parallelism of modern CPUs. This vectorized approach leads to significant performance gains, making DuckDB well-suited for complex analytical workloads. Furthermore, DuckDB employs a hybrid execution model that seamlessly integrates row-based and column-based processing techniques, optimizing performance for various query types.
Sentiment Analyze 2 GB JSON Data with Duckdb and Rust
I’m a Pythonista, but I’ve learned to love the speed of Rust. So, I wanted an example to show how to work with both projects at the same time: DuckDB and Rust, and Wei Huang provides precisely that: doing sentiment analysis with it. BTW, if you want to keep exploring this combination, I encourage you to read this insightful post from Florian Tieben called “The Future of Data Engineering: DuckDB + Rust + Arrow”, and read the docs about it.
Performance Explorations of GeoParquet (and DuckDB)
This is a very interesting benchmark conducted by Chris Holmes about how GeoParquet works with DuckDB. It’s always great to read about how DuckDB unlocks new use cases every single day.
DuckDB: The Indispensable Geospatial Tool You Didn't Know You Were Missing
If you want to read another perspective about why DuckDB is making waves today, you should read this post from Chris Holmes (again, yes, he is awesome), and why you should consider DuckDB if you will develop geospatial apps.
DuckDB + Dbt + great expectations = Awesome Data pipelines
Data quality is a topic in everybody’s mouth today in the Data Engineering world, and Great Expectations provides an Open Source Python-based powerful framework for it. And if you have DuckDB on one side and dbt on the other side, you could build incredibly simple and reliable data pipelines. This post gives you a quick overview of how to combine these tools.
DuckDB: Bringing analytical SQL directly to your Python shell
In this talk, Pedro Holanda presented DuckDB. DuckDB is a novel data management system that executes analytical SQL queries without requiring a server. DuckDB has a unique, in-depth integration with the existing PyData ecosystem. This integration allows DuckDB to query and output data from and to other Python libraries without copying it. This makes DuckDB an essential tool for the data scientist. In a live demo, we will showcase how DuckDB performs and integrates with the most used Python data-wrangling tool, Pandas.
Even Friendlier SQL with DuckDB
The one and only Alex Monahan shared this insightful post about how to take advantage of the last innovation in the SQL language made by DuckDB. Believe me: you must read the entire series.
Harlequin: The DuckDB IDE for the Terminal
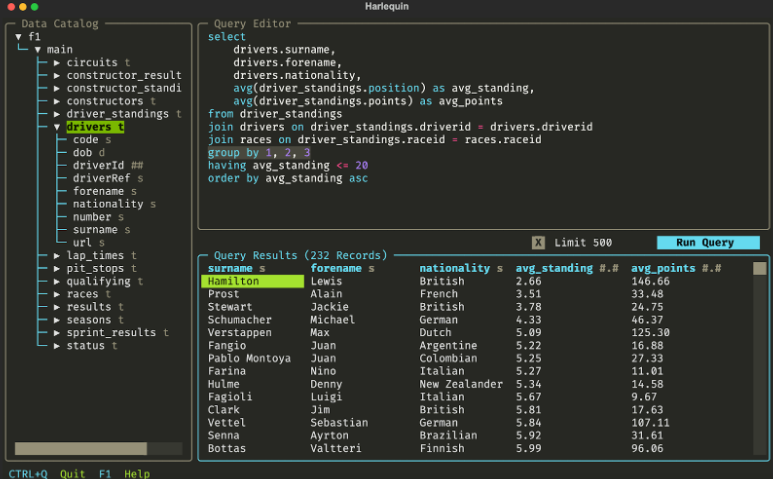
What is Harlequin? It’s a very cool project developed by Ted Conbeer. As its name indicates, is an IDE for DuckDB in the console, with very interesting features like you can interact with the data catalog, it has a query editor, a result viewer, and even: it has support for MotherDuck in local or SaaS mode. Is not that cool? Try and let us know what you think!
Upcoming events
Coalesce by dbt labs 16-19th October 2023
Coalesce by dbt labs is happening in multiple locations. MotherDuck will have a booth in the "activation hall" in San Diego. The MotherDuck team invites you to come say hi if you're around.
