
2024/01/10 - David Neal
Analyze JSON Data Using SQL and DuckDB
Learn to read, parse, and query JSON data from files and APIs using SQL and DuckDB!
It takes about 4.5 hours for me to go door to door from my house in Seattle to our office in San Francisco. Let’s say you built a hypersonic plane with a top speed that was 10 times faster than the usual Boeing 737-MAX (with or without the extra windy window seat). After you factor in an Uber to the airport, waiting in security lines, boarding, taxiing on the tarmac, takeoff and landing, waiting for a gate, waiting for baggage, and my Uber to the office, you’d have accomplished some amazing feats of engineering but probably only shaved off 20% of the overall travel time. That’s good, but I’m still not going to make a 10 am meeting.
The database industry has been focused on the equivalent of making faster planes. Meanwhile, security lines get longer and luggage gets lost. An ideal query optimizer won’t help you if your data is in a slightly wonky CSV file or if the question you want to ask is difficult to formulate in SQL.
Performance is the most common metric that database nerds like me use to measure our importance, and like sports fans, we tend to pick teams that we root for against everyone else. If your favorite database wins the benchmark wars, you have bragging rights at the watercooler. You can brandish your stats, backed up by blog posts, to prove to anyone who will listen that your favorite DB is the champ.
Performance in general, and general-purpose benchmarking in particular, is a poor way to choose a database. You’re better off making decisions based on ease of use, ecosystem, velocity of updates, or how well it integrates with your workflow. At best, performance is a point-in-time view of the time it will take to complete certain tasks; at worst, however, it leads you to optimize for the wrong things.
In 2019 GigaOm released a benchmark comparing cloud data warehouses. They ran both TPC-H and TPC-DS across the three major cloud vendors plus Snowflake. The results? Azure Data Warehouse was the fastest by far, followed by Redshift. Snowflake and BigQuery were far behind.
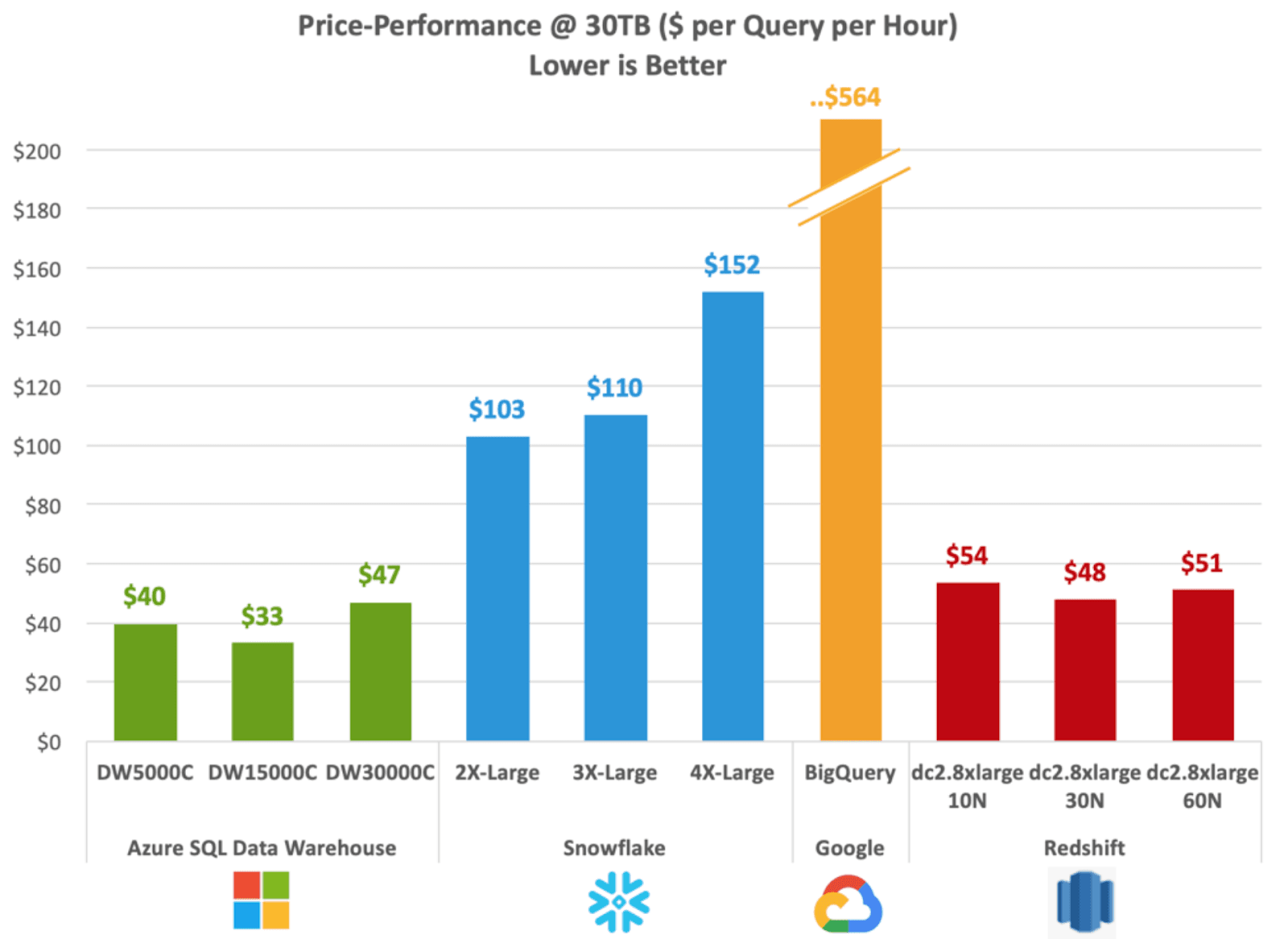
At the time, I was working on BigQuery, and a lot of folks freaked out …. How could we be that much slower than Azure? However, the results didn’t match the impression we had from users. Every time a customer did a head-to-head evaluation of us vs Azure, they ended up choosing BigQuery. The market outcomes at that time were almost the reverse of the benchmarks: Snowflake and BigQuery ended up selling a lot better than Redshift, which sold much better than Azure.
If the benchmark didn’t match the customer experience, then either the benchmark was done wrong, the benchmark was testing the wrong thing, or performance turned out to not be that important after all. We did a lot of poking around, and it wasn’t the first one; the GigaOm folks are pretty good at running benchmarks and the methodology was sound. The benchmarks they ran, TPC-H and TPC-DS, are the industry standards and had a broad range of queries. They were the benchmarks we ourselves ran internally in order to judge performance, and while one can quibble with the data size or their relevance to real-world workloads, they were the best available.
So if the benchmark was a good representation of performance, and customers, by a large margin, ended up buying the systems that did poorly on the benchmark, then it leads you to believe that perhaps there are more important things than performance.
In the 15 years that I’ve spent working on cloud databases, I’ve noticed an anti-pattern across the industry: People who build databases tend to be laser focused on the time between when someone clicks the “run” button and the time that results are ready. It is easy to see why database people would focus on just the database server time; after all that is the thing that they have the most control over. But what is actually impactful to users is the time it takes to complete a task, which is not the same thing.
In BigQuery, we outsourced building the JDBC drivers to a company that specializes in building database connectors. If you’re not familiar with JDBC, these provide a universal interface that programmers and Business Intelligence tools use to connect to a database. It made sense at the time to have a well-known expert build the interfaces.
A few years later, after numerous customer complaints, we realized that bugs in our JDBC driver were killing performance. From our perspective, the queries ran quickly, in just one or two seconds. But the way the driver was polling for query completion and pulling down the results made the queries seem like they were taking seconds or even minutes longer. This impact was exacerbated when there were a lot of query results, since the driver would often pull down all of the results one page at a time even if the user didn’t need to see all of the results. Sometimes they’d even crash because they ran out of memory.
We had been spending many engineer years making the queries fast, shaving off fractions of a second here and there from query times. But the connectors that most of our users were using added far more latency than we had saved. What’s more, we were completely blind to that fact. No one at Google actually used the JDBC drivers, and while we ran full suites of benchmarks every night, those benchmarks didn’t actually reflect the end-to-end performance our users were seeing.
Like the drunk looking for his keys under a streetlight, we looked only at the performance we could measure on our servers. The query time that users were seeing was invisible to us, and we considered it someone else’s problem. To actually fix the problem, and not just put band-aids on it, required us to reframe how we thought about performance.
Performance must be measured from the user’s perspective, not the database’s. It is a UX problem and, like any UX problem, can’t really be described in a single number. This is surprising to many people, since they think performance, like car racing, is an objective thing. Just because you can say that a Lamborghini is faster than a Prius, they believe you should also be able to say that My database is faster than Your database. But just like a Lamborghini might not get me to work any faster than a Prius (or a bicycle, if there is traffic), the actual workload for a database is going to determine which one is faster.
Subjectivity gets a bad rap; people associate it with saying, “Well, there is no way of telling which one is better, so it doesn’t matter which one we choose.” But just because the difference between a Ford F150 pickup truck and a Tesla Roadster is subjective, it doesn’t mean that my experience with both would be equivalent. Databases are the same way; if we say the performance differences between Clickhouse and Redshift are subjective, it doesn’t mean they are equivalent. It just means that which one is faster depends on how they are being used, which is exactly why teams evaluating ClickHouse alternatives often prioritize operational simplicity and standard SQL over raw query speed alone.
A couple of years ago, Clickhouse released Clickbench, a benchmark that showed that Clickhouse was faster than a couple dozen databases they tested against. This was surprising to me, since at the time I was working at SingleStore, and we believed that we were broadly faster than Clickhouse. After digging into the benchmark, we saw that the benchmark didn’t do any JOINs, so operated out of a single table, and also relied heavily on counting distinct items.
While you might think that it is cheesy to publish a benchmark that just does single-table scans, Clickbench actually does a pretty good job of representing a number of real workloads. If you do a lot of log analysis and need to compute distinct users to your website, this could be a good proxy for performance. That said, if you’re running a more traditional data warehousing workload using a star schema, Clickbench is going to be misleading.
Vendor benchmarks tend to focus on things that the vendor does well. The below is a diagram from “Fair Benchmarking Considered Difficult” describing the typical vendor benchmark result.
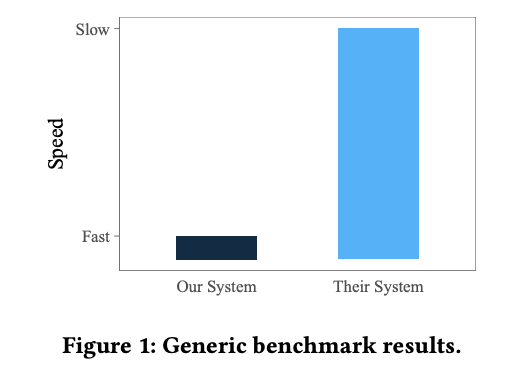
There are tons of pitfalls in database benchmarking, and experience has shown that benchmarks typically do a poor job of capturing broad user-perceived performance. For example, BigQuery shows up very poorly in benchmarks, but the actual experience of many people is that the performance is magical. BigQuery shows up well in person because it doesn’t have any knobs and is largely self-tuning. A highly-tuned SingleStore instance will crush BigQuery at most tasks, but do you have time to spend tuning your schemas? And what happens when you add a new workload?
The DuckDB website used to have a disclaimer that said, “Please don’t complain about performance, we’re trying to focus on correctness before we try to make it fast.” Not all databases apply the same approach. You can make a car faster by removing safety gear like airbags, traction control, crumple zones, emissions controls, etc. But most people don’t want to drive a car like that. Databases are no different; you can make them faster if you remove overflow checks, don’t flush writes, give approximate results to certain operations, or don’t provide ACID guarantees. Some of the systems that do well on these benchmarks apply these kinds of short-cuts, but I wouldn’t want to use them except in controlled circumstances.
Last year when I set out to create a company on top of DuckDB, a number of people pointed out to me that if you Googled DuckDB performance, a benchmark would come up where DuckDB got pretty badly beaten. Wasn’t I worried? Why not choose a “faster” one?
I wasn't concerned for two reasons. First, I think performance is of secondary importance. But second, DuckDB had demonstrated something that made current benchmarks moot; they improve incredibly quickly. Partly because of some architectural decisions, partly because the code base is relatively new and clean, and partly because the engineers involved are super talented, DuckDB gets better at an extraordinary rate.
And it turned out I was right to not be concerned. The most recent published results of that same benchmark against the latest DuckDB release show they went from the middle of the pack to leading by a healthy margin.
The broader point is that when you choose a database, the database is not frozen at that point in time. You’ll likely end up sticking with your decision for several years. The performance and features of your database are going to change a lot between now and next year, and even more so between now and five years from now.
A very important variable, then, is not just what the database can do now, but what it will be able to do a year in the future. If a bug in a database causes you to choose a competitor, that’s going to seem like a silly reason in just a few weeks if that bug has been fixed. This holds true with performance; if two different databases are improving at different rates, you’re most likely better off choosing the faster moving one. Your future self will thank you.
If you take a bunch of databases, all actively maintained, and iterate them out a few years, performance is going to converge. If Clickhouse is applying a technique that gives it an advantage for scan speed today, Snowflake will likely have that within a year or two. If Snowflake adds incrementally materialized views, BigQuery will soon follow. It is unlikely that important performance differences will persist over time.
As clever as the engineers working for any of these companies are, none of them possess any magic incantations or things that cannot be replicated elsewhere. Each database uses a different bag of tricks in order to get good performance. One might compile queries to machine code, another might cache data on local SSDs, and a third might use specialized network hardware to do shuffles. Given time, all of these techniques can be implemented by anyone. If they work well, they likely will show up everywhere.
George Fraser, the CEO of Fivetran did an interesting post comparing performance of the main data warehouse vendors over time; while there was a pretty big dispersion in 2020, by 2022 they are much more closely clustered together. In 2020, the fastest time was 8 seconds and the slowest was 18, in 2022 three of the vendors were around 7 seconds and the slowest was 9.
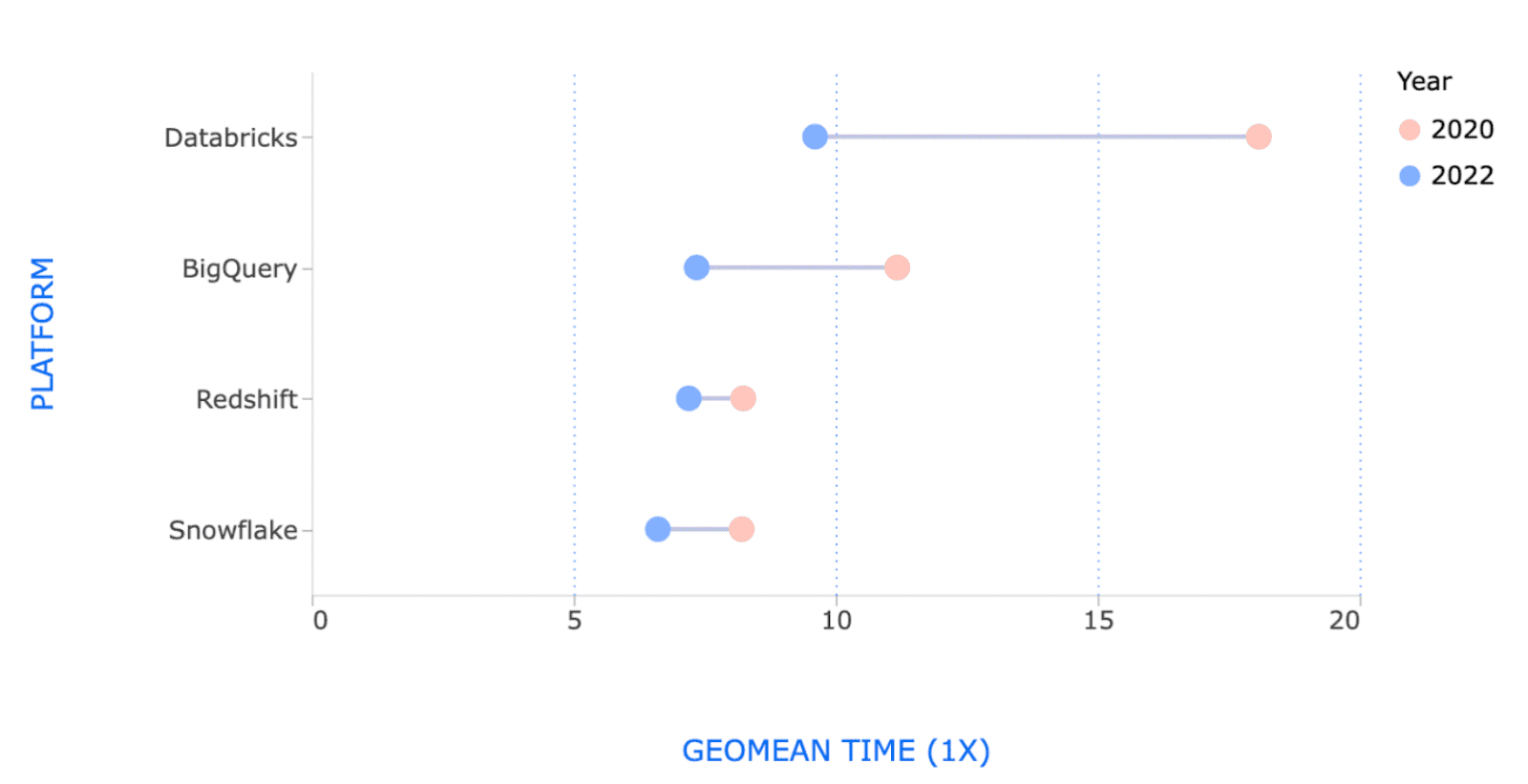
The caveat to this rule, of course, is that architectural differences are hard to overcome. Shared nothing databases are at a disadvantage vs shared disk, and it took Redshift many years to switch to a primarily shared disk architecture. Lakehouses that rely on persisting metadata to an object store will have a hard time with rapid updates; this is built into the model. But these types of differences tend to show up in margins; there is, for example, no fundamental reason why Redshift would be faster or slower than Snowflake in the long run.
To a user, the important measure of performance is the time between when they have a question and when they have an answer; that can be very different from the time it takes the database to run a query.
If you step back and think about it from their point of view, there are a lot more levers you can use to achieve the goal of minimizing the time between question formulation and answer. You can make it easier to pose the question. You can make it easier to turn query results into something they can understand. You can help them get feedback when they’re not asking the right question. You can help them understand when the data has problems. You can help them get the data they need in the right place and the right shape to be able to ask the question in the first place. While these aren’t typically thought of as performance issues, improvements can speed up the workflows of analysts and data engineers to a larger degree than a better query plan.
Snowflake did a great job of making it easier to write queries. Whereas many SQL dialects are opinionated about being consistent about syntax and that there should be “one way” to do everything, Snowflake designers had the goal of making SQL that users type “just work.” For example, in Snowflake SQL, if you want to compute the difference between two dates, you can use either DATEDIFF or TIMEDIFF; both work with any reasonable type. You can specify a granularity, or not. You can use quotes around the granularity, or not. So if you just type a query, as long as the intention can be gleaned, it should “just work.” This is one of the reasons that analysts like Snowflake, since they don’t have to spend their time looking things up in the documentation.
DuckDB has innovated along these lines, as well, with their “Friendlier SQL” effort, which adds a number of innovations to the SQL language to make it easier to write your queries. One example is “GROUP BY ALL.” When you write an aggregation query, it is easy to forget to list one of the fields in the GROUP BY clause. This is especially the case when you evolve queries, because you have to make changes in multiple different places. The GROUP BY ALL syntax makes it easier to both write and maintain your queries because you only need to change the query in one place (i.e. SELECT list) rather than the aggregation. This was so useful that soon after they released the feature, several other database vendors raced to add similar functionality.
Data isn’t always in a convenient format for querying. A huge amount of the world’s data is in CSV files, many of which are poorly constructed. Despite this, most Database vendors don’t take them seriously. In BigQuery, I wrote our first CSV splitter, and when it turned out to be a trickier problem than expected, we put a new grad engineer on the problem. It was never great, couldn’t do inference, and got confused if different files had slightly different schemas. It turns out the CSV parsing is actually hard.
If two engineers using two different databases need to read CSV data and compute a result, the one who is able to ingest their CSV file correctly the most easily is likely going to get the answer first, regardless of how fast their database is at executing queries. CSV file inference can therefore be thought of as a performance feature.
The way databases handle results has massive impacts on user experience. For example, a lot of times people run a “SELECT *” query to try to understand what’s in the table. Depending on how the database system is architected, this query can be instantaneous (returning a first page and a cursor, like MySQL), can take hours for large tables (if it has to make a copy of the table server-side, like BigQuery), or can run out of memory (if it tries to pull down all of the data into the client). Do clients have a long-running connection to the server, which can have trouble with network hiccups? Or do they poll, which can mean the query can complete in between polling cycles and make the query appear slower?
I’m a co-founder of a company building on DuckDB. This post might sound like something someone would write if they were working on a database that wasn’t fast, didn’t do well in benchmarks, or wasn’t focusing on performance. So I should mention that DuckDB is fast. I won’t spend a lot of time defending DuckDB performance, but DuckDB is currently top of ClickBench in a handful of machine sizes (e.g. c6a.4xlarge) and most of the h20.ai benchmarks. And they’re not too shabby on TPC-H and TPC-DS either.
As has been mentioned before, your experience may differ! So before you go assuming any database is fast, try it out on your workload. But the point is, don’t count out the ducks!
None of the most successful database companies got that way by being faster than their competitors. Redshift was king for a while, and the thing that let Snowflake in the door was maintainability, not performance on benchmarks. Databases whose primary selling point was performance did not perform well in the market. Databases who made it easy to get jobs done fared a lot better.
To summarize:
Faster queries are obviously preferable to slower ones. But if you’re choosing a database, you’re better off making sure you’re making your decision based on factors other than raw speed.
Happy Querying!
2024/01/10 - David Neal
Learn to read, parse, and query JSON data from files and APIs using SQL and DuckDB!

2024/01/16 - Peter Boncz
MotherDuck released its paper on Hybrid Query Processing at the Conference on Innovative Data (systems) Research [CIDR].