Today we’re launching a preview of Read Scaling, which allows highly concurrent read-heavy workloads to automatically scale out to multiple DuckDB instances, so you can run at peak performance no matter how many users you have. This allows you to use the MotherDuck data warehouse to serve that popular dashboard, build that data application that serves your large corporate customers, and helps you show visualizations at video-game style refresh rates. With Read Scaling, you don’t have to worry about whether MotherDuck can handle the number of users you throw at it.
Using read scaling to speed up BI tools
Read Scaling replicas are great for configuring your Business Intelligence tool. Here at MotherDuck, we use Omni for a lot of our dashboards, and after changing the Omni connection to use a Read Scaling Token, dashboards got much faster to load, and our metrics meeting where we have a bunch of people all digging into the data at once got dramatically more interactive. Configuring BI to use Read Scaling is an easy improvement.

Using read scaling to improve data app performance
The other big use case for Read Scaling is for data apps; that is, if you’re building an application that sends MotherDuck queries. Maybe you’re a marketing analytics company and you want your users to be able to see interactive graphs about the campaigns they’re running. So you’d have one MotherDuck user per customer, but that customer might actually have a lot of end users; let’s say they had a big marketing department. Without a read replica, if the whole marketing team was trying to use the product at once, they might see performance issues. However, if you just switch to use a Read Scaling Token, MotherDuck will transparently scale to be able to handle all of those end users.
There is a further case where read-only tokens are useful, which in building what we call at MotherDuck “1.5 tier apps.” Whereas in a typical 3-tier application you have a client that talks to a server which talks to a database, 1.5 tier means that you can have the client talk directly to the database (2 tier) or even have the analytics run locally within the client (1 tier). So we put those two together and call it 1.5 tier.
MotherDuck has a Web Assembly (Wasm) client which enables 1.5 tier applications by running DuckDB in the browser as well as on the server. There is a tricky technical challenge however; if the client can talk directly to MotherDuck, how do you make sure that client doesn’t do destructive or expensive things? Read Scaling Tokens are a key solution to that; because they only have read access to the data, they can’t attach databases or write data.
How do you enable Read Scaling?
Since Read Scaling replicas are read-only, in order to use this feature, you need to be connecting to MotherDuck using a read-only mode. To do this, you need to create a Read Scaling Token; these are just like the tokens you’d create to talk to any application, but are specifically scoped down so you can only use them to read data, not to write data back to MotherDuck
If you click on the top left corner of the MotherDuck UI you’ll get the Settings dropdown that looks like this:
Click on “Settings,” and find where it says “Access tokens” on the “General” settings page. If you click on the “Create token” button you should see a popup like the following:

Select “Read Scaling Token” as the token type and click the “Create token” button. It will then give you the token and prompt you to put it somewhere safe.
Once you have that Read Scaling Token, you can use it anywhere you’d use your MotherDuck authentication token. Connections created with the Read Scaling Token will now be able to scale out to multiple DuckDB instances. If you are fanning out to multiple users and aren’t using one DuckDB Instance per user, you can add an extra parameter when you connect to MotherDuck; if you set session_hint=<some user id>, then we’ll make sure all requests with that same user ID end up getting sent to the same DuckDB instance. But this isn’t required to use the feature.
Are there any drawbacks?
There should be minimal impact on cost to you. MotherDuck queries are billed by the amount of CPU they consume, and if a query is run in a replica it shouldn’t take any more CPU cycles than if it gets run in the primary DuckDB instance.
Because Read Scaling replicas run in separate DuckDB instances, the data they see can lag a bit behind the main copy. It should be a consistent snapshot (i.e you won’t see any uncommitted data or data appearing out of order), but it might take a few moments after the initial write is done for it to be safe for the replica to pick it up. The mechanism is identical to an auto-update share; in essence, all of your attached databases are treated like shares.
Why do you need to scale reads?
Very early in the MotherDuck journey, I gave a talk to a roomful of database luminaries in Amsterdam, and pitched our idea for a single-node scale up data warehouse for the 99%. One of them was a co-founder of a multi-billion dollar database company, and I sought out his feedback after the talk.
To paraphrase his response, he said, “You’re right that the vast majority of data analytics use cases don’t have scale that requires a distributed system, so scaling up like you’ve proposed will work. However… there are a lot of read-heavy workloads that could overload a single node. As soon as you have a dashboard that is being hit by dozens or hundreds of people at the same time, you’re going to fall over.”
On one hand, it was great positive feedback that he validated our scaling hypothesis. On the other hand, he pointed out a valid problem with the single node model. If you get lots of concurrent queries at once, it can be pushed to its limits, no matter how large the node is.
We had a solution to this problem already for the multi-user case, which is that in MotherDuck each user gets their own DuckDB instance. We call this per-user tenancy and it allows MotherDuck to scale to hundreds or thousands of concurrent instances so we don’t overload any individual instance. That is in contrast to other data warehouses that tend to run a small number of instances that scale up to larger sizes in response to heavy load. With our ability to run each user in a separate instance, as long as a single user doesn’t run dozens or hundreds of queries at once, it should be fine.
However, there is a common workload where MotherDuck could get overloaded: Business Intelligence tools often use a single account shared by a large team and look like a single user to the database. That would mean we’d send all of those requests to the same DuckDB instance, and large teams could overload that single instance. Superset, for example, configures a single database connection and then manages users itself. From the point of view of the database, it looks like all of the queries from the whole organization are coming from the same user. This means that MotherDuck users who use a BI tool and share a connection across their company could experience poor performance if lots of users were using it at the same time. Read scaling solves this problem by allowing those workloads to be distributed dynamically across many instances.
MotherDuck Internals: How does read scaling work?
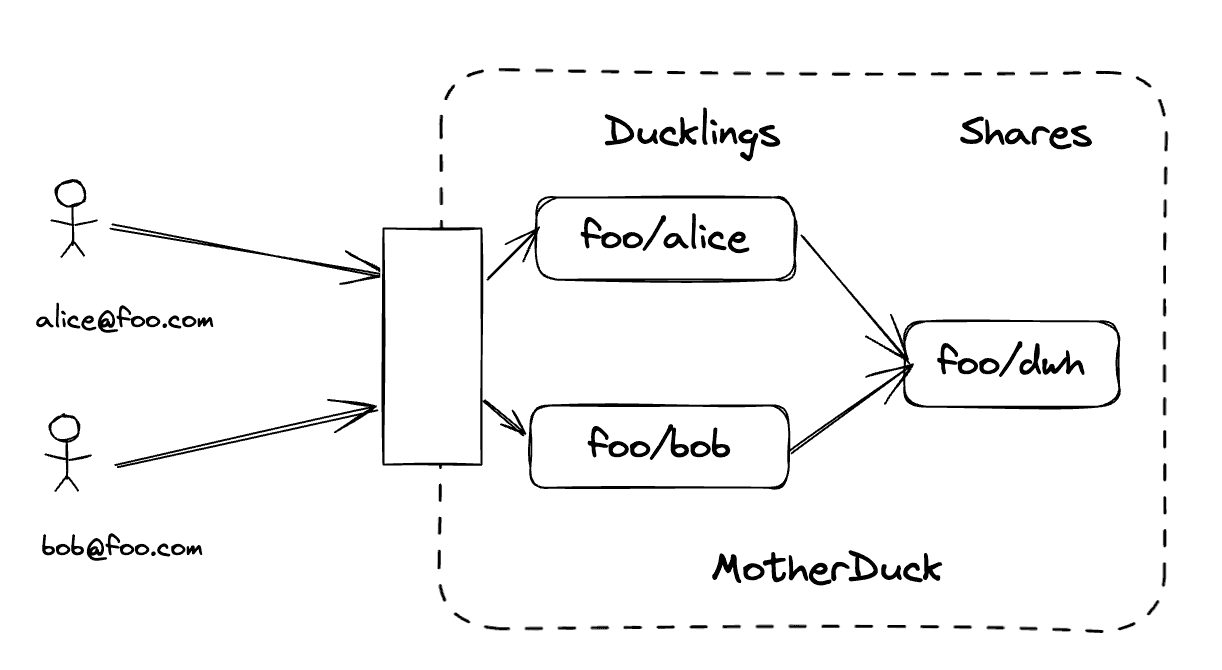
In MotherDuck, every user gets their own DuckDB instance in the cloud, we call it a Duckling. The Duckling starts almost instantly (generally less than 200 ms), can auto-scale, and shuts down when it isn’t being used. What’s more, you only pay when it is running queries. If you have hundreds of users in your organization, each one has a Duckling. The diagram below shows how Alice and Bob, both from the Foo.com organization, both connect to MotherDuck. Each one gets routed to their own Duckling, and they can both access Foo.com’s data warehouse independently, using independent compute.
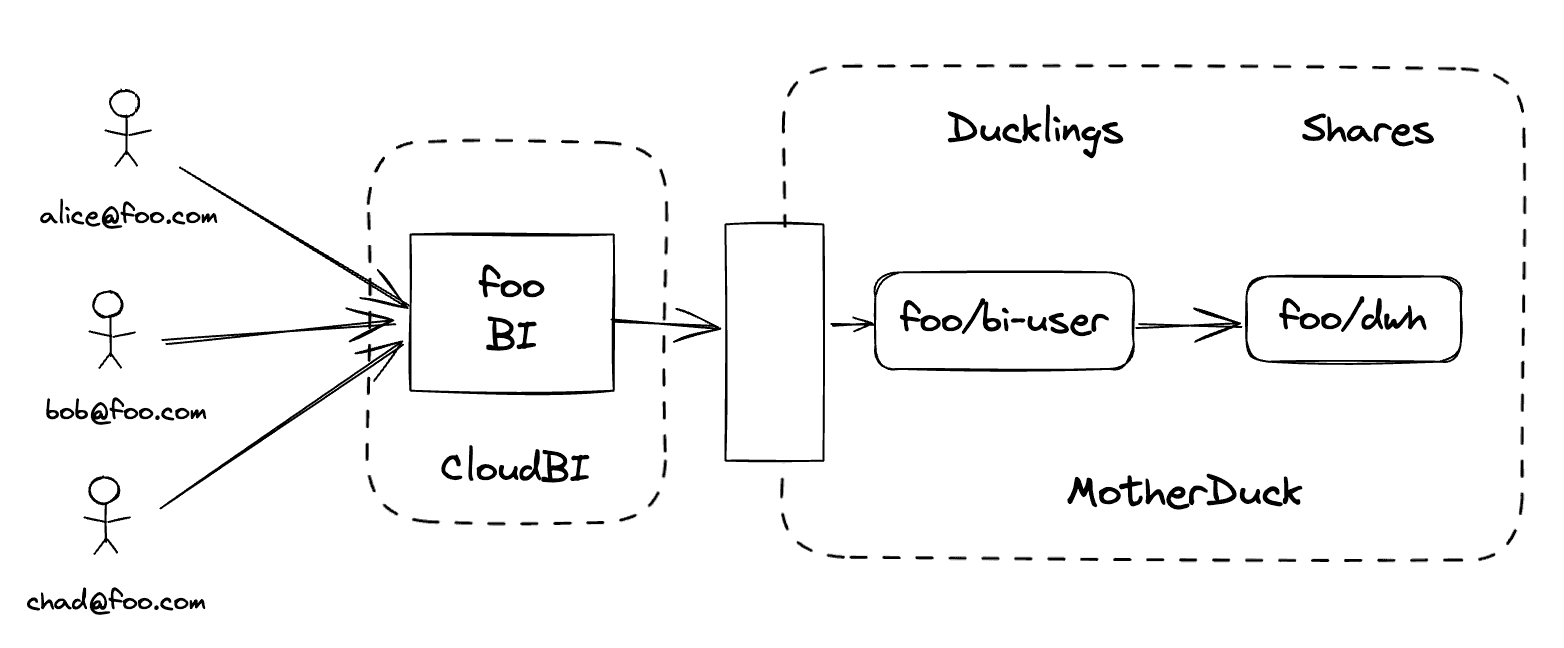
The tricky part comes when Alice and Bob use a BI tool that funnels all of their requests to the data warehouse looking like a single user (bi-user@foo.com in this case). All of the users in that organization look like they are coming from that single user, so they get routed to the same duckling.
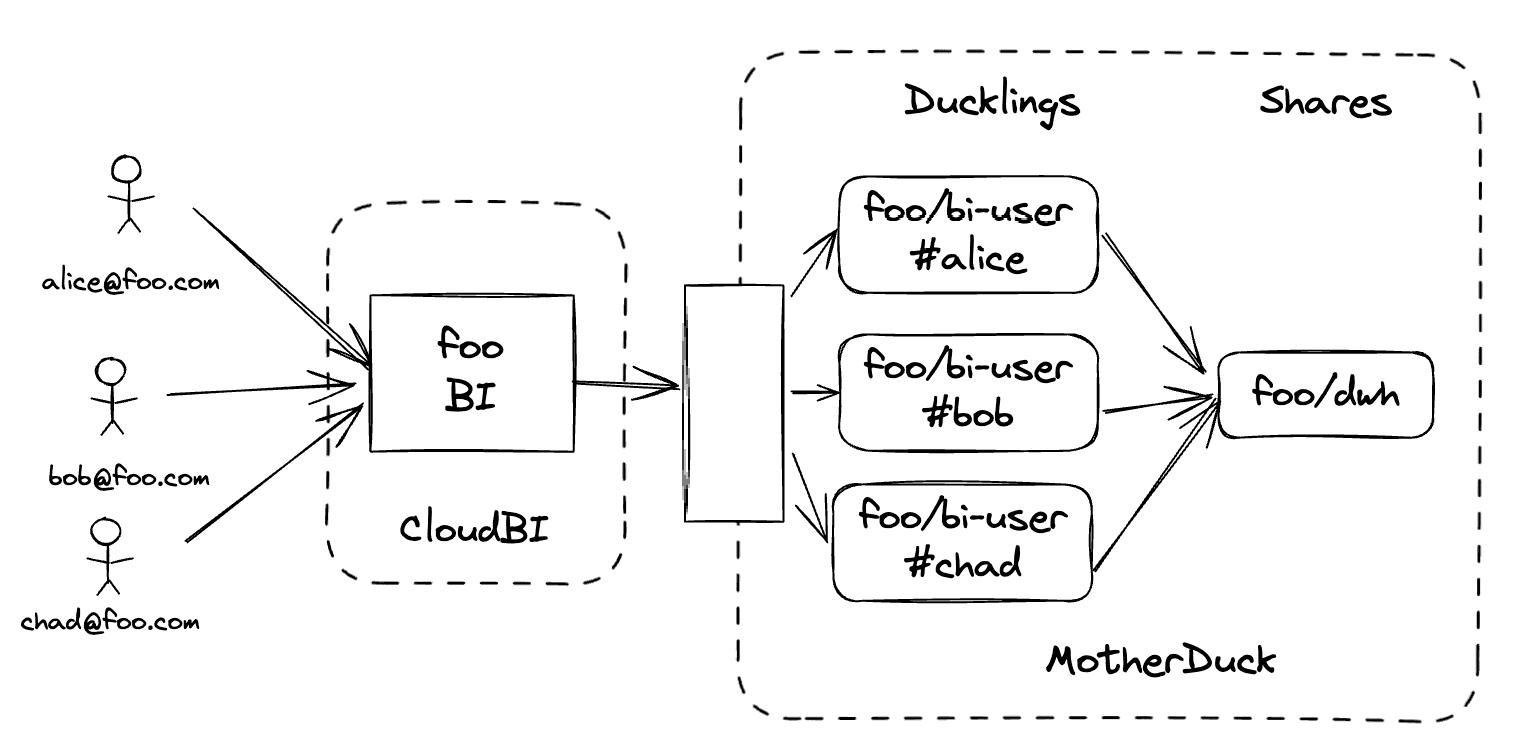
With Read Scaling, we will automatically spin up additional Ducklings as needed to handle read-only workloads. Those Ducklings are a clone of the original Duckling, and have access to the same data. Subsequent queries are load distributed between the DuckDB instances. In order to get more consistent performance, we will attempt to route an end user to the same duckling for all of their queries. You can see how this works in the diagram below.
Even though MotherDuck can start new instances very quickly, there is benefit to having a Duckling already up and running with data pre-cached. If queries get sent to random replicas, performance might not be great if you do back-to-back queries against the same data. To solve this problem, MotherDuck routes queries based on your client-side identity. If you create a database connection and reuse that connection, you will continue to talk to the same Duckling. This lets you take advantage of cache locality since the DuckDB buffer pool will have relevant parts of your data already in memory.
There is a further optimization that can be used by applications that fan out to multiple end users and manage connection pools. If multiple connections map to the same user, or connections get recycled frequently, applications can provide a session_hint parameter when connecting to MotherDuck. The session_hint can be a hash of the user id or session id, and it allows a stable mapping between end users and Ducklings. This can ensure that a user’s workload will get consistent performance.
Other data warehouse vendors have something similar; you can configure Snowflake to spin up additional warehouses when you have high concurrency. However, this is a pretty heavyweight solution; MotherDuck instances are much lighter weight, since they can be started and stopped in milliseconds with minimal performance overhead.
Share your Feedback
Read Scaling unlocks a big piece of the MotherDuck vision; it allows workloads using reasonable-sized datasets to scale to lots of concurrent users. We’re happy to hear feedback, so please join our community slack channel to let us know what you think. Happy MotherDucking!

