
2023/07/17 - Marcos Ortiz
This Month in the DuckDB Ecosystem: July 2023
DuckDB news: MotherDuck launches managed cloud service with hybrid execution. Apache Iceberg extension arrives. Vectorized Python UDFs added. DuckCon SF talks published.
- 8 min read
BY- 8 min read
BYDuckDB is not just a database — it’s also a data transformation engine. This post will explore how DuckDB and MotherDuck can transform data, mask sensitive PII information, detect anomalies in event-driven workflows, and streamline reporting use cases.
MotherDuck is a serverless DuckDB running in the cloud. While we’ll use MotherDuck in this post, everything shown here will also work on DuckDB on your local machine. Check the product launch announcement to learn more about MotherDuck and how to get access.
Let’s dive in!
Whether you use a data lake, data warehouse, or a mix of both, it’s common to first extract raw data from a source system and load it in its original format into a staging area, such as S3. The Python script below does just that — it extracts data from a source system and loads it to an S3 bucket:
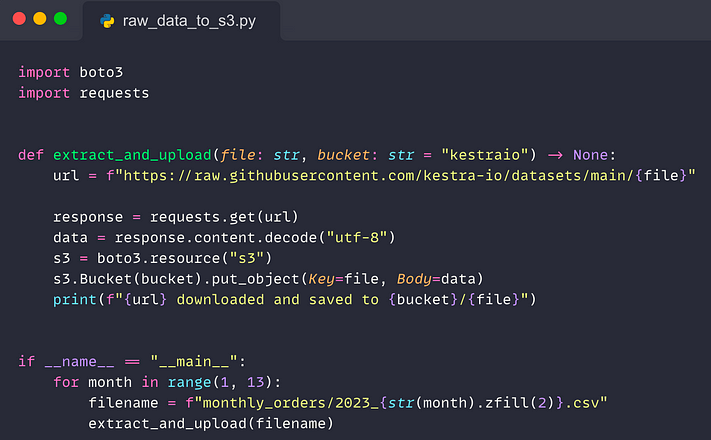
For reproducibility, this script loads data from a public GitHub repository to a private S3 bucket. In a real-world scenario, you would extract data from a production database rather than from GitHub.
This script ingests monthly orders with one CSV file per month. For reporting, we will need to consolidate that data.
Let’s say your task is to read all these S3 objects and generate a CSV report with the total order volume per month, showing the top-performing months first. This report should be sent via email to the relevant stakeholders every first day of the month.
When using a traditional data warehousing approach, you would need to create a table and define the schema. Then, you would load data to that table. Once data is in the warehouse, you can finally start writing analytical queries. This multi-step process might be a little too slow if all you need is to get a single report with monthly aggregates. Let’s simplify it with DuckDB.
DuckDB can read multiple files from S3, auto-detect the schema, and query data directly via HTTP. The code snippet below shows how DuckDB can simplify such reporting use cases.
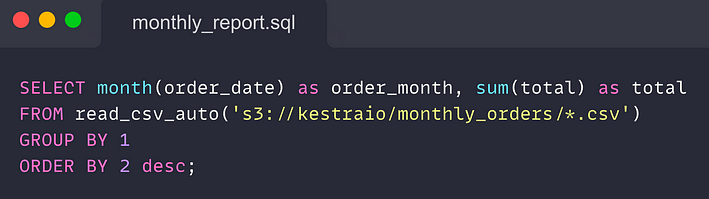
You can execute that SQL code anywhere you can run DuckDB — the CLI, Python code, or WASM as long as you provide your AWS S3 credentials and change the S3 path to point to your bucket.
Here is how you can securely handle S3 credentials in DuckDB:
Copy code
SET s3_region='us-east-1';
SET s3_secret_access_key='supersecret';
SET s3_access_key_id='xxx';
MotherDuck makes it even easier thanks to the notebook-like SQL environment from which you can add and centrally manage your AWS S3 credentials without having to hard-code them in your queries. By default, the query execution will also be routed to MotherDuck for better scalability. The image below shows how you can add S3 credentials (see the settings on the right side) and how you can create a MotherDuck table from a query reading S3 objects (see the catalog on the left side).

To send that final result as an email report and schedule it to run every first day of the month, you can leverage an open-source orchestration tool such as Kestra.
To get started with Kestra, download the Docker Compose file:
Copy code
curl -o docker-compose.yml https://raw.githubusercontent.com/kestra-io/kestra/develop/docker-compose.yml
Then, run docker compose up -d and launch http://localhost:8080 in your browser. Navigate to Blueprints and select the tag DuckDB to see example workflows using DuckDB and MotherDuck. The third Blueprint in the list contains the code for our current reporting use case:

Click on the Use button to create a flow from that blueprint. Then, you can save and execute that flow.
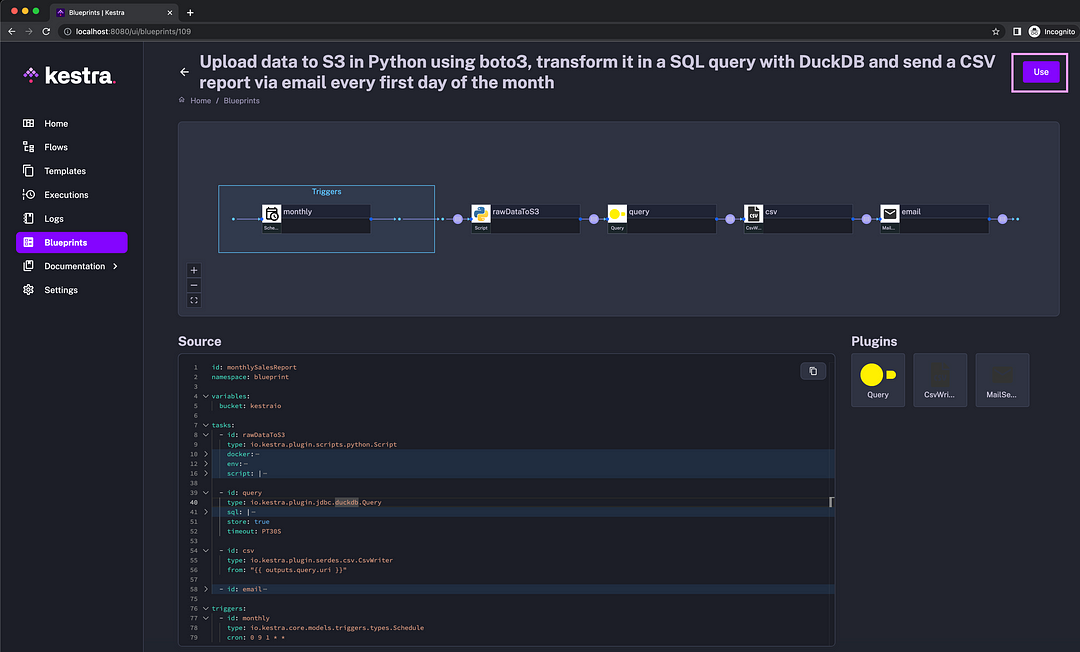
If you scroll down, the blueprint description at the bottom provides detailed instructions on how to use it for both DuckDB and MotherDuck.
MotherDuck adds several features to the vanilla DuckDB, including the following:
An orchestrator can help here for a number of reasons:
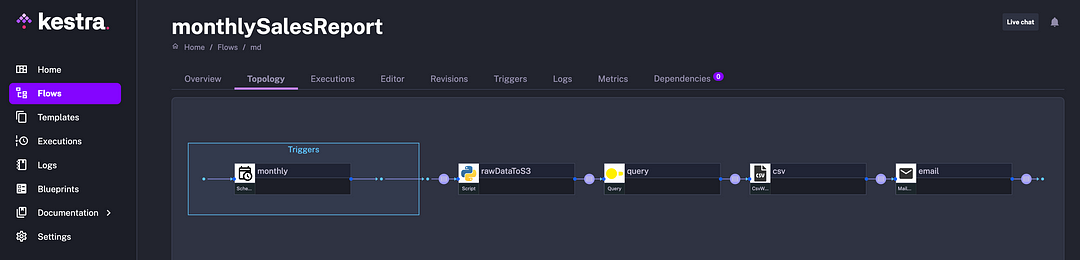
Here is a DAG view showing the structure of the process:
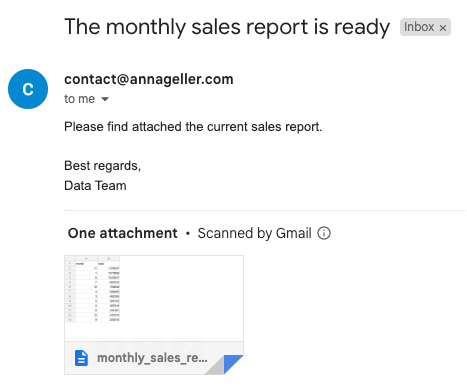
When the workflow finishes execution, the following email should be generated as a result:
Let’s move on to the next use cases.
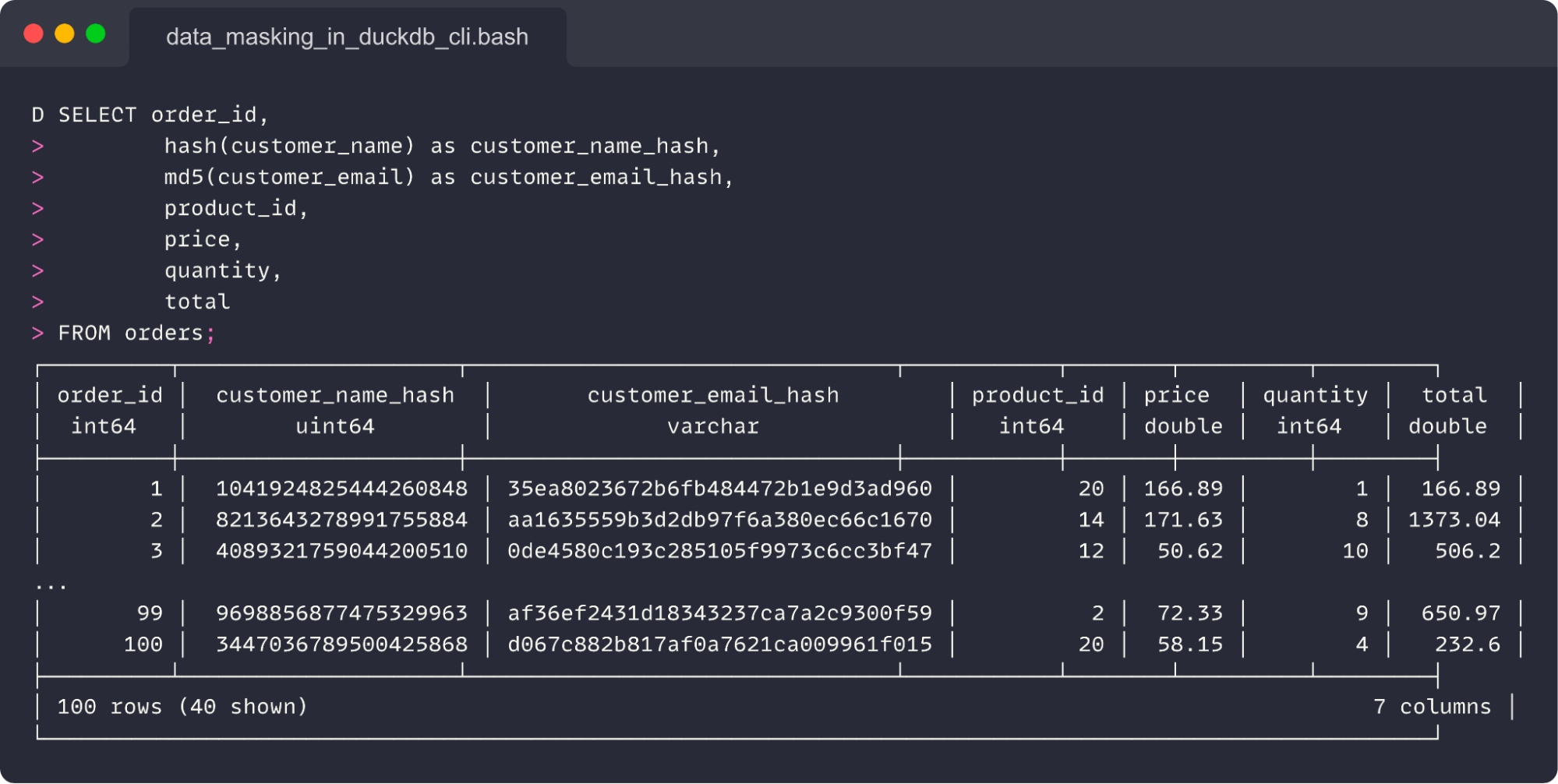
ETL pipelines usually move data between various applications and databases. Source systems often contain sensitive data that has to be masked before it can be ingested into a data warehouse or data lake. DuckDB provides hash() and md5() utility functions that can hash sensitive columns between the extract and load steps in a pipeline. The SQL query below obfuscates customer names and emails.
Copy code
CREATE TABLE orders AS
SELECT *
FROM read_csv_auto('https://raw.githubusercontent.com/kestra-io/examples/main/datasets/orders.csv');
SELECT order_id,
hash(customer_name) as customer_name_hash,
md5(customer_email) as customer_email_hash,
product_id,
price,
quantity,
total
FROM orders;
Here is the result of that query:
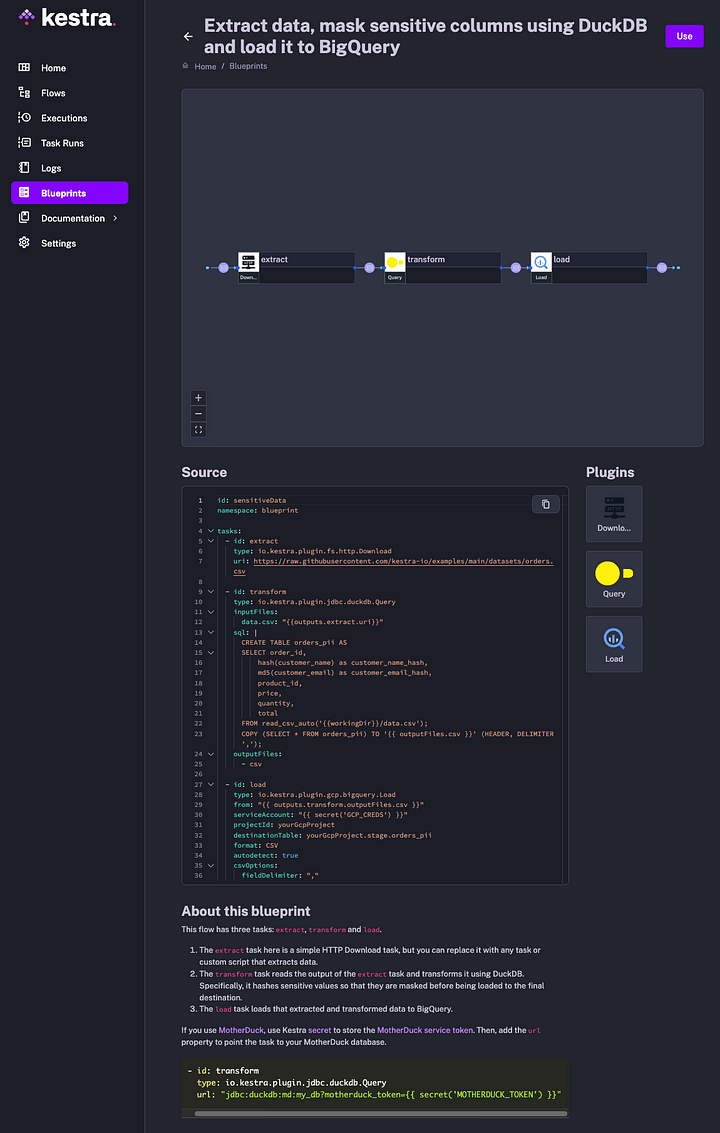
For a full workflow code, check the following blueprint. The flow extracts data from a source system. Then, it uses DuckDB for data masking. Finally, it loads data to BigQuery. Note that you can skip that load step when persisting data directly to MotherDuck.
In the same fashion as with data masking, DuckDB can serve as a lightweight (and often faster) alternative to Spark or Pandas for data transformations. You can leverage the dbt-duckdb package to transform data in SQL by using dbt and DuckDB together.
Switching between using DuckDB and MotherDuck in your dbt project is a matter of adjusting the profiles.yml file:
Copy code
# in-process duckdb
jaffle_shop:
outputs:
dev:
type: duckdb
path: ':memory:'
extensions:
- parquet
target: dev
# MotherDuck - the Secret macro below is specific to Kestra
jaffle_shop_md:
outputs:
dev:
type: duckdb
database: jaffle_shop
disable_transactions: true
threads: 4
path: |
md:?motherduck_token={{secret('MOTHERDUCK_TOKEN')}}
target: dev
There are two Kestra blueprints that you can use as a starting point:
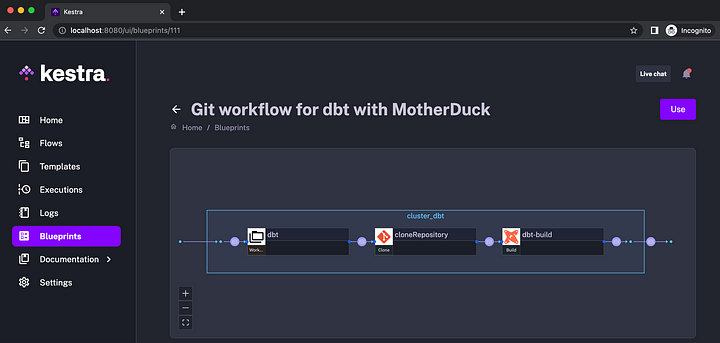
To use those workflows, adjust the Git repository and the branch name to point it to your dbt code. If you want to schedule it to run, e.g., every 15 minutes, you can add a schedule as follows:
Copy code
id: your_flow_name
namespace: dev
tasks:
- id: dbt
type: io.kestra.core.tasks.flows.WorkingDirectory
tasks:
- id: cloneRepository
type: io.kestra.plugin.git.Clone
url: https://github.com/dbt-labs/jaffle_shop_duckdb
branch: duckdb
- id: dbt-build
type: io.kestra.plugin.dbt.cli.Build
# dbt profile config...
triggers:
- id: every-15-minutes
type: io.kestra.core.models.triggers.types.Schedule
cron: "*/15 * * * *"
After you execute the flow, all dbt models and tests will be rendered in the UI so you can see their runtime and inspect the logs:
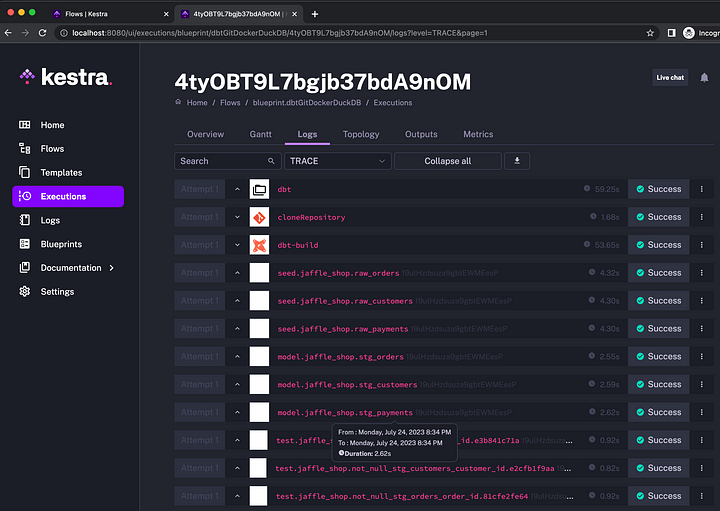
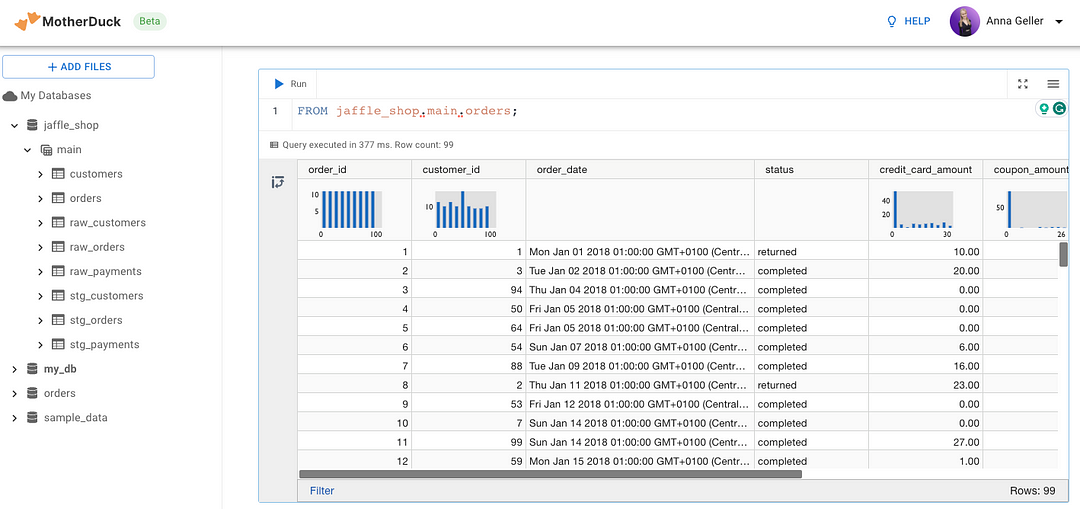
You can access the tables created as a result of the workflow in your MotherDuck SQL IDE:
So far, we’ve covered reporting and scheduled batch data pipelines. Let’s move on to event-driven use cases.
Scheduled batch pipelines can lead to slow time-to-value when dealing with near real-time data. Imagine that a data streaming service regularly delivers new objects to an S3 bucket, and you want some action to be triggered as soon as possible based on specific conditions in data. Combining DuckDB’s capabilities to query data stored in S3 with Kestra’s event triggers makes that process easy to accomplish.
The workflow below will send an email alert if new files detected in S3 have some anomalies. This workflow is available in the list of DuckDB Blueprints in the UI.
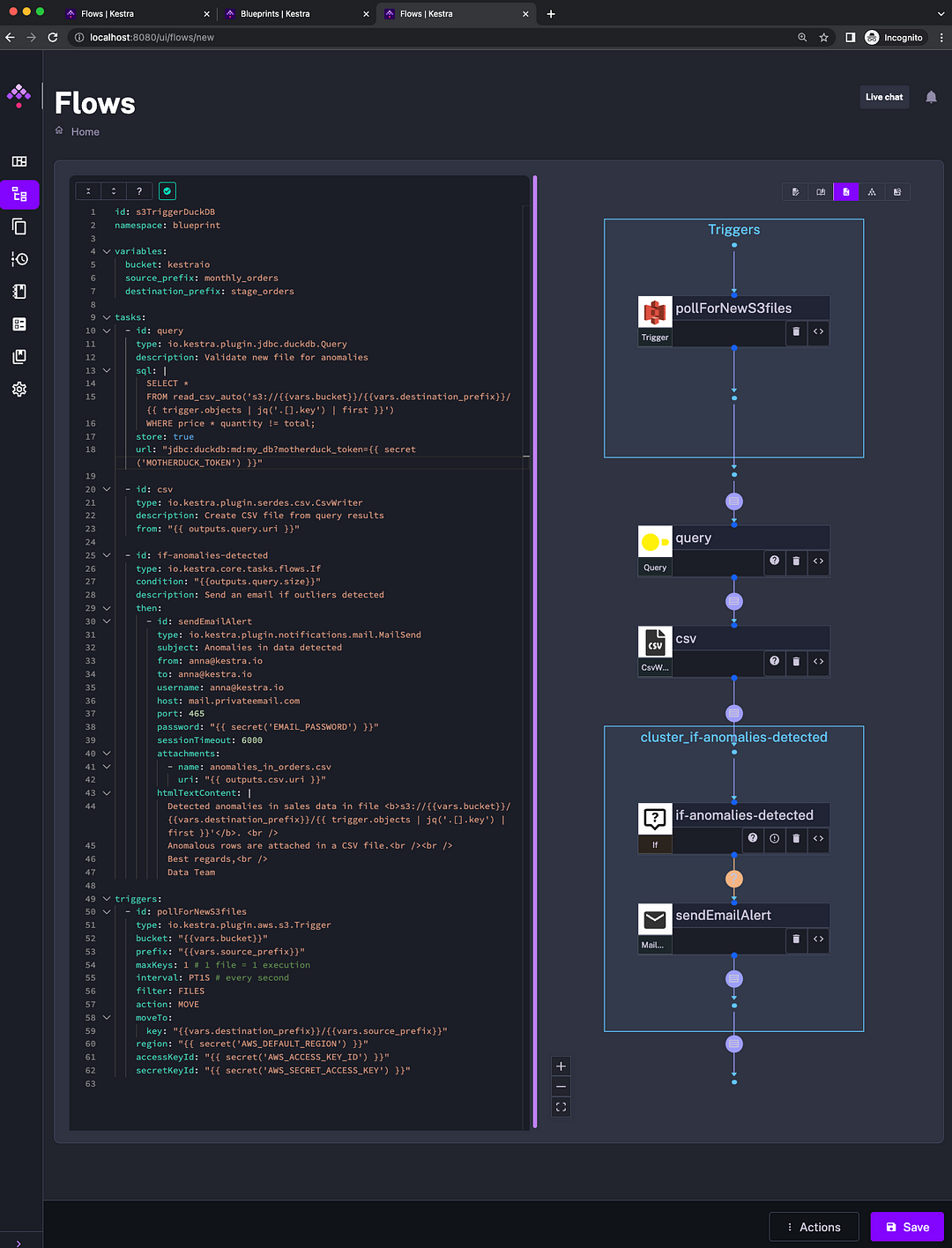
To test that workflow locally, add your credentials to S3, MotherDuck, and email, for example, using Secrets. Then, upload one of these files from GitHub to S3 (or upload all files). You can change the numbers, e.g., in the 2023_01.csv file, to create a fake anomaly. Then, upload the file to S3:
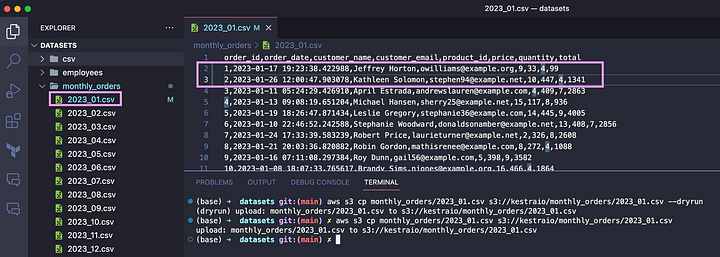
As soon as the file is uploaded, the flow will check it for anomalies using a DuckDB query. The anomaly will be identified as shown in the image:
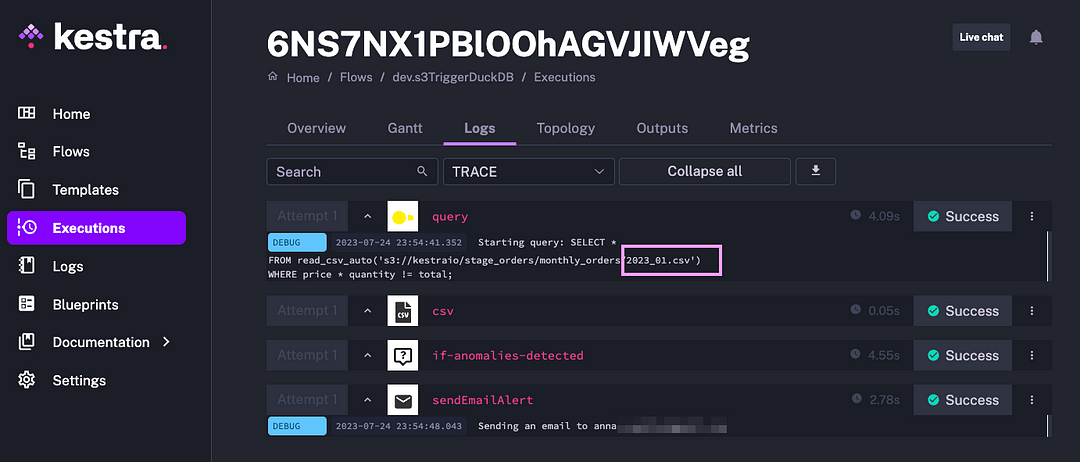
The result of this flow execution is an email with anomalous rows attached, and a message pointing to the S3 file with these outliers, making it easier to audit and address data quality issues:
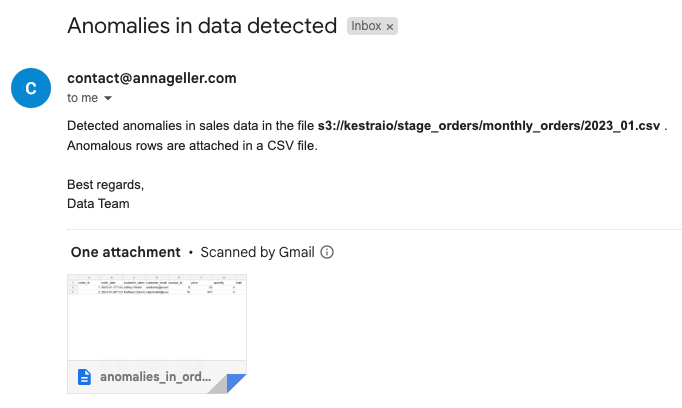
This post covered various ways to use DuckDB and MotherDuck in your data pipelines. If you have questions or feedback about any of these use cases, feel free to reach out using one of these Slack communities: MotherDuck and Kestra.
2023/07/17 - Marcos Ortiz
DuckDB news: MotherDuck launches managed cloud service with hybrid execution. Apache Iceberg extension arrives. Vectorized Python UDFs added. DuckCon SF talks published.

2023/08/09 - Michael Hunger
Exploring StackOverflow with DuckDB on MotherDuck (Part 1)