2024/03/11 - Joseph Hwang
Differential Storage: A Key Building Block For A DuckDB-Based Data Warehouse
Differential Storage: A Key Building Block For A DuckDB-Based Data Warehouse
- 16 min read
BY- 16 min read
BYFor those acquainted with graph databases, the initial challenge is preparing data for graph querying. This involves complex ETL processes, new database setups and various technical hurdles that can be daunting, even for enthusiasts. Meanwhile, newcomers to graph technology look forward to exploring the advantages of performant graph queries, which offer capabilities beyond traditional SQL infrastructures.
With their unique approach to data relationships, graph databases seem intimidating to many SQL developers due to their perceived deployment complexity. Consequently, the potential to leverage graph querying remains untapped, mainly in environments where SQL databases prevail.
This discussion marks the beginning of a collaborative era between SQL and graph technologies. By integrating MotherDuck (and DuckDB), an in-process SQL OLAP data warehouse, with PuppyGraph, a graph query engine, SQL developers can seamlessly incorporate graph querying into their existing data stores. This article will cover the foundational concepts of graph databases and compare the benefits of graph versus SQL querying. We will also examine the practical challenges of implementing graph technology and how PuppyGraph offers a solution with its graph query engine. Finally, readers can see DuckDB and PuppyGraph in action through a hands-on SQL tutorial demonstrating how they can be combined to enable graph functionality efficiently. With this groundwork laid, let's start by looking at the essentials!
As the name implies, a graph database is built to manage data structured as a graph. This differs from the familiar setup of relational databases, which organize data into tables and rows. In a graph database, the data is represented through nodes and edges: nodes usually represent entities like individuals, companies, or any item you could catalog in a database, while edges denote the connections between these entities. This design enables a more intuitive depiction of the intricate relationships inherent in data.
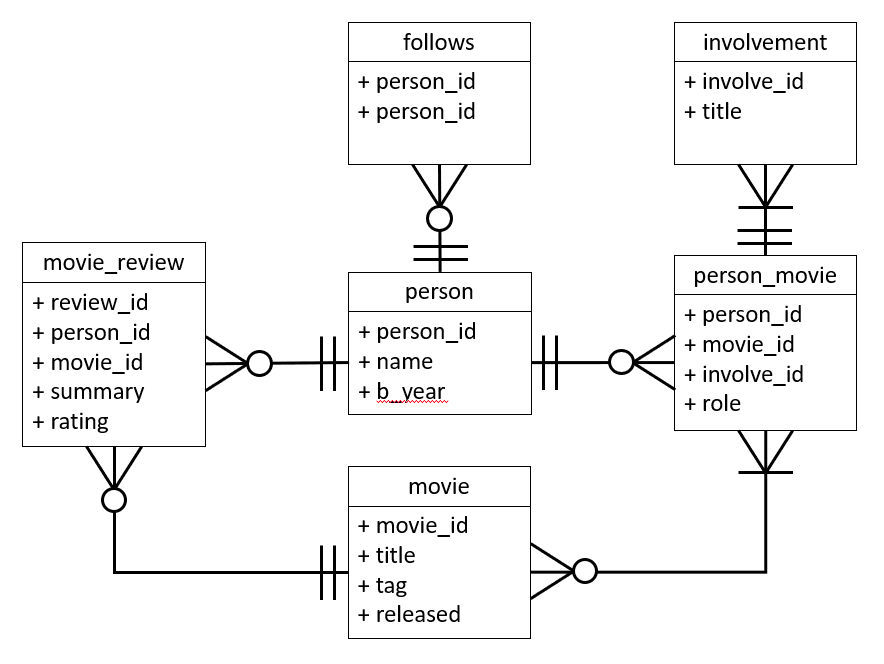 Credit: Entity Relationship data model for movie graph from FreeCodeCamp
Credit: Entity Relationship data model for movie graph from FreeCodeCamp
Graph databases genuinely excel in environments where the emphasis is on the relationships and networks within the data. They facilitate queries that navigate these connections, often uncovering insights that might be challenging or overly complex to extract via standard SQL queries. With their ability to elegantly map out complex relational dynamics, graph databases emerge as a potent resource for developers navigating elaborate hierarchies, networks or interlinked datasets.
SQL and graph queries bring unique strengths to the table, depending on the data's nature and the insights to be extracted. While SQL querying is second nature to many developers due to its widespread use and logical approach to datasets, graph querying can become equally intuitive with some knowledge and practice. Let's explore the key differences between these methodologies.
Graph query languages are tailor-made for effortlessly navigating interconnected data. They shine in scenarios where relationships are complex and densely woven, offering syntax that simplifies exploring these connections. Conversely, SQL queries can be challenging to represent and interrogate such data without resorting to multiple, often complex, joins across several tables. For instance, identifying the shortest path between two nodes in a social network—a task effortlessly handled by graph queries through algorithms like Breadth-First Search (BFS)—would be more complex and less efficient using SQL.
In recommendation engines, graph queries demonstrate a clear advantage by swiftly pinpointing the links between users, products, interests, and features, facilitating nuanced recommendations based on rich, multilayered relational data. With its reliance on joins and subqueries, SQL may need help with the complexity and scale of such tasks.
Graph queries also excel in fraud detection, spotting unusual patterns indicative of fraudulent behavior such as an unexpected transaction surge among a specific set of nodes. This capability for real-time, pattern-based analysis is something SQL databases, which may falter when patterns span multiple tables requiring immediate scrutiny, typically cannot match.
However, SQL queries often prevail in simplicity and efficiency for datasets with straightforward, tabular relationships. They are particularly effective for aggregate functions, such as tallying transactions per user, where the data's relational structure is less intricate. The mature ecosystem surrounding SQL databases, with a vast array of analytical tools and a robust user community, underscores its enduring popularity for conventional data storage and querying needs. Although SQL has historically dominated data management, graph databases gradually enhance connectivity and support, bridging the gap.
In a nutshell, while graph queries excel in navigating complex, deeply interconnected networks of data, SQL queries are the go-to for analyzing structured data with transparent, table-like relationships. The choice between graph and SQL queries hinges on the data type and the specific insights desired, underscoring the importance of deciding on right tool for the task. For those considering a potential implementation of a graph database to enable graph querying, we will later cover some of the related challenges and propose alternatives like using a graph query engine.
MotherDuck emerged from a vision to create a serverless, managed cloud version of DuckDB, inspired by co-founder Jordan Tigani's experience and the gap he saw in the market for an accessible, robust and inexpensive analytics database. It represents a collaboration between industry veterans and DuckDB Labs to simplify data analysis and make querying effortless by providing a cloud-based service for the vast majority of companies that do not have Petabyte-scale datasets.
PuppyGraph is a Graph Query Engine that allows developers to enable graph capabilities on one or more of their SQL data stores. The result is that users can perform graph queries on their existing data without complex ETL processes. PuppyGraph supports a variety of data storage systems, including DuckDB. Support is also available for Apache Hudi, Delta Lake, Apache Hive, and many other SQL databases. The platform provides easy integration and, within minutes, allows users to leverage Apache Gremlin and openCypher query languages against their SQL data.
Lightning-fast query speeds, faster than traditional graph databases, are enabled by high-performance auto-sharding. Offering scalability and low-latency responses to even the most complex queries (10 hop queries returning in 2 seconds). Data management is also streamlined since PuppyGraph requires no ETL to move data from a SQL source to a graph database target. This means no ETL pipelines to maintain and no additional persistent data copies. The cherry on top is that PuppyGraph operates within your own data center or cloud infrastructure, ensuring complete control and adherence to any data governance policies you must enforce.
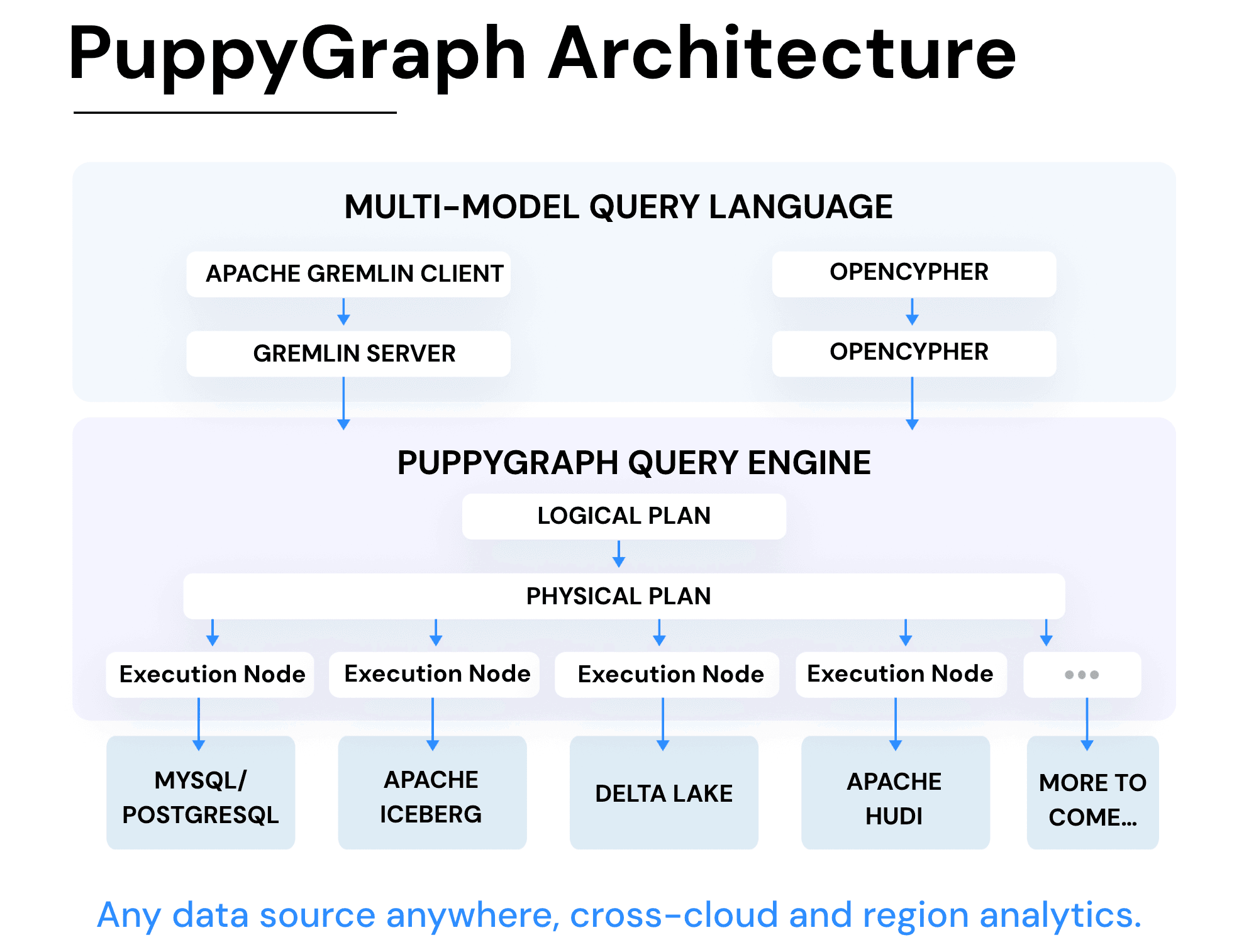 Credit: PuppyGraph Architecture
Credit: PuppyGraph Architecture
Is it possible to execute graph queries within a SQL data warehouse? Absolutely! The approach you choose, however, can significantly influence the ease and speed with which you can turn this possibility into reality. There are primarily two methods: a traditional one involving extensive ETL processes and graph databases and a more contemporary method utilizing a graph query engine like PuppyGraph. Let’s examine these two methodologies.
Traditionally, to harness graph queries from data stored in SQL databases, one had to navigate the complex route of extracting, transforming, and loading (ETL) the data into a graph database. This route is often fraught with challenges, requiring developing and managing intricate ETL pipelines to morph relational data into graph-compatible formats of nodes, edges, and properties. Utilizing specialized graph query languages like Cypher or Gremlin becomes possible only after the data resides in a graph database. This entails navigating the differences in optimization strategies and storage mechanisms inherent to graph databases. The complexity and effort required for this transition partly explain the rarity of running graph queries on SQL databases.
With these challenges in mind, graph query engines like PuppyGraph have revolutionized the field to make graph queries more accessible. The main selling point is negating the need to deploy and maintain complex ETL processes that are usually the crux of implementing a graph solution. PuppyGraph allows for the direct execution of graph queries on data within SQL data warehouses, serving as a bridge that treats tabular data as if it were a graph. This innovation not only simplifies the execution of graph operations on existing SQL datasets but also avoids the pitfalls associated with data duplication and the traditional ETL journey.
PuppyGraph’s compatibility with various data storage solutions, including SQL-centric systems such as DuckDB, paves the way for leveraging graph query capabilities without overhauling existing data infrastructure. This approach is particularly beneficial for applications requiring network analysis, complex data hierarchies, and other graph-intensive operations while sidestepping the resource-intensive demands of managing a separate graph database and its ETL pipelines.
For those seeking the analytical depth of graph queries, engines like PuppyGraph offer a streamlined path to integrating graph analytics within SQL data environments. This development is a significant leap forward for companies that previously viewed graph capabilities as overly complex or out of reach, bridging the gap between the structured world of SQL and the interconnected realm of graph querying and analytics.
Graph databases offer unparalleled advantages in analyzing complex relationships and networks, but their adoption has yet to match SQL databases. The journey to fully harnessing graph technology comes with its hurdles. Here's a closer look at these challenges:
The leap from traditional relational databases to graph databases requires a fundamental change in approach to data architecture, which can be daunting. Graph databases focus on relationships, demanding a shift from SQL to graph-specific queries. This new way of thinking and general unfamiliarity with graph technology's benefits can create a roadblock for even the most enthusiastic developers and hinder convincing stakeholders of a graph solution's value.
Graph databases face notorious challenges in scaling. The complexity of the data, characterized by an expanding web of nodes and edges, introduces computational and horizontal scaling challenges not found in SQL databases. The dense interconnectivity means that adding more hardware doesn't guarantee improved performance, often requiring reevaluating the graph model or more advanced scaling strategies.
Transitioning data from SQL databases to graph formats involves intricate ETL processes that are both resource-intensive and time-consuming to establish and maintain. This necessitates specialized expertise and continuous effort to ensure the graph database remains responsive and up-to-date as data evolves.
The infrastructure setup, data mapping and ongoing maintenance of graph databases demand significant resources and time, often more so than traditional databases. Graph data modeling presents complexities, translating to higher costs and longer development timelines.
Graph databases require specialized tooling that supports unique graph operations, creating a gap with existing SQL tools and infrastructure. This often leads to additional investment in new tools and training, further complicating integration and adoption efforts.
Effective use of graph databases necessitates a solid grasp of graph theory and the specific architectures of graph databases, and this knowledge is not as widespread as the familiarity of relational databases. This expertise gap can be a significant entry barrier for many teams.
While graph databases unlock powerful analytical capabilities, navigating their implementation and scaling intricacies presents considerable challenges. However, alternatives like graph query engines offer a path to accessing graph analytics without these extensive hurdles.
PuppyGraph presents an innovative solution to the challenges traditionally associated with graph databases by allowing users to run graph queries directly on SQL data warehouses. This functionality comes without the need for complex ETL processes or a separate graph database. This approach significantly reduces the learning curve, as developers can continue using familiar SQL queries alongside new graph operations. Scaling becomes more straightforward, leveraging the inherent scalability of the underlying SQL infrastructure. PuppyGraph eliminates the need for specialized graph database tooling and extensive resources for maintenance and scaling, making graph analytics accessible to teams without deep expertise in graph theory. By simplifying the integration of graph capabilities into existing data architectures, PuppyGraph enables organizations to harness the power of graph analytics with minimal disruption and investment.
To see it in action, let's walk through a deep dive, step-by-step tutorial!
In this tutorial, we will use DuckDB and PuppyGraph to analyze a dataset of Twitch gamers.
The dataset is available at SNAP. The project is located here.
The dataset contains sampled twitch gamer accounts as well as the mutual follower relationships between them.
In order to start, download the data from SNAP and unzip the data.
Copy code
wget https://snap.stanford.edu/data/twitch_gamers.zip
unzip twitch_gamers.zip -d twitch_gamers
The folder should contain the following files.
Copy code
$ ls twitch_gamers
README.txt large_twitch_edges.csv large_twitch_features.csv
Install the DuckDB CLI if not yet from the official website. Then start duckdb and create a new persisted database twitch_gamers.db.
Copy code
duckdb twitch_gamers.db
We will build the tables from the following scripts. Run the following SQL in the DuckDB CLI.
Copy code
CREATE TEMP TABLE features_raw AS
SELECT * FROM read_csv_auto('./twitch_gamers/large_twitch_features.csv');
CREATE TEMP TABLE edges_raw AS
SELECT * FROM read_csv_auto('./twitch_gamers/large_twitch_edges.csv');
CREATE TABLE features AS
SELECT numeric_id, views, life_time, created_at, updated_at, language,
mature::bool AS mature, dead_account::bool AS dead_account, affiliate::bool AS affiliate from features_raw;
CREATE OR REPLACE SEQUENCE id_sequence START 1;
CREATE TABLE edges (id bigint, follower bigint, followee bigint);
INSERT INTO edges SELECT nextval('id_sequence') as id, numeric_id_1 as follower, numeric_id_2 as followee FROM edges_raw;
Now that we have loaded data into DuckDB, let's query the tables we just created.
Copy code
D select count(*) from edges;
┌──────────────┐
│ count_star() │
│ int64 │
├──────────────┤
│ 6797557 │
└──────────────┘
D select count(*) from features;
┌──────────────┐
│ count_star() │
│ int64 │
├──────────────┤
│ 168114 │
└──────────────┘
D select count(*) from features where dead_account;
┌──────────────┐
│ count_star() │
│ int64 │
├──────────────┤
│ 5159 │
└──────────────┘
D select * from features order by updated_at limit 5;
┌────────────┬───────┬───────────┬────────────┬────────────┬──────────┬─────────┬──────────────┬───────────┐
│ numeric_id │ views │ life_time │ created_at │ updated_at │ language │ mature │ dead_account │ affiliate │
│ int64 │ int64 │ int64 │ date │ date │ varchar │ boolean │ boolean │ boolean │
├────────────┼───────┼───────────┼────────────┼────────────┼──────────┼─────────┼──────────────┼───────────┤
│ 7017 │ 0 │ 266 │ 2012-12-22 │ 2013-09-14 │ OTHER │ false │ true │ false │
│ 140843 │ 0 │ 52 │ 2013-12-21 │ 2014-02-11 │ OTHER │ false │ true │ false │
│ 32194 │ 0 │ 506 │ 2012-10-04 │ 2014-02-22 │ OTHER │ false │ true │ false │
│ 111748 │ 0 │ 811 │ 2011-12-18 │ 2014-03-08 │ OTHER │ true │ true │ false │
│ 104409 │ 0 │ 414 │ 2013-03-19 │ 2014-05-07 │ OTHER │ false │ true │ false │
└────────────┴───────┴───────────┴────────────┴────────────┴──────────┴─────────┴──────────────┴───────────┘
D
Naturally, the accounts and their following relationships form a graph, and it would be fascinating to analyze them as a graph. PuppyGraph allows you to query the data in DuckDB as a graph without any ETL.
Let’s start a PuppyGraph instance using Docker.
Copy code
docker run -p 8081:8081 -p 8182:8182 -p 7687:7687 -e PUPPYGRAPH_PASSWORD=puppygraph123 -d \
--name puppy --rm -v ./twitch_gamers.db:/mnt/twitch_gamers.db puppygraph/puppygraph:0.9
PuppyGraph will be running at port 8081. Access localhost:8081 in the browser to access it.
Input the username puppygraph and password puppygraph123 to login.
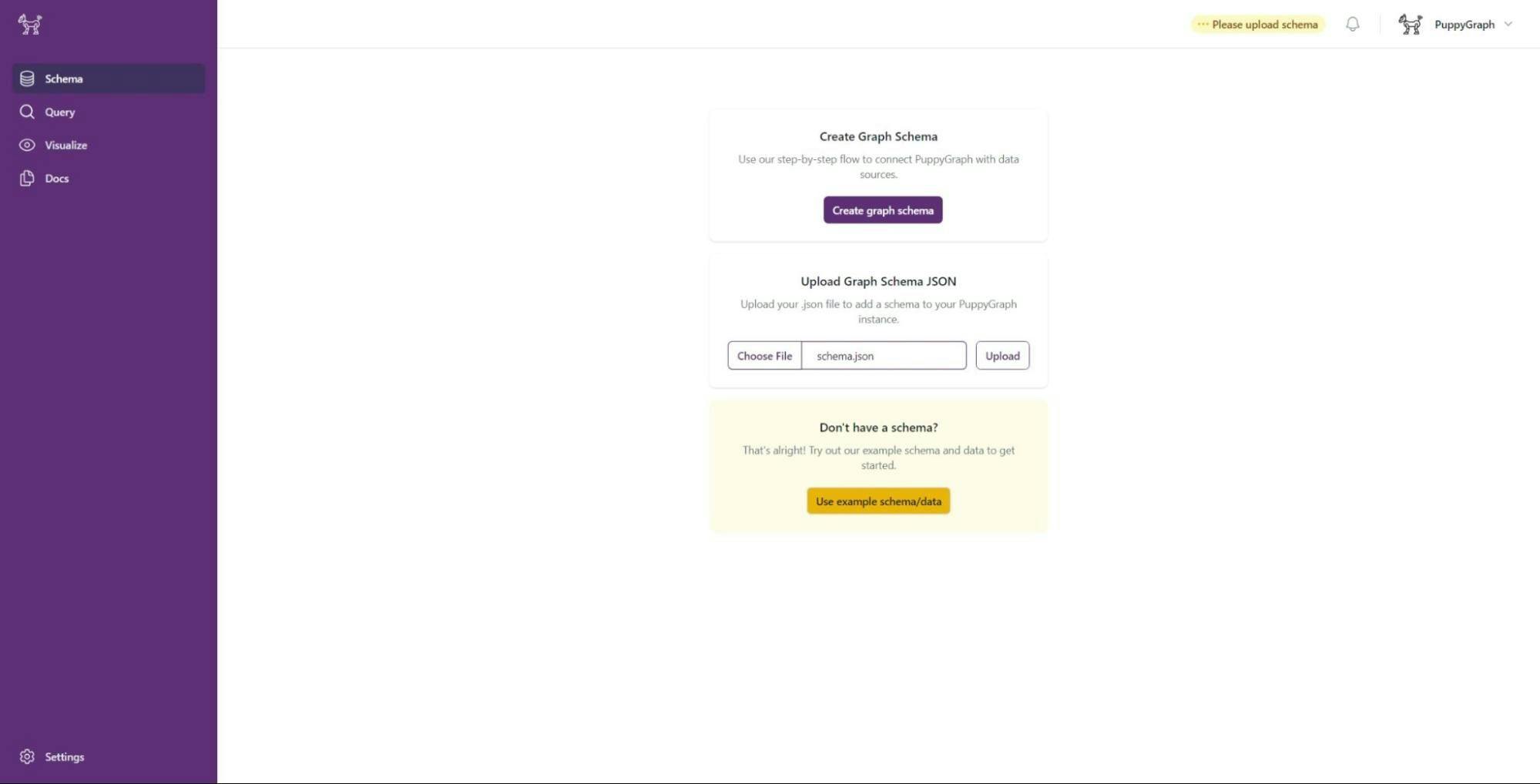
After logging in, the next step is to define a schema. This schema guides PuppyGraph in how to transform data from DuckDB into a graph structure for querying. PuppyGraph offers various methods for schema creation. For this tutorial, we've already prepared a schema to help save time.
Create a JSON file named schema.json to build the graph on top of the DuckDB instance. The schema is composed of various sections. The catalogs specify the data source, which, in our instance, is the DuckDB database we recently created. The vertices section outlines the entities within the graph, modeling gamers and their account attributes from the "features" table in this scenario. Meanwhile, the edge section instructs PuppyGraph to interpret relationships between these entities based on the "edges" table. Read this page to learn more about PuppyGraph schemas.
In the PuppyGraph UI, select “Upload Graph Schema JSON” and click “Upload”.
Copy code
{
"catalogs": [
{
"name": "gamers",
"type": "duckdb",
"jdbc": {
"jdbcUri": "jdbc:duckdb:/mnt/twitch_gamers.db",
"driverClass": "org.duckdb.DuckDBDriver"
}
}
],
"vertices": [
{
"label": "account",
"mappedTableSource": {
"catalog": "gamers",
"schema": "main",
"table": "features",
"metaFields": {"id": "numeric_id"}
},
"attributes": [
{ "type": "Long" , "name": "views" },
{ "type": "Long" , "name": "life_time" },
{ "type": "Date" , "name": "created_at" },
{ "type": "Date" , "name": "updated_at" },
{ "type": "String" , "name": "language" },
{ "type": "Boolean", "name": "mature" },
{ "type": "Boolean", "name": "dead_account" },
{ "type": "Boolean", "name": "affiliate" }
]
}
],
"edges": [
{
"label": "follows",
"mappedTableSource": {
"catalog": "gamers",
"schema": "main",
"table": "edges",
"metaFields": {"id": "id", "from": "follower", "to": "followee"}
},
"from": "account",
"to": "account",
"attributes": []
}
]
}
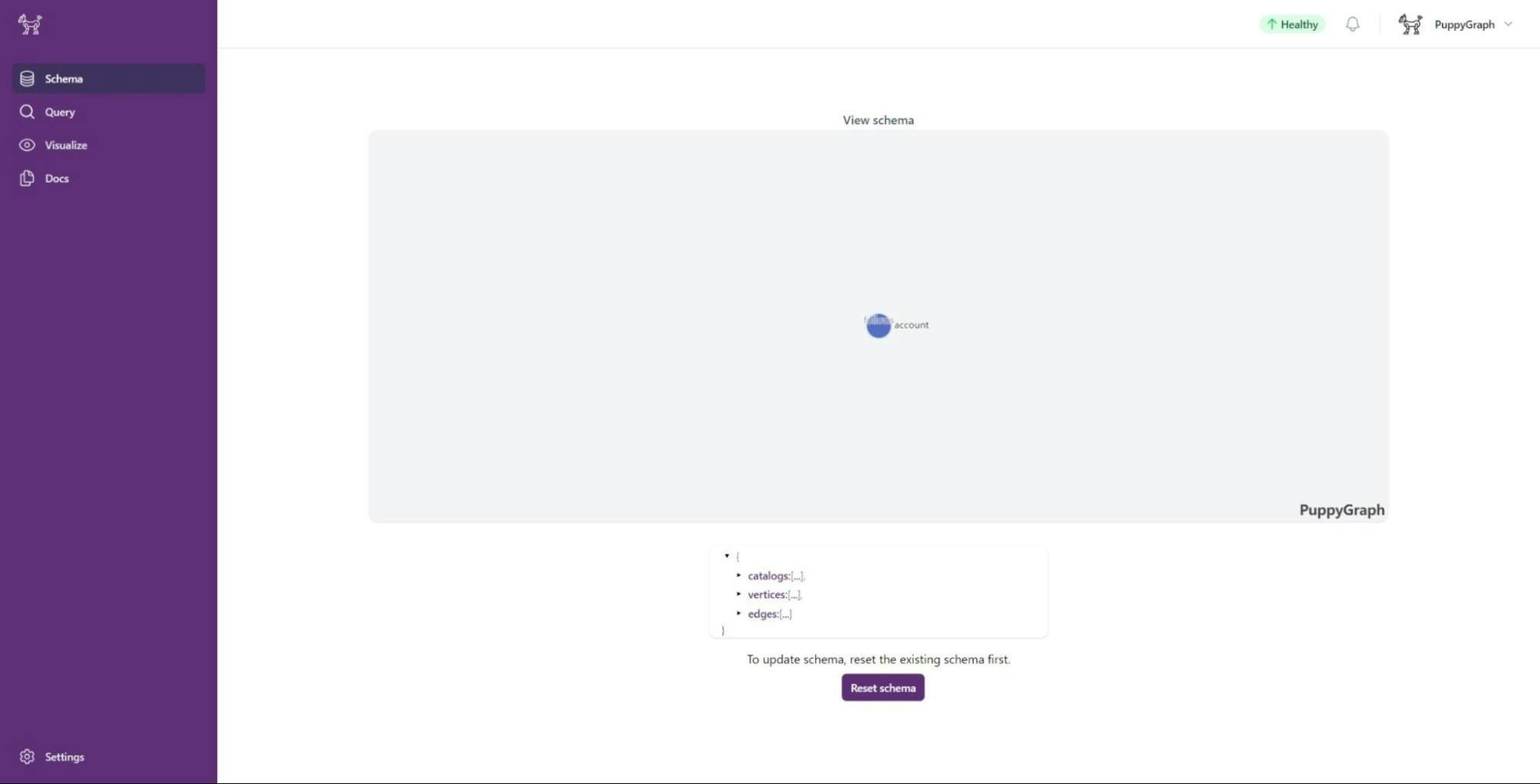
Once the JSON file uploads, PuppyGraph will visualize the graph schema.
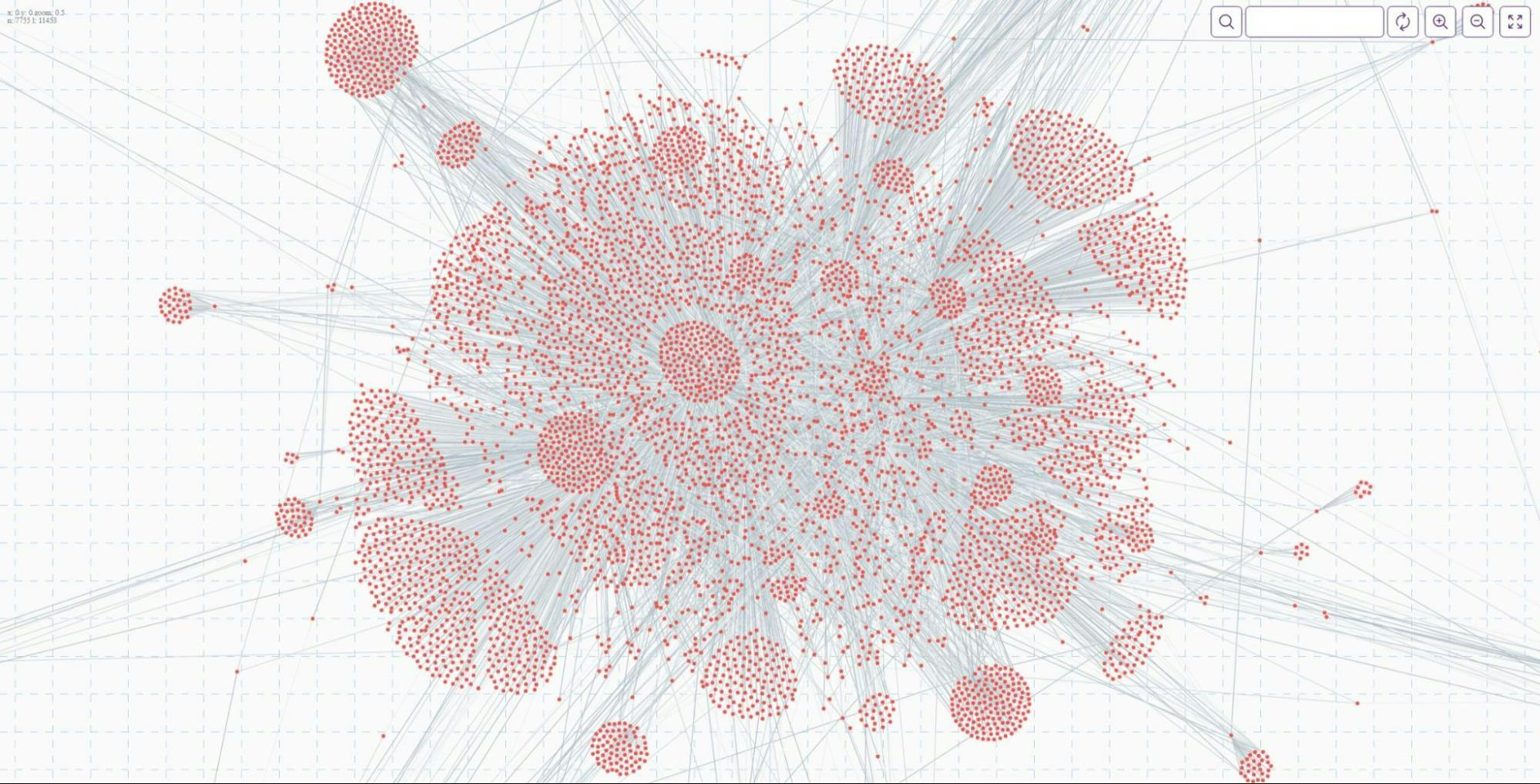
There is also a cool graph explorer that allows you to view the graph and get an initial impression of your data. Click “Visualize” on the left panel to access it. You can even view the graph full-screen!
We can now run queries on the Graph. Click “Query” on the left panel menu and choose Gremlin.
PuppyGraph supports Gremlin and openCypher. In this tutorial, we will use Gremlin.
We first get the top-5 accounts whose last update time was the earliest. This query is similar to the one we ran in DuckDB.
Copy code
puppy-gremlin> g.V().order().by('updated_at').limit(5).elementMap()
Done! Elapsed time: 0.039s, rows: 5
==>map[affiliate:false created_at:2012-12-22 dead_account:true id:account:::7017 label:account language:OTHER life_time:266 mature:false updated_at:2013-09-14 views:0]
==>map[affiliate:false created_at:2013-12-21 dead_account:true id:account:::140843 label:account language:OTHER life_time:52 mature:false updated_at:2014-02-11 views:0]
==>map[affiliate:false created_at:2012-10-04 dead_account:true id:account:::32194 label:account language:OTHER life_time:506 mature:false updated_at:2014-02-22 views:0]
==>map[affiliate:false created_at:2011-12-18 dead_account:true id:account:::111748 label:account language:OTHER life_time:811 mature:true updated_at:2014-03-08 views:0]
==>map[affiliate:false created_at:2013-03-19 dead_account:true id:account:::104409 label:account language:OTHER life_time:414 mature:false updated_at:2014-05-07 views:0]
Now we know that the account id account:::7017 was the one least recently updated. It is possible to get its followers with graph queries on the graph structure. Specifically, the following gremlin query checks top-5 viewed accounts among the 2-hop followers (followers of followers) of the account.
Copy code
puppy-gremlin> g.V('account:::7017').both().both().order().by('views', desc).limit(5).elementMap()
Done! Elapsed time: 0.499s, rows: 5
==>map[affiliate:false created_at:2011-05-20 dead_account:false id:account:::32338 label:account language:EN life_time:2702 mature:false updated_at:2018-10-12 views:202142952]
==>map[affiliate:false created_at:2007-06-28 dead_account:false id:account:::58773 label:account language:EN life_time:4124 mature:false updated_at:2018-10-12 views:25063546]
==>map[affiliate:false created_at:2011-04-14 dead_account:false id:account:::56352 label:account language:EN life_time:2738 mature:false updated_at:2018-10-12 views:21717613]
==>map[affiliate:false created_at:2015-01-18 dead_account:false id:account:::94108 label:account language:EN life_time:1363 mature:false updated_at:2018-10-12 views:12124358]
==>map[affiliate:false created_at:2011-05-30 dead_account:false id:account:::131835 label:account language:EN life_time:2691 mature:true updated_at:2018-10-11 views:4202097]
The landscape of data management is being transformed through the introduction of graph analytics. Graph databases, while powerful, often present a steep learning curve and technical challenges such as complex ETL processes and the need for new database setups.
However, through our partnership, PuppyGraph and DuckDB simplify these challenges, enabling SQL developers to seamlessly perform graph queries within their existing data stores, no separate graph database required. This harmonious integration not only opens up new avenues for performant graph queries, but it also maintains the simplicity of data management by leveraging existing permissions to democratize access to advanced data analysis techniques.
Ready to get started? Download the forever free PuppyGraph Developer Edition and sign up for a free MotherDuck account to create your first graph model in minutes.
2024/03/11 - Joseph Hwang
Differential Storage: A Key Building Block For A DuckDB-Based Data Warehouse

2024/03/22 - Mehdi Ouazza
Learn how to build a production-ready data pipeline using dbt and DuckDB. Discover how to configure the dbt-duckdb adapter for local and cloud workflows.