Why Python Developers Need DuckDB (And Not Just Another DataFrame Library)
2025/10/08 - 6 min read
BYIf you're working with Python and building data pipelines, you've probably used pandas or Polars. They're great, right? But here's the thing - DuckDB is different, and not just because it's faster.
It's an in-process database that you can literally pip install duckdb and start using immediately. So what does a database bring to the table that your DataFrame library doesn't?
Let's talk about 6 pragmatic reasons why DuckDB might become your new best friend or pet.
But first, a quick history lesson on why dataframe became so popular and what they are missing today.
THE DATAFRAME ERA
Back in the 2000s, if you wanted to do analytics, you'd install Oracle or SQL Server. Expensive licenses, complex setup, DBAs to manage connections... it was a nightmare for quick analysis.
Then Python exploded in popularity. Pandas came along and changed everything. Suddenly you could:
pip install pandas- Write a few lines of code
- Get immediate results
No DBA, no licenses, no infrastructure headaches. Just pure analysis in a Python process. Beautiful, right?
THE PROBLEM
Here's where things get messy. We've pushed DataFrames way beyond their original design. They were built for:
- Quick experimentation
- In-memory computation
- One-off analysis
And they are still great for this use case.
But DataFrame libraries give you one slice of what a database does, and then you end up stiching together a bunch of other Python libraries to fill the gaps. It works... but it's fragile.
So what if you could get the simplicity of DataFrames with the power of a real database? That's DuckDB.
REASON 1: ACID TRANSACTIONS
Let's start with the obvious - it's an actual database. That means ACID transactions.
Copy code
BEGIN TRANSACTION;
CREATE TABLE staging AS SELECT * FROM source;
INSERT INTO prod SELECT * FROM staging WHERE valid = true;
COMMIT;
If anything fails into this pipeline? Automatic rollback. Your data stays intact. No more corrupted parquet files because your pipeline crashed halfway through a write.
We've all been there - you're writing to a CSV or parquet file, something breaks, and now you've got half-written garbage data. With DuckDB, that's not a problem because, there's an actual file format from DuckDB aside from the supports to read/write to classic json,csv,parquet.
INFO: ACID transactions ? Quick recap ACID transactions are database guarantees that keep data reliable. They make sure updates happen all or nothing (Atomicity), follow the rules (Consistency), don’t interfere with each other (Isolation), and stay permanent once confirmed (Durability). Unlike Pandas or Polars, which don’t provide full ACID guarantees, databases ensure every change is complete, consistent, and durable. This matters because it keeps your analysis safe from half-finished updates or conflicting edits, so the numbers you see truly reflect reality.REASON 2: ACTUAL DATA PERSISTENCE
Second point - DuckDB has its own database file format.
Copy code
import duckdb
conn = duckdb.connect('my_analytics.db')
When you create a DuckDB connection - you just provide a path to a file and that's it. Everything you create is persisted in that file. It's a one single database file that contains Real schemas, metadata, ACID guarantees - all in one portable file.
You know that mess where you've got CSV files scattered everywhere, some parquet files over there, JSON from an API somewhere else? Yeah, that. With DuckDB, you can consolidate everything into a single database file with proper schemas and relationships.
 Every analytics project - source
Every analytics project - source
REASON 3: BATTERIES INCLUDED
Third - DuckDB has a built-in ecosystem of features.
With DataFrames, you need different Python packages for everything:
- S3 access? Install
boto3 - Parquet files? Install
pyarrow - PostgreSQL? Install
psycopg2
Welcome to dependency hell! Good luck when one of those updates breaks everything.
DuckDB's extensions are built in C++ (so lightweight footprint!), maintained by the core team, and just work. Watch this:
Copy code
import duckdb
conn = duckdb.connect()
# Read from public AWS S3 - one line, no setup
conn.sql("SELECT * FROM 's3://bucket/data.parquet'")
# Connect to Postgres
conn.sql("ATTACH 'postgresql://user:pass@host/db' AS pg")
conn.sql("SELECT * FROM pg.my_pg_table")
Behind the scenes, DuckDB loads the core extensions automatically. No configuration, no dependency management. It just works.
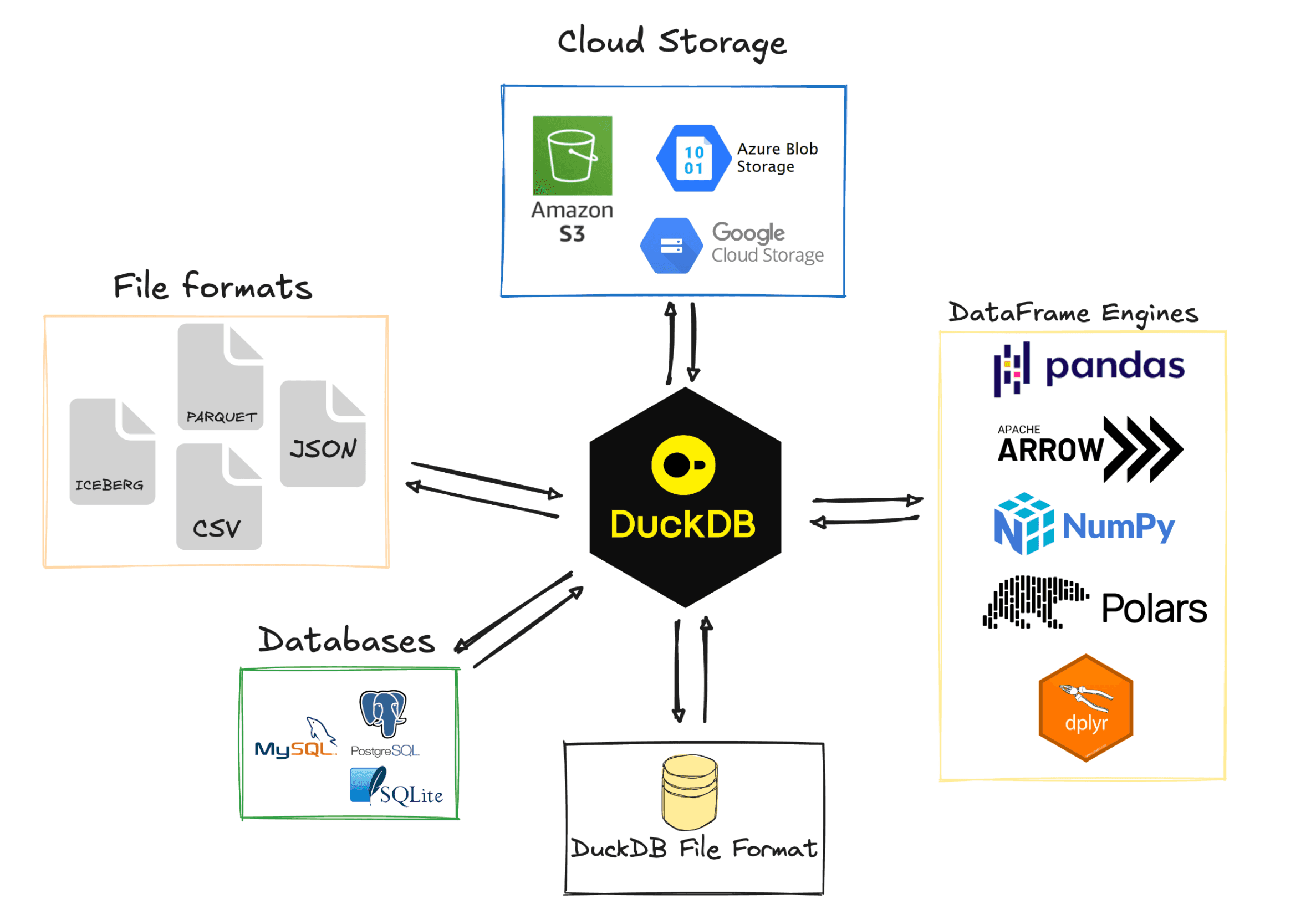 DuckDB ecosystem
DuckDB ecosystem
REASON 4: NOT JUST FOR PYTHON
Here's something important for Python users - DuckDB isn't locked into Python.
Yes, you can hang out with your Javascript friends. Or whatever your friends use.
You process data in Python, sure. But eventually you need to serve it somewhere - maybe a web app, a dashboard, whatever.
Because DuckDB is in-process, it can run anywhere:
- JavaScript in the browser (via WebAssembly)
- Java backend services
- Rust applications
- Even the command line
And here's the cool part - they can all read the same DuckDB file format. Everyone speaks SQL, and you can even offload compute to the client side if needed.
Your Python pipeline creates the database, and your JavaScript frontend queries it directly.
Easy peasy
REASON 5: SQL AS A FEATURE
I know some of you are thinking "but DataFrames look cleaner!"
Look, this is partly syntax preference and debate.
But SQL is universal. Your data analyst knows it. Your backend engineer knows it. Your future self will thank you when you come back to this code in six months.
Plus, DuckDB has "friendly SQL" that makes common tasks ridiculously easy:
Copy code
-- Exclude specific columns
SELECT * EXCLUDE (password, ssn) FROM users;
-- Select columns by pattern
SELECT COLUMNS('sales_*') FROM revenue;
-- Built-in functions for everything
SELECT * FROM read_json_auto('api_response.json');
Check the DuckDB docs for the full list of friendly SQL features
REASON 6: SCALE TO THE CLOUD
Because DuckDB can run anywhere, scaling to the cloud is trivial.
With MotherDuck (DuckDB in the cloud), moving your workflow requires literally one line:
Copy code
import duckdb
# Local
conn = duckdb.connect('local.db')
# Cloud - same code, one extra line
conn = duckdb.connect('md:my_database?motherduck_token=...')
# That's it. Same queries, now running in the cloud.
conn.sql("SELECT * FROM 's3://bucket/data.parquet'")
Your code doesn't change. Your SQL doesn't change. You just get cloud scale when you need it.
GETTING STARTED
Here's the best part - you can start today without rewriting everything.
Thanks to Apache Arrow, DuckDB has zero-copy integration with pandas and Polars:
Copy code
import pandas as pd
import duckdb
df = pd.read_csv('data.csv')
# Query your DataFrame directly with SQL and export back as a dataframe
result = duckdb.sql("""
SELECT category, AVG(price)
FROM df
GROUP BY category
""").df()
No conversion overhead. Start small, refactor what makes sense, and gradually adopt more DuckDB features!
So yeah, DuckDB is way more than just another DataFrame library. It's a full database that's as easy to use as pandas, but with actual database features when you need them.
Start using MotherDuck now!

