
2024/06/11 - MotherDuck team
Announcing MotherDuck General Availability: Data Warehousing with DuckDB at Scale
Turbocharge DuckDB's efficiency with multiplayer cloud analytics
- 14 min read
BY- 14 min read
BYThis is the third of the current blog series exploring search in DuckDB. So far in this series we’ve covered quite some ground on vector embeddings based text search and building a knowledge base that you could search and query using vector embeddings. In embedding-based search, semantic understanding and similarities is key to ranking the documents; however there are situations where exact keyword matching is essential. This is especially true in areas like law, compliance, and medical document retrieval, where it is crucial to link specific legal codes or medical terms to the documents being searched. Lexical searches like Full Text Search are very effective in achieving this. For situations where queries are vague, document repositories cover different domains, and documents contain overlapping keywords with semantic differences a hybrid search approach works well. By leveraging both lexical matching using full text search and semantic understanding using vector search, hybrid search provides the flexibility to adapt to a vast loop up space, and still provide good relevance and accuracy on the documents retrieved.
In this blog we’ll explore Full Text Search and how to combine it with Embedding Search to bring about Hybrid Search. For hybrid search document ranking, that fuses the scores from both Full Text Search and Embedding Search, we will look into Reciprocal Ranked Fusion and Convex Combination the two common metrics, their formulas and their SQL implementation.
Note: we will be referring to each row in a table as a document, due to the richness in textual data that each row contains.
Full text search, that scans the entire text for specific word matches, is particularly beneficial in scenarios where exact keyword matching is necessary. It functions by comparing the keywords in a query with those in the text of document records, focusing mainly on exact matches. This contrasts with semantic search, which uses vector embeddings to identify semantic similarities which would capture synonyms and word relationships.
In DuckDB, the FTS extension provides the means to search through strings, and this is done so by creating an Inverted Index.
An Inverted Index creates a map of the keywords to the id of the document records that contains the respective keyword. This speeds up search operations by first identifying the keywords present in the query string, matching them to the inverted index and thereby locating the documents that have these keywords. Now that the relevant documents are located, the next step is to figure out how to rank them since only the top N results are relevant for any search. The FTS extension implements the Okapi BM25 scoring function which scores a document based on the keyword terms appearing in each document. The score captures the number of times a keyword occurs, length of the document in words, average length of the documents in the collection and the number of documents that contain the keyword. An exact representation of the formula can be found over here. Note that this score does not capture the proximity or the arrangement of the keywords in the document. That being said, upon calculating the score for each document, it is then ranked to select the top N results as the most relevant documents to the query string.
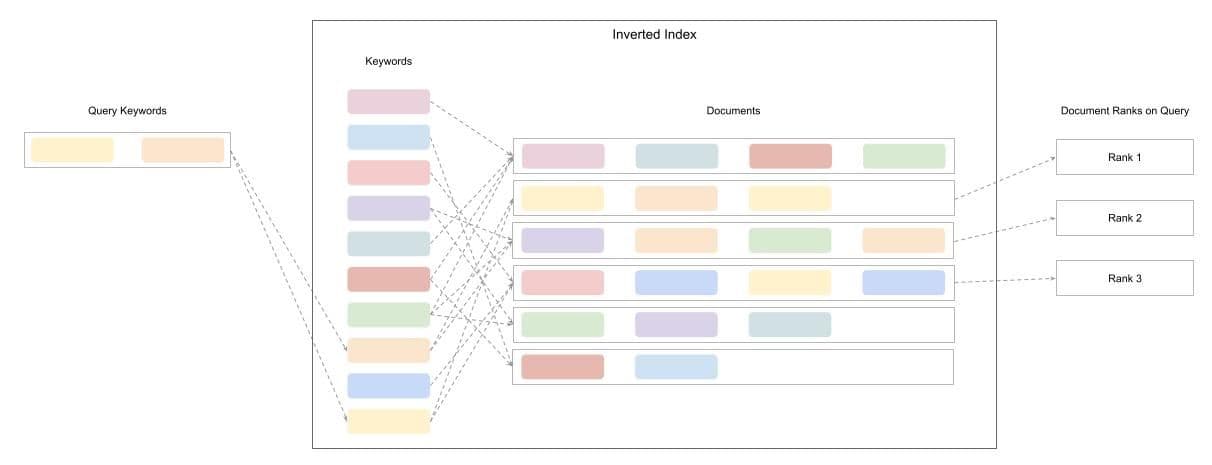
Figure 1: An illustration of how full text search creates the inverted index mapping keywords to documents and uses it for search. Consider the colored boxes as keywords.
For this blog, we’ll be using the Kaggle Movies dataset [1], the same one we used in the embedding search blog.
To load the dataset you have two options :
sample_data.kaggle.movies. Plus you leverage the power of the Cloud through MotherDuckLet’s first load in the dataset:
Copy code
create table movies as select title, overview
FROM 's3://us-prd-motherduck-open-datasets/movies/parquet/movies.parquet';
describe movies;
Copy code
| column_name | column_type | null | key | default | extra |
|-------------|-------------|------|------|---------|-------|
| title | VARCHAR | YES | NULL | NULL | NULL |
| overview | VARCHAR | YES | NULL | NULL | NULL |
| | | | | | |
FTS is available in DuckDB as an extension, and is autoloaded when the pragma below is called. This extension adds two PRAGMA statements one each to create and drop the FTS index. We can now create the index using:
Copy code
pragma create_fts_index(
input_table,
input_id,
* input_values,
stemmer = 'porter',
stopwords = 'english',
ignore = '(\\.|[^a-z])+',
strip_accents = 1,
lower = 1,
overwrite = 0
)
Note that create_fts_index will not work in the MotherDuck UI. The commands must be run using the DuckDB CLI or other clients.
The statement builds the index for the given table input_table and the mapping of the keywords to the documents is done using the input_id. The input_id would typically be a document identifier that is unique. Next we can specify what columns in the input_table to build the index for. There are a few optional arguments you can use to suit your custom use case. By default all characters are converted to lowercase and escape sequences are ignored. You can change the default behavior by using the optional parameters. To ignore character patterns in the textual data, you can pass in a regular expression to the ignore argument, which defaults to '(\\.|[^a-z])+' to ignore all escaped characters and non-alphabetic lowercase characters. Accents in your text data could also be removed and converted to characters without accents (example á to a) by setting strip_accents = 1 which defaults to 1. Setting lower = 1 converts all text to lowercase and overwrite = 0 overwrites an existing index. The optional arguments stemmer and stopwords are discussed in detail below. The pragma applies the normalization in the following order:
Copy code
strip_accents -> lowercase -> ignore_regex -> stemmer -> stopwords
Stemming is a process of simplifying words by removing common word endings from them. For example, the word running would be converted to run, cats to cat. This makes the search for keywords in their different forms much easier. DuckDB provides various stemmers, and defaults to stemmer = porter. There is also an option to disable this process of simplifying words by passing stemmer = none to the argument.
Stopwords are commonly used words in a language, and are often removed from the search context in keyword based search systems as they add very little value. In English, “a”, “is”, “the”, “are” are examples of some stopwords. The FTS extension defaults to using English stopwords, stopwords = ‘english’.
For our example dataset, let’s build the index for the columns title and overview using the title as the document identifier since this is a unique identifier for the rows in our table, while using the defaults for the optional arguments.
Copy code
pragma create_fts_index(movies, title, title, overview)
Upon executing this, a few tables are created on the same database as the input_table but in another schema, which is usually the name of the input_table with a prefix as fts_main_<input_table>. These newly created tables hold the inverted index for the full text search.
Copy code
select database, schema, name, column_names FROM (show all tables)
Copy code
| database | schema | name | column_names | column_types |
| -------- | --------------- | --------- | ------------------------ | ------------------------- |
| memory | fts_main_movies | dict | [termid, term, df] | [BIGINT, VARCHAR, BIGINT] |
| memory | fts_main_movies | docs | [docid, name, len] | [BIGINT, VARCHAR, BIGINT] |
| memory | fts_main_movies | fields | [fieldid, field] | [BIGINT, VARCHAR] |
| memory | fts_main_movies | stats | [num_docs, avgdl] | [BIGINT, DOUBLE] |
| memory | fts_main_movies | stopwords | [sw] | [VARCHAR] |
| memory | fts_main_movies | terms | [docid, fieldid, termid] | [BIGINT, BIGINT, BIGINT] |
| memory | main | movies | [title, overview] | [VARCHAR, VARCHAR] |
Exploring some of the newly created tables, we can see the effects of the parameters we chose when creating the FTS index. Below are some notes to understand each created table:
Copy code
| schema | name | column_names | | description |
| --------------- | --------- | ------------------------ | --- | ----------------------------------------------------------------------------------------------------------------------- |
| fts_main_movies | dict | [termid, term, df] | | stores a mapping of all the terms (keywords in the docs) to a termid |
| fts_main_movies | docs | [docid, name, len] | | creates a map of the input_id stored here as name to an internal docid for the FTS index along with the document length |
| fts_main_movies | fields | [fieldid, field] | | maps a fieldid to the table columns given in input_values that were indexed |
| fts_main_movies | stats | [num_docs, avgdl] | | stats used to calculate the similarity scores |
| fts_main_movies | stopwords | [sw] | | lists all the stopwords for this index, corresponding to the chosen option when creating the index |
| fts_main_movies | terms | [docid, fieldid, termid] | | maps the document docid to the field with fieldid (column) to the term with termid |
| main | movies | [title, overview] | | table that is indexed for the full text search
A note for the curious ones: these tables can be queried, inspected and used in other queries downstream.
When the PRAGMA create_fts_index is executed, a retrieval macro is created along with the index and associated with it. The macro looks as follows:
Copy code
match_bm25(
input_id,
query_string,
fields := NULL,
k := 1.2,
b := 0.75,
conjunctive := 0
)
This macro calculates the search score based on the Okapi bm25 as mentioned earlier, and takes the column names for the document identifier as input_id, with the input search string as query_string, the indexed column names as a string that contains the comma separated column names and NULL indicates to search across all the columns. The parameters k and b adjust the bm25 scoring and setting conjunctive = 1 ensures the search only retrieves documents that contain all the keywords in the query_string.
Using this macro, we can now search over our movies dataset for a query string:
adventure across the galaxy for the ultimate power struggle
and indicate the fields to limit the search as fields := ‘overview’.
Copy code
with fts as (
select *, fts_main_movies.match_bm25(
title,
'adventure across the galaxy for the ultimate power struggle',
fields := 'overview'
) as score
from movies
)
select title, overview, score
from fts
where score is not null
order by score desc
limit 5;
Which would return the top 5 result as:
Copy code
| title | overview | score |
| ------------------- | ------------------------------------------------------------------------ | ---------- |
| Mighty Morphin Pow… | Power up with six incredible teens who out-maneuver and defeat evil eve… | 5.73340016 |
| Threads of Destiny | 94 years after The Battle of Yavin, the New Republic has been resurrect… | 5.70256148 |
| Stargate: The Ark … | SG-1 searches for an ancient weapon which could help them defeat the Or… | 5.65603264 |
| The Final Master | Determined to pass down his art, the Final Master of Wing Chun is caugh… | 5.54863581 |
| Star Trek | The fate of the galaxy rests in the hands of bitter rivals. One, James … | 5.14211669 |
Now with both search modes, Full Text Search (this blog) and Embedding Search implemented in DuckDB, how do we combine them both for a hybrid search? Let’s get our dataset ready to start building our hybrid search. Taking the same movies dataset as above, we generate and add embedding vectors for both the title and the overview, and create the FTS index. At the end of this our movies table would contain:
Copy code
| column_name | column_type | null | key | default | extra |
| ------------------- | ----------- | ---- | ---- | ------- | ----- |
| title | VARCHAR | YES | NULL | NULL | NULL |
| overview | VARCHAR | YES | NULL | NULL | NULL |
| title_embeddings | DOUBLE[] | YES | NULL | NULL | NULL |
| overview_embeddings | DOUBLE[] | YES | NULL | NULL | NULL |
The crux of any search algorithm is to have a metric to rank the dataset for a given query, from which the top N values are retrieved when listed in descending order. For hybrid search we would require a metric that fuses scores from both search modes. Two of the most commonly used fusion metrics are: (i) convex combination and (ii) reciprocal ranked fusion.
RRF sums the reciprocals of the ranks of documents, where the rank of the document is the row number when sorted in descending order using a ranking score. To adjust the importance of the low ranked documents a constant k is added to the rank. This gives the formula for RRF as:

This method reportedly performs better than RRF when calibrated. It is expressed as a linear function that sums the normalized scores weighted against a parameter ⍺. The calibration of the parameter requires a good amount of annotated dataset, but with a lack of it we could use a default value of 0.8 as suggested in this paper [3] for in domain datasets. Which gives:

In this post, we will focus on using Convex Combination as it reportedly performs better, beyond the suggested value for ⍺, it is customizable for any use-case in hand, with a few annotated samples the parameter can be tuned.
Copy code
wiht fts as (
select
title,
overview,
fts_main_movies.match_bm25(
title,
'an adventure across the galaxy for the ultimate power struggle',
fields := 'overview'
) as score
from movies
),
embd as (
select
title,
overview,
array_cosine_similarity(overview_embeddings, cast([0.343.., ...] as float[1536])) as score
from movies
),
normalized_scores as (
select
fts.title,
fts.overview,
fts.score as raw_fts_score,
embd.score as raw_embd_score,
(fts.score / (select max(score) from fts)) as norm_fts_score,
((embd.score + 1) / (select max(score) + 1 from embd)) as norm_embd_score
from
fts
inner join
embd
on fts.title = embd.title
)
select
title,
raw_fts_score,
raw_embd_score,
norm_fts_score,
norm_embd_score,
-- (alpha * norm_embd_score + (1-alpha) * norm_fts_score)
(0.8*norm_embd_score + 0.2*norm_fts_score) AS score_cc
from
normalized_scores
order by
score_cc desc
limit 5;
We get the following top 5 results:
Copy code
| title | overview | norm_fts_score | norm_embd_score | score_cc |
| --------------------------------------- | ----------------------------------------------------------------------- | -------------- | --------------- | ---------- |
| Threads of Destiny | 94 years after The Battle of Yavin, the New Republic has been resurrec… | 0.99462122 | 1.0 | 0.99892424 |
| Stargate: The Ark of Truth | SG-1 searches for an ancient weapon which could help them defeat the O… | 0.98650582 | 0.97546876 | 0.97767617 |
| Star Trek | The fate of the galaxy rests in the hands of bitter rivals. One, James… | 0.89687036 | 0.98548452 | 0.96776169 |
| Mighty Morphin Power Rangers: The Movie | Power up with six incredible teens who out-maneuver and defeat evil ev… | 1.0 | 0.94973698 | 0.95978958 |
| Ratchet & Clank | Ratchet and Clank tells the story of two unlikely heroes as they strug… | 0.83376640 | 0.95988163 | 0.93465858 |
Comparing the hybrid results above with FTS, we notice that the top result differs after reranking and that the ranking is not determined solely by a single score. We also observe a new result in the top 5 that wasn’t present in the FTS-only search.
With more unstructured textual data being ingested into analytical database systems, it is increasingly important for these systems to handle text search operations efficiently. Advancements in DuckDB and the functions it provides out of the box make it an excellent analytical tool for both full text (keyword-based) and embedding-based searches. These search functionalities can be seamlessly implemented directly in SQL without resorting to other tools to construct such a query. Moreover, the use of Common Table Expressions (CTEs) enables the calculation of fused ranking metrics for the effective integration of hybrid search modes. Even with a long query at hand, CTEs make it easy to build these queries and debug them.
References
[1] Kaggle movies dataset, that has been cleaned to remove duplicates.
[2] https://plg.uwaterloo.ca/~gvcormac/cormacksigir09-rrf.pdf
2024/06/11 - MotherDuck team
Turbocharge DuckDB's efficiency with multiplayer cloud analytics

2024/06/19 - Mehdi Ouazza
Explore DuckDB Wasm for fast, in-browser analytical SQL. Learn how to instantiate the JS API, query Parquet files, and export data to CSV with zero latency.