ECOSYSTEM
Announcing Data Outpost - The conference for data people in a world being rebuilt by AINov 4-5 | San Francisco
DuckDB has been charming to me ever since I wrote about it a year ago.
It gave me the glimmers of something I’ve been begging for a long time: fast should be measured in seconds, not minutes.
I kicked the tires a lot when working at dbt Labs.
And in all the tire kicking, it has remained true to the glimmers it gave me and so much more. It’s fast, easy, and cheap. And if it’s running on your local computer, it’s free.
I’ve had incredibly asymmetric expectations of how much money, time, and work it takes to make data fast and easy that I think to myself, “Oh, of course you’re supposed to pay lots of dollars to run queries on millions/billions of rows per month.” This has pleasantly disrupted that inner anchoring point. I see something more charming at play. Data teams can be productive with data bigger and work faster and save more money than they could have dreamed of 5 years ago. Heck! Even a year ago. So let’s get into it.
Well, DuckDB and Motherduck’s primary use case is solving analytical problems fast. Because of its columnar design, it’s able to do just that. Even more so, the creators were smart about making integrations with adjacent data tools a first class experience. We see this with reading S3 files without copying them over and querying postgres directly without needing to extract and load it into DuckDB. And you don’t need to define schemas or tedious configurations to make it work! Motherduck enables the multiplayer experience that having a single file on your machine is too tedious to pass around and synchronize with your teammates. Motherduck runs DuckDB on your behalf AND uses your local computer if the query you’re running makes more sense to run there. You get dynamic execution out of the box. And that’s pretty sweet.
But more than platitudes, let’s get hands-on with working code so you can taste and see for yourself!
You can follow along with this repo:
 Note : MotherDuck is still under private beta, but I heard you could get an invite if you join their community slack with a good duck pun.
Note : MotherDuck is still under private beta, but I heard you could get an invite if you join their community slack with a good duck pun.Sign in and your screen should look like this minus some of the stuff you’ll be building in the rest of this guide.
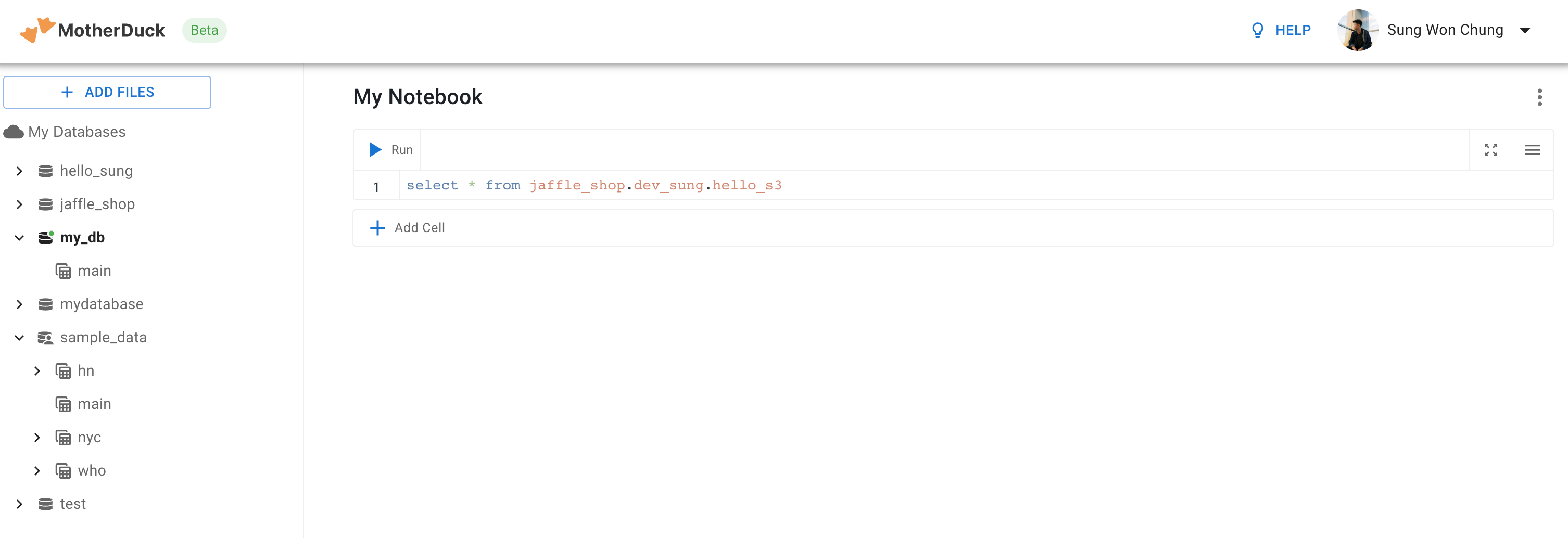
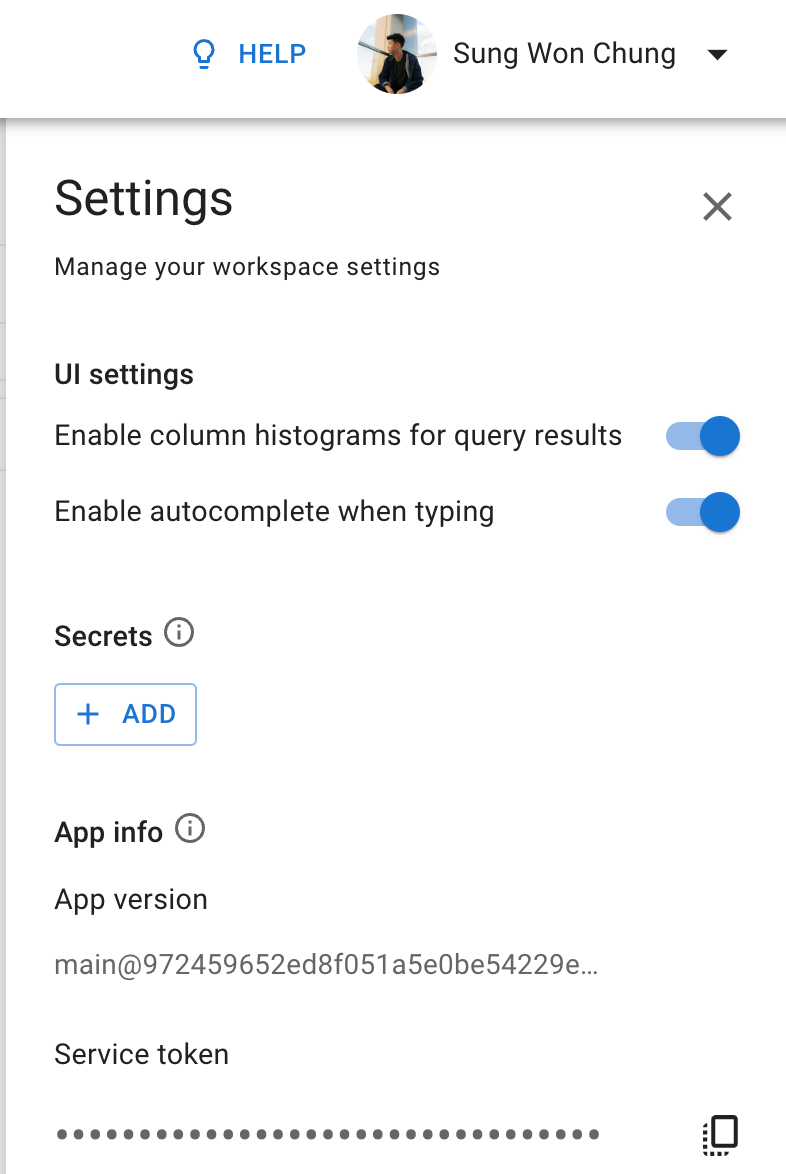
Click on the settings in the upper right hand corner and copy your Service Token to the clipboard.
Clone the repo and change directories into it.
Copy code
git clone -b blog-guide https://github.com/sungchun12/jaffle_shop_duckdb.git
cd jaffle_shop_duckdb
Note: Feel free to skip this step if you already have an AWS account with S3 setup! Plus, MotherDuck has these data under their public S3 bucket at s3://us-prd-motherduck-open-datasets/jaffle_shop/csv/
Take the csv files stored in the git repo here and upload them into S3:
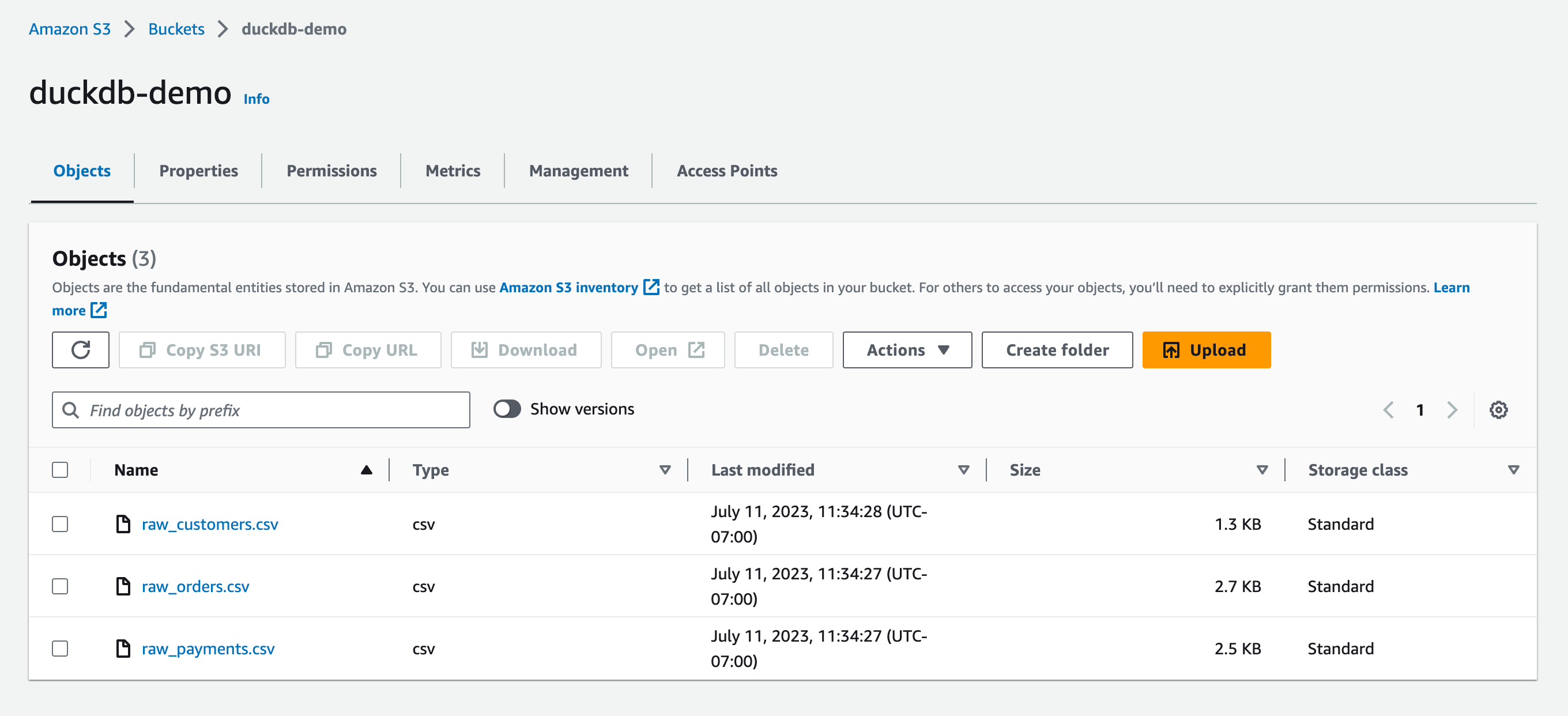
Copy the AWS S3 access keys to authenticate your dbt project for later.
Note: Huge thanks to Josh Wills for creating the dbt-duckdb adapter and it works great with both DuckDB and MotherDuck: https://github.com/jwills/dbt-duckdb. This demo only works with DuckDB version 0.8.1: https://motherduck.com/docs/intro
profiles.yml for the naming conventions that make sense to you. Specifically, focus on schema.Copy code
jaffle_shop:
target: dev
outputs:
dev:
type: duckdb
schema: dev_sung
path: 'md:jaffle_shop'
threads: 16
extensions:
- httpfs
settings:
s3_region: "{{ env_var('S3_REGION', 'us-west-1') }}"
s3_access_key_id: "{{ env_var('S3_ACCESS_KEY_ID') }}"
s3_secret_access_key: "{{ env_var('S3_SECRET_ACCESS_KEY') }}"
dev_public_s3:
type: duckdb
schema: dev_sung
path: 'md:jaffle_shop'
threads: 16
extensions:
- httpfs
settings:
s3_region: "{{ env_var('S3_REGION', 'us-east-1') }}" # default region to make hello_public_s3.sql work correctly!
s3_access_key_id: "{{ env_var('S3_ACCESS_KEY_ID') }}"
s3_secret_access_key: "{{ env_var('S3_SECRET_ACCESS_KEY') }}"
prod:
type: duckdb
schema: prod_sung
path: 'md:jaffle_shop'
threads: 16
extensions:
- httpfs
settings:
s3_region: us-west-1
s3_access_key_id: "{{ env_var('S3_ACCESS_KEY_ID') }}"
s3_secret_access_key: "{{ env_var('S3_SECRET_ACCESS_KEY') }}"
Copy code
# all examples are fake
export motherduck_token=<your motherduck token> # aouiweh98229g193g1rb9u1
export S3_REGION=<your region> # us-west-1
export S3_ACCESS_KEY_ID=<your access key id> # haoiwehfpoiahpwohf
export S3_SECRET_ACCESS_KEY=<your secret access key> # jiaowhefa998333
Copy code
python3 -m venv venv source venv/bin/activate python3 -m pip install --upgrade pip python3 -m pip install -r requirements.txt
dbt debug to verify dbt can connect to motherduck and S3Copy code
dbt debug
dbt build to run and test the project!Copy code
dbt build
Copy code
--filename: hello_public_s3.sql
{% if target.name == 'dev_public_s3' %}
SELECT * FROM 's3://us-prd-motherduck-open-datasets/jaffle_shop/csv/raw_customers.csv'
{% else %}
select 1 as id
{% endif %}
Copy code
dbt build --target dev_public_s3
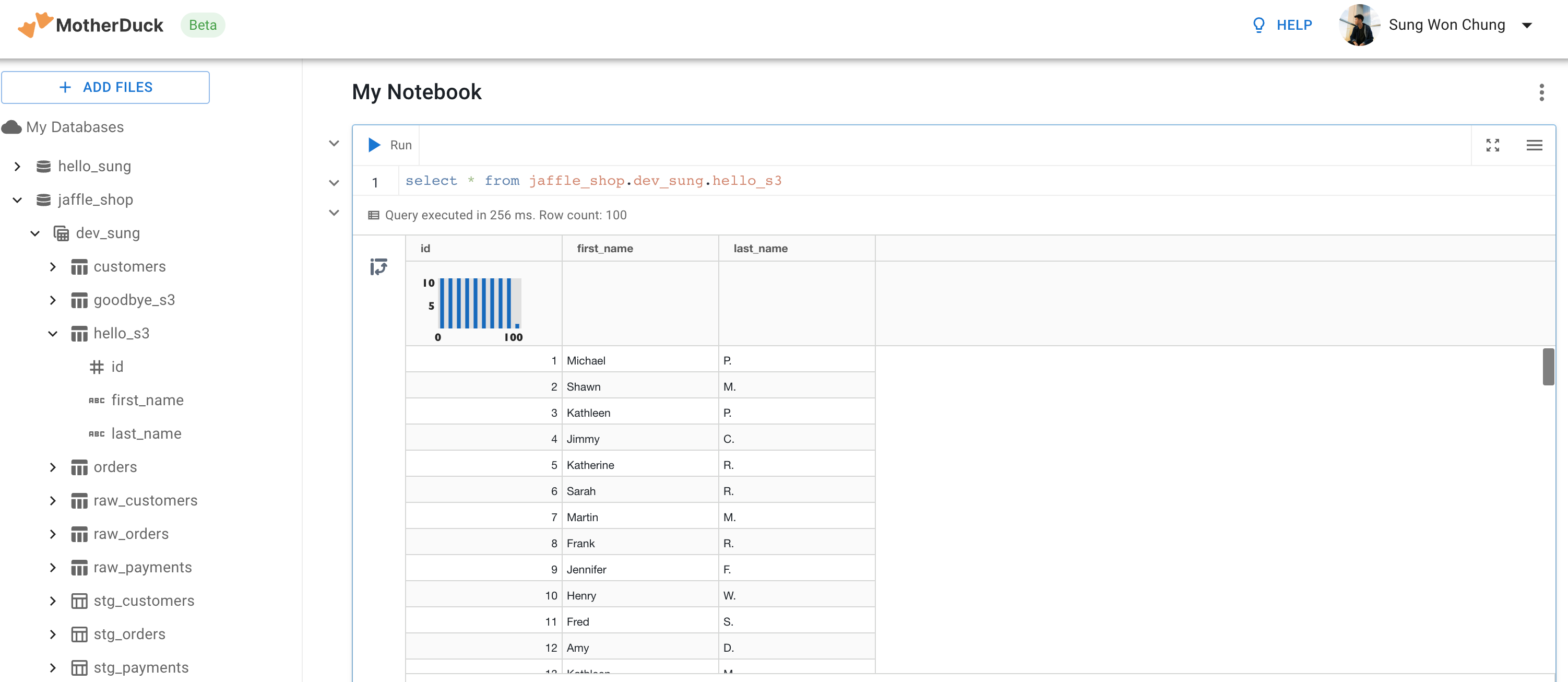
That’s it! Ruffle up those feathers and start quacking and slapping those juicy SQL queries together to solve your analytics problems faster and cheaper than ever before!
We’re at a really cool place where all I had to give you was a couple instructions to get you up and running with MotherDuck. I really hope the data industry gets to a place where we brag about the things we do NOT have to do vs. pride ourselves on complexity for its own sake. What matters is that we solve problems and spend time, money, and energy doing it where it’s actually worth it to solve those problems. I’m excited to see you all build MotherDuck guides far superior to mine (or you can continue learning with our end-to-end dbt data engineering project). That’s why this is so fun. That’s why this is so fun. We get to sharpen each other!
Want to know more about MotherDuck and dbt ? Checkout MotherDuck & dbt documentation and have a look at their YouTube tutorial about DuckDB & dbt 👇