From Data Lake to Lakehouse: Can DuckDB be the best portable data catalog?
2024/11/14 - 13 min read
BYData Lake and Lakehouse are topics that are highly discussed at the moment. This is because it's much easier and cost-effective to have central storage in object storage and be free of which compute engine you want to use against it. However, many people forget an essential part of the story: the catalog. Over the past few years, it has become more critical.
But what is a data catalog, anyway?
In this blog, we'll cover definitions and highlight some patterns around Data Lake and Lakehouse to understand why data catalogs have gained a central place in today’s data stack. Finally, we’ll end up with some code around a pragmatic use case on leveraging DuckDB (and MotherDuck) as a portable catalog.
Definition
Drawing inspiration from a great blog by Jeremiah Hansen , we can break catalogs into two main categories :
- Data governance catalog: Informational, helps for centrally defined governance policies across different databases and searchable metadata.
- Database object catalog: Operational, used directly by data platforms and query engines to read and write data, often also referred to as metastores.
While informational catalogs can be used for operational purposes, these definitions clarify how they relate to databases or query engines. An operational catalog is used directly by the engine to query data, whereas an informational catalog is accessed by people for documentation and dataset discovery. Sometimes, the distinction between the two categories can blur, and features from one may appear in the other.
Why are data catalogs essential for future data platforms?
In the past, data systems combined storage and computing, and the catalog was just a built-in feature. For example, if you were using Oracle for your analytics, you couldn't switch to a different compute engine. Storage, compute, and catalog were all stitched together.
Since the time of Hadoop, we've begun to separate storage and computing. The Hive metastore was the first open catalog to emerge from this change. With strategies like Data Lake and Lakehouse, we've adopted open file formats (like Parquet and Avro) and, more recently, table formats like Delta Lake, Iceberg, and Hudi. These new formats introduce features like ACID properties and others, including schema evolution and deletes.
Data Lake vs Lakehouse?
A Data Lake is a centralized storage solution that holds raw data in its original format (CSV, Parquet, JSON, etc), leveraging classic object storage like AWS S3. A Lakehouse builds on this by adding table formats like Delta Lake or Iceberg, enabling features like ACID transactions and schema management while still using classic object storage.
A Data Lake is a centralized storage solution that holds raw data in its original format (CSV, Parquet, JSON, etc), leveraging classic object storage like AWS S3. A Lakehouse builds on this by adding table formats like Delta Lake or Iceberg, enabling features like ACID transactions and schema management while still using classic object storage.
As we separate storage from computing, we need a shared and open place to manage our table states in our Data Lake.
Let's take a simple example to understand why having a catalog is so important.
Simple scan
When using a Parquet Data Lake, managing the catalog was relatively straightforward. Since Parquet files are immutable, meaning they cannot be changed, you simply scan all the Parquet files needed to represent a table.
Given the following files over an object storage :
Copy code
/my_table/file1.parquet /my_table/file2.parquet
The contents of my_table would be the total of the data from the Parquet files file1.parquet and file2.parquet. If there were updates or deletions of rows to the data, new Parquet files would replace the old ones, and all we’d have to do is scan them again.
For the compute engine, the task is simple: just read all the Parquet files.
Therefore, query engines over Parquet Data Lake can work in two ways :
- Through catalog interaction: interact with the catalog, which organizes all the data, so they don’t need to worry about the file locations - this is provided by the catalog.
- Through direct scanning: they can directly scan the Parquet files stored in object storage using their base path location.
In short, when using such a query engine, one could do the following:
Copy code
SELECT * FROM my_table -- the catalog will share the file paths
SELECT * FROM './my_table/*.parquet' -- the query engine is scanning the parquet files at a given location.
Super-charged Parquet Files
Table formats like Delta Lake and Apache Iceberg, unlike vanilla Parquet files, support operations like UPDATE and DELETE. These formats are also designed to reduce the amount of computing needed when accessing stored data.
Here's how they work: these table formats are still based on Parquet files, but they include additional metadata files.
Let's say we make a UPDATE or DELETE; instead of having to rewrite entire files, the query engine simply adds a line to a metadata file, usually in JSON format.
Here's what a Delta Lake folder might look like:
Copy code
/my_table/ _delta_log 00.json 01.json n.json /my_table/ file1.parquet file2.parquet
But here’s where it gets a bit complex compared to vanilla Parquet.
If you just scan the data from file1.parquet and file2.parquet after our UPDATE or DELETE transaction, you might not see the table's current correct state. These UPDATE or DELETE operations might have occurred, and the information about this operation is stored in *.json without changing the actual Parquet files!
Because of this, our query engines must use the catalog to understand the correct current state of the table.
Catalogs have become critical when working with these advanced table formats.
Another way would be to have the query engine decode these metadata files and represent the correct view. However, this pushes the complexity back to the query engine.
DuckDB file format
DuckDB has its own file format. It's storage efficient and supports ACID transactions. It's one file that contains all tables, data... and metadata.
As DuckDB can interact with many databases (Postgres, MySQL) and File formats (Parquet, CSV, Delta Lake, Apache Iceberg), would it be local or over object storage (AWS S3, Azure Blob Storage, etc.) it is, therefore, a great candidate for a portable catalog.
Working with data, especially when doing data wrangling or one-shot analysis, can be a messy journey.
Anyone working in data has probably experienced this at least once in their life:
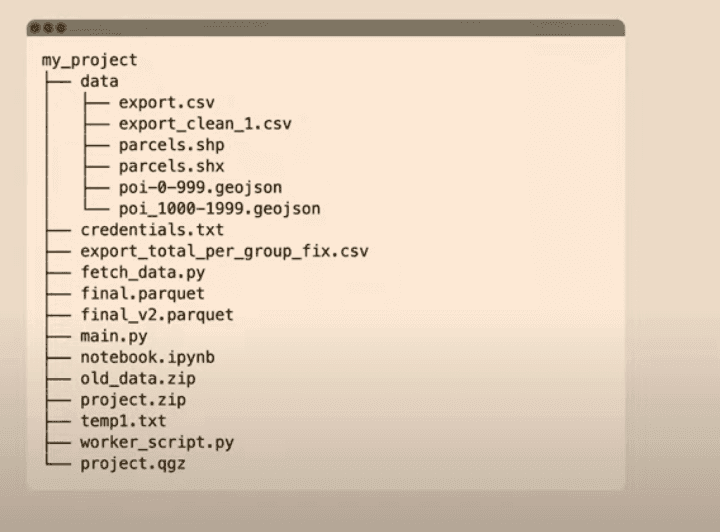
Image Author : Max Gabrielsson from his great talk at GeoPython
You could share all metadata information ready to be queried with DuckDB but without the actual data itself. Authentification will be relayed over if you have access to the data (e.g. right IAM role to query AWS S3 data). And you still keep a good lineage as you'll have the source data location.
So, let's get our hands dirty with some practical examples.
DuckDB and MotherDuck as a portable data catalog
Let's start with the DuckDB file ducky_catalog.ddb. You can follow along by running the above commands in a DuckDB client, as the link comes from a public bucket.
I'll use the DuckDB CLI; check our documentation for setup instructions.
First I’ll load the database using the ATTACH command.
Copy code
ATTACH 's3://us-prd-motherduck-open-datasets/content/duckdb-as-catalog/ducky_catalog.ddb';
Here’s the list of tables:
Copy code
D SHOW tables;
┌─────────────┐
│ name │
│ varchar │
├─────────────┤
│ air_quality │
│ customers │
│ ducks │
│ lineitem │
└─────────────┘
The total data size of these tables are roughly 15MB... but the DuckDB file size :
Copy code
-rw-r--r--@ 1 mehdio staff 268K Nov 11 11:39 ducky_catalog.ddb
Only 268KB!? What’s happening here?
The DuckDB file contains all the metadata, but no data is stored. Yet, you can query these tables as if they were regular tables.
Copy code
D FROM customers limit 5;
┌───────────┬────────────────────┬──────────────────────┬───┬──────────────┬──────────────────────┐
│ c_custkey │ c_name │ c_address │ … │ c_mktsegment │ c_comment │
│ int64 │ varchar │ varchar │ │ varchar │ varchar │
├───────────┼────────────────────┼──────────────────────┼───┼──────────────┼──────────────────────┤
│ 1 │ Customer#000000001 │ j5JsirBM9PsCy0O1m │ … │ BUILDING │ y final requests w… │
│ 2 │ Customer#000000002 │ 487LW1dovn6Q4dMVym… │ … │ AUTOMOBILE │ y carefully regula… │
│ 3 │ Customer#000000003 │ fkRGN8nY4pkE │ … │ AUTOMOBILE │ fully. carefully s… │
│ 4 │ Customer#000000004 │ 4u58h fqkyE │ … │ MACHINERY │ sublate. fluffily… │
│ 5 │ Customer#000000005 │ hwBtxkoBF qSW4KrIk… │ … │ HOUSEHOLD │ equests haggle fur… │
├───────────┴────────────────────┴──────────────────────┴───┴──────────────┴──────────────────────┤
│ 5 rows 8 columns (5 shown) │
└─────────────────────────────────────────────────────────────────────────────────────────────────┘
D
Even more interesting, the data is stored as follows:
air_quality: Parquet file stored on AWS S3lineitem: Iceberg table stored on Google Cloud Storagecustomers: A folder of multiple CSVs stored on AWS S3ducks: A table from a Neon-hosted Postgres database, using the Postgres extension

This setup is extreme and just for demonstration purposes. How does this work? We use DuckDB VIEWS.
You can list the VIEW definitions like this:
Copy code
D SELECT sql FROM duckdb_views() where temporary=false;
┌───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ sql │
│ varchar │
├───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┤
│ CREATE VIEW air_quality AS SELECT * FROM "s3://us-prd-motherduck-open-datasets/content/duckdb-as-catalog/who_ambient_air_quality_database_version_v6_april_… │
│ CREATE VIEW customers AS SELECT * FROM "s3://us-prd-motherduck-open-datasets/content/duckdb-as-catalog/customer/*.csv"; │
│ CREATE VIEW ducks AS SELECT * FROM postgres_scan((((((((('dbname=' || getenv('PGDATABASE')) || ' host=') || getenv('PGHOST')) || ' user=') || getenv('PGUSE… │
│ CREATE VIEW lineitem AS SELECT * FROM iceberg_scan('gs://prd-motherduck-open-datasets/line_item_iceberg', (allow_moved_paths = CAST('t' AS BOOLEAN))); │
└─────────────────
Managing secrets
In the example, except for the Postgres table, the buckets on Google Cloud and AWS are public. But of course, it also works with private buckets, requiring the reader to have the correct IAM role to access them.
Using DuckDB's Secret Manager, you can securely manage secrets based on your SSO setup.
Let's log in through AWS using the CLI and sso mechanism. I
Copy code
aws sso login --profile my_duck_profile
Assuming AWS_DEFAULT_PROFILE is set to my_duck_profile, you can create a secret in DuckDB. If you are using plain AWS keys, you can use the CONFIG provider.
Copy code
CREATE SECRET secret3 (
TYPE S3,
PROVIDER CREDENTIAL_CHAIN,
CHAIN 'sso'
);
Note that you can do similar configurations for Google Cloud or databases like Postgres/MySQL, which DuckDB supports through secrets manager.
If you want to create a VIEW on a single table, you can do that through environment variables.
Assuming these environment variables are available :
Copy code
export PGHOST='my.host.address'
export PGDATABASE='ducks'
export PGUSER='my_user'
export PGPASSWORD='mypass'
You can create the VIEW on a Postgres table as follows:
Copy code
CREATE VIEW ducks AS
SELECT * FROM postgres_scan(
'dbname=' || getenv('PGDATABASE') ||
' host=' || getenv('PGHOST') ||
' user=' || getenv('PGUSER') ||
' password=' || getenv('PGPASSWORD') ||
' connect_timeout=10 sslmode=require',
'public',
'ducks'
);
With such a strategy, our DuckDB file ducky_catalog.ddb remains safe, as the user will still need to create secrets and have appropriate permissions to read the tables.
Syncing and sharing your catalog with MotherDuck
So far, we’ve used a local DuckDB file. However for managing permissions, sharing, and writing concurrency, a single binary file has limitations. MotherDuck supercharges DuckDB, providing storage and computing, and makes sharing databases easy.
Let's start again with our DuckDB file.
Copy code
ATTACH 's3://us-prd-motherduck-open-datasets/content/duckdb-as-catalog/ducky_catalog.ddb';
Moving from a local DuckDB database to MotherDuck is a simple two steps :
- Authenticate to MotherDuck using
- Upload the database
You can retrieve your motherduck_token and set it as an environment variable.
If not, the terminal will guide you through a web authentication flow when you run:
Copy code
ATTACH 'md:'
Then, upload your local database.
Copy code
D CREATE DATABASE cloud_ducky_catalog from ducky_catalog;
Run Time (s): real 1.373 user 0.465060 sys 0.008710
It's super fast to upload because, again, it's just metadata.
Once uploaded, you can also visit the MotherDuck UI to see all your views with their schema.
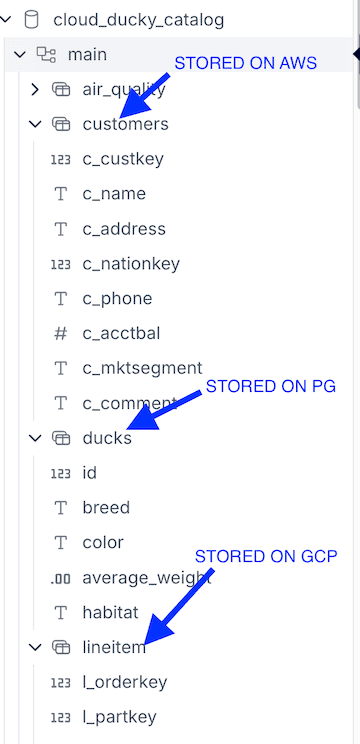
To create a public URL share:
Copy code
CREATE SHARE share_ducky_catalog from cloud_ducky_catalog (ACCESS UNRESTRICTED, VISIBILITY HIDDEN, UPDATE AUTOMATIC);
This allows you to:
- Share datasets across different cloud providers or databases with just an URL.
- Leverage cloud network bandwidth to speed up queries (for instance, between AWS buckets and MotherDuck compute).
- Manage database updates safely.
What's Next
DuckDB’s capabilities continue to grow, including experimental support for other data catalogs like Unity Catalog. An exciting GitHub discussion explores a MetaCatalog concept, where DuckDB could host child catalogs. Other potential features include materialized views or more flexible refresh mechanisms for views, similar to external tables in other systems. Of course, when creating VIEWS like we did, we won't achieve the same performance as with internal tables. It's a trade-off to keep in mind.
Can DuckDB be the best open portable catalog? We’ve seen it has already a serious potential as of today. For the rest, we have an exciting future ahead, full of possibilities!
In the meantime, keep quacking and keep coding.
Start using MotherDuck now!

