4 Senior Data Engineers Answer 10 Top Reddit Questions
2025/10/30 - 27 min read
BYEvery day, thousands of data engineers scroll through r/dataengineering (174K members strong) looking for answers to the same fundamental questions: How do I prepare for interviews in this market? What do I do about data quality? Should I use a data warehouse or jump on the lakehouse bandwagon?
We analyzed the most-upvoted questions and concerns—the ones with hundreds of comments that capture the real challenges of data engineering life: the candid conversations about career progression, technical decisions, and navigating the constantly evolving data landscape.
Then we brought those questions to a roundtable of data engineering experts who've been in the field for years: Ben Rogojan (SeattleDataGuy's Newsletter), Julien Hurault (Ju Data Engineering Newsletter), Mehdi Ouazza (MotherDuck), and myself, Simon Späti (ssp.sh).
What emerged is genuinely exciting with practical wisdom from people who've faced these exact challenges. Whether you're navigating your first data engineering role or looking to level up, I think you'll find something valuable here.
NOTE: Thanks to SubTLDR Thanks to SubTLDR, created by Mehdi, I had access to the dataset with the most asked questions and discussions on Reddit, and could quickly check what the most upvoted and discussed topics on Reddit over the years were. If you want to keep updated on a monthly basis, make sure to subscribe to get updates on `r/dataengineering`, `r/MachineLearning` and `r/SQL` to your inbox, or check the website for the latest subTLDR's.Meet the Panel
Quick intro to the experts in this round, what we are doing, and also what developer environment we are using to get a feel for how we work.

Ben Rogojan
Ben, also known as the Seattle Data Guy on YouTube and online, has been working as a data engineer for over a decade. He keeps his feed always in the loop, consulting various data teams on infrastructure, helping them navigate, and writing and teaching online with one of the biggest newsletters and top-notch articles. He loves helping people and companies succeed with data, bridging between business and data.
Julien Hurault
Julien is a builder and the creator of Boring Semantic Layer and Composable Data Stacks. He created a Kickstarter for your data stack, enabling you to build it in weeks, not months, with pre-built Terraform templates. He is also the writer of the popular Ju Data Engineering Newsletter.
Mehdi Ouazza
Mehdi, aka mehdio, is a Data Engineer and Developer Advocate with nearly a decade of experience in the data field. He has worked with organizations ranging from large corporates like AXA to tech unicorns such as Klarna, Back Market, and Trade Republic. Since 2020, he has shared his passion for data through his blog and YouTube channel. As the first Developer Advocate at MotherDuck (DuckDB in the cloud), he focuses on making data engineering education fun and accessible for everyone.
Simon Späti
Simon is a Data Engineer and Technical Author with 20+ years of experience in the data field. He's the author of the Data Engineering Blog, curator of the Data Engineering Vault, and is currently writing a book about Data Engineering Design Patterns. Simon maintains an awareness of open-source data engineering technologies and enjoys sharing his knowledge with the community.
To set the stage, let's see what each developer environment looks like, such as the computer, preferred operating system (OS), SQL editor, terminal, and notable switches over time worth noting:
| Developer | Computer | OS | SQL Editor | Terminal | Notable Switches |
|---|---|---|---|---|---|
| Mehdi | Macbook Pro | MacOS | Cursor | Ghostty | - |
| Julien | Mac | Latest | Snowflake editor, VSCode for dbt, Pgadmin for postgres (he hates it 🙂) | zsh in VSCode | VSCode → Cursor → VSCode (+ CC) |
| Simon | Tuxedo IBP 14 AMD | Linux (Omarchy) | Neovim | Kitty with zsh | Claude Code as AI assistant |
| Ben | Mac | MacOS | Snowflake editor, VS Code, DB Beaver | iTerm2 or Terminal | Cursor added (but it depends on project) |
The following 10 questions are based on the most asked questions and concerns raised on Reddit, answered by Ben, Julien, Mehdi, and me, arranged in a way that makes them enjoyable to read, with an initial context as to why that question matters.
NOTE: Quick note to referencing myself as third person I will reference myself (Simon) in the third person below, to make the reading experience flow better.1. How Would You Prepare for an Interview if You Had to Apply for a Job Today?
NOTE: Context Given the rapidly evolving landscape of data engineering tools and practices and the harsh environment with minimal jobs and many who are searching, this is an important question to answer, especially for newcomers.Mehdi emphasized a focused approach on understanding the technical stack: "There's a lot to learn in the data space. Focus on the technical stack of the company you're applying to. Usually, you can ask about the high-level stack in the early stages. If you don't know specific tools, focus on the fundamentals: what problems do they solve, and what related knowledge do you possess?"
Julien says: "I'd start by checking which tools the company uses and getting a basic understanding of them. During the interview, I'd try to steer the discussion toward the underlying concepts behind those tools. For example, if the topic is open table formats and I only have experience with Iceberg, I'd make sure I understand the general principles. That way, I can confidently answer Delta Lake–related questions by connecting them back to those shared concepts. This approach works for many topics (warehouse, programming languages, clouds) and really broadens the range of interviews you can apply for."
Julien also shared his pro tip for getting past HR screening: "To get past the first round of selection (usually handled by HR), identify key keywords in the job description and include them everywhere throughout your CV and cover letter. It sounds simple, but it works — and it greatly increases your chances of moving to the next step."
Simon's perspective on building practical foundations: "I'd focus on some of the core fundamentals of data engineering. Looking at the data engineering lifecycle, I'd learn a tool for each part of the lifecycle: one for ingestion, one for transformation, one for serving/visualization, and then I'd implement a simple demo project for some data you are interested in. E.g., I started a real-estate project and included all my favorite open-source tools. Choosing a data set you're actually interested in helps you stay motivated, and you get valuable hands-on experience. During the interview, you can even reference that and try to zoom out and think more holistically—which fundamental data engineering skills did you just learn? Again, map your skills to the DE lifecycle as the fundamentals."
Ben's focus on a study plan: "Step zero is to create a study plan. I've done this in the past, and it helps you keep track of what you've actually done. Otherwise, you might think you've studied a lot, but really you haven't, or you might feel the opposite. Keeping track helps. Also, realize you can't study everything, so focus on the key concepts in programming, SQL, data modeling, and maybe a few tools. From there, step one, once I have an interview lined up, is to always ask the recruiter what types of questions to expect. A good recruiter or data team should be able to provide the types of questions. Will it be on data modeling, DSA, etc.? If you don't get good answers, then look online, see what the job description asked for, etc. Make sure you have a few stories ready to explain possible situational questions. It's really a bummer if you pass all the technical portions of an interview process but fail because you didn't have any good examples of possible wins, difficult situations you've overcome, and so on at hand."
The TLDR; Fundamentals and principles beat the latest tool or technology.
2. How Do You Deal with Data Quality? It Takes So Much Time, and Nobody Is Willing to Invest.
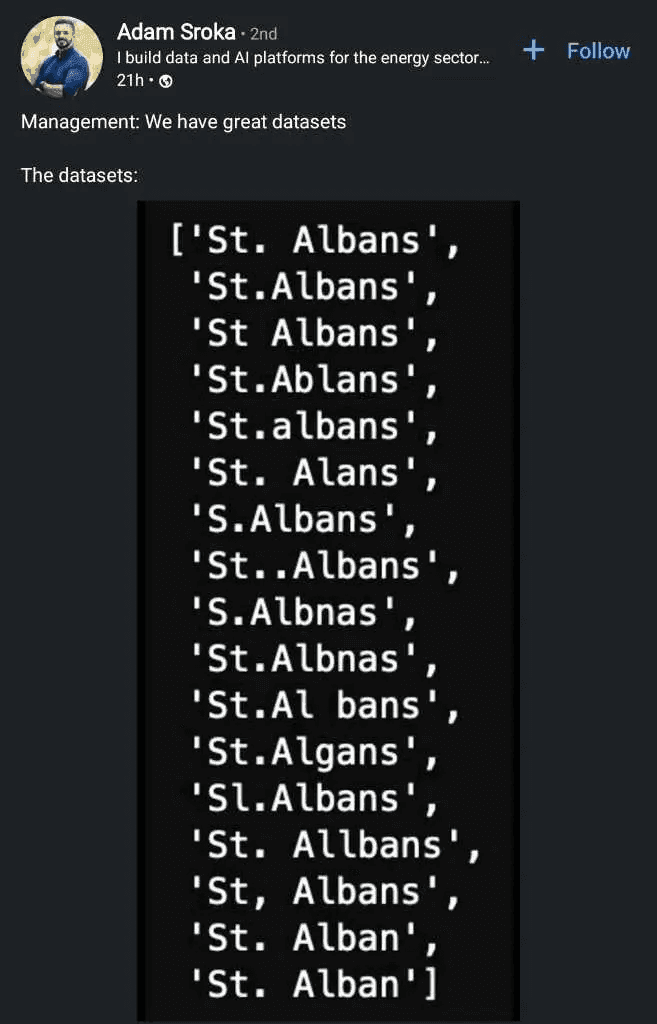
Mehdi on the importance of stakeholder context and WAP: "Data quality is important, especially when you have stakeholders like BI users. If you need to do ad-hoc analysis and know that 10% of the data may be wrong, that won't necessarily prevent you from making a good decision. However, as soon as stakeholders are involved, I recommend using the WAP technique: write, audit, publish. This means writing your data somewhere, running basic tests (like counting rows or checking for null columns), and then publishing. It's better to have no data than bad data."
Julien advocated for an iterative approach: "Start with a small set of basic tests, ship the pipeline, and add more tests as it fails. This way, you don't get stuck over-engineering from the start — you improve data quality iteratively, based on real issues instead of assumptions."
Simon notes that DQ can only be learned through experience: "I'd say this is a hard one. Data quality is something you only learn through experience. You must have seen bad data—really bad, I mean—to understand what data quality means. You need to understand granularity to understand duplications when you join two tables, or understand the business better to even know what quality data is and what useless data is. Talk to the business people as much as possible; ask them questions. I had the luck early in my career working in BI to always be in contact with business and domain experts. While working with them, I learned all about the data, and the longer I worked with the data, I naturally knew good data and its value, and I did everything to make it better and to explain to stakeholders not to neglect it. But getting more money and time is hard."
Ben's approach by focusing on key data sets: "To borrow a statement from the business, don't boil the ocean here. You want to make sure the data on which you rely is high quality. On the other hand, if you put thousands of warnings or notifications to go off when there is a data error for issues people will ignore, eventually, people will ignore all the warnings. Start by focusing on the data quality of your key data sets if that is a large issue for your use cases. Build test cases and data quality checks around it, and then continually keep adding where needed. This is a great place to have some form of data fixathon in place to encourage people to go back and add more checks where needed."
The TLDR; Getting data quality right is hard. Start simple and expand from it. Try to understand the business context first.
Extra Reddit threads: data duplicates, NULLs and duplicates, Data Quality Struggles
3. When Everyone Is Shouting Data Lakes or Lakehouse, How Do You Justify Using Data Warehouses That Just Work?

Mehdi emphasizes fast, responsive access: "Cloud data warehouses are powerful all-in-one tools, but costs can quickly escalate if used for processing and storing raw data. Many companies adopt a dual strategy, pushing only refined, 'gold-layer' data to the data warehouse when fast, responsive access to specific datasets is required."
Julien's notes on the best managed service: "It depends on the project's priorities. If the goal is to deliver under strict resource constraints — where every minute of your time counts — then you should build on top of the best managed services as much as possible. Right now, the best managed services are data warehouses. So, use a warehouse. In a couple of years, that might no longer be the case."
Simon on benefit-driven decisions: "I'd always focus on the benefits a new technique or approach brings to a current one. Then also, it's worth investigating how committed you've been to an existing approach and what features or requirements the current one can't cover. If the benefits outweigh the downsides, try to start with a new project that does not have existing implementations, so it's easier to start and verify when starting from scratch."
Ben's point that newest isn't always the best: "For the Data Lake point, I've often found many companies use those in conjunction with a data warehouse. So I am not sure if that is often a discussion I've had. On the side of data lakehouses, my focus would be to deliver what you know. Lakehouses can provide a lot of benefits, like open formats, broader types of data, and so on. But if your goal at the end of the day is to build an analytical platform that provides KPIs, reports, and dashboards with about 500 GBs of data, you could probably build that on a traditional data warehouse just fine. In the end, the best architecture isn't the newest one; it's the one that helps your team deliver value faster and more reliably."
The TLDR; Justify data warehouses or lakes or lakehouses through practical considerations rather than ideology and choose based on your constraints (cost vs. time vs. team capability).
4. Just a Small Schema Change, They Say. But How Do You Manage Not Breaking Existing (and Running) ETL Pipelines and Databases? Any Practical Tips?

Mehdi says to focus on people: "It's a people problem, not tooling. The reason things break is that upstream producers don't own the responsibility downstream for analytics. So this is a hard discussion to have with them. You need top-level support to make things happen. Tooling/process can be figured out later."
Julien on avoiding auto-update: "First, I always freeze the schema — I don't like auto-evolving anything. That means every schema change will break something… and that's fine. It might sound old-fashioned, but today you can easily have an AI draft the migration code for you. That way, you fully understand what's changing instead of relying on automated schema evolution, which silently builds up cognitive debt — and that can cost you a lot later. The best way to evolve a schema is to always create new columns and never edit existing ones. That way, you're always safe."
Simon, declaring it the hardest problem in data engineering: "This is probably one of the hardest problems for a data engineer to this date. The more unified and integrated your stack is, e.g., only one vendor, or having 100 downstream tools, the easier or harder it is. Usually, what ends up happening is that in the beginning it's easy and fast to change, until you start implementing rigid data pipelines or hard-code things in reports or SQL statements. Now you can't just change. And it's ultra hard to test, as you mostly find the bugs only in production. Either you are lucky to have production data on dev or test to catch them before, but then you have ultra-long run times as you have lots of data, or you have fast runtimes and tests but not a representative data set on test. I haven't found the perfect solution yet. Something like Data Contracts, or documenting your schemas and assigning a responsible person, can already go a long way. Especially communication! When something changes, a channel to inform downstream consumers, or introduce a process that eases people who produce the data to inform you (if it's even in the same company)."
Ben's point on adding checkpoints: "There are several types of schema changes. The two that stand out are removals of columns and additions of columns. I generally aim to create systems that allow for additions of columns without any issues. Removals, on the other hand, can cause all sorts of unforeseen problems downstream. So, in those cases, I prefer to set up pipelines that either fail or warn prior to these issues occurring. At Facebook, when we connected to MySQL tables that changed, we'd actually get an email telling us that a change occurred (I am sure now they have AI that just writes the diff for you, and you just need to push it). I will add one other point here. In some cases, you're pulling data from CSVs without a header row. Meaning, if you add columns, remove columns, or even if you just happen to change the order, you could face major issues. The data types might still align, meaning the data will load without an issue. This is why it's important to have data quality checks that look at the categories and the underlying data. For example, if you only expect there to be US states, make sure that's the only data you get in. In cases where the data is coming via SFTP from an external provider, this is even more important. I've had these files change suddenly (and without any prior warning) and you just have to be ready for it."
TLDR; It involves leadership and people with a clear strategy and communication on how to implement changes, and acknowledging the complexity—there's no one simple solution.
Extra Reddit threads: Teeny tiny update only
5. Everyone Wants a Quick Dashboard. Best Real-Time. And AI Driven, of Course. But Usually Time Is the Limiting Factor—How Do You Balance This?
NOTE: Context Stakeholder expectations often clash with technical reality. Everyone wants real-time, AI-powered dashboards delivered yesterday, but data engineering teams face limited time, resources, and technical constraints. This question explores how to manage expectations and prioritize effectively in a world where everything is "urgent."Mehdi explains how his first response is to always push back: "I'm always pushing back the need for 'real-time,' and it has worked 90% of the time. Especially if it's consumed by humans. 95% of the time, they won't make any meaningful decisions with such new fresh data except in critical environments/seasonal peaks (air traffic control, Black Friday for ecommerce, etc.). Streaming pipelines require much more data maturity, so it's best to push it back as far as possible."
Julien says to iterate from an MVP: "Just deliver a non-AI-driven, 'slow' dashboard, see what happens, and iterate from there. My approach is always to deliver first and iterate as fast as possible. Data engineers should build pipelines the same way startup founders build products. :)"
Simon elaborates on having good reasons to change architecture: "I have yet to find a really good reason to have instant real-time dashboards that justify the added complexity and really hard debugging effort, compared to a batch process that runs every 10 minutes or hourly. But then you have an easy way to handle backfills in case of errors, or when you need to historize data in a DWH, or other common requirements. Sure, there are adTech, sports events, or IoT where you need instant events, but these are truly the exceptions to me."
Ben on figuring out the actual goal: "There is a difference between want and need. Often, I find it's less of a balance and more about figuring out what the actual end goal is. For example, with real-time dashboards, I've found that if I ask why the end-user wants it real-time, most of the time the end-user wants it real-time at a specific time for a specific meeting, or they meant a daily or hourly pull."
TLDR; Push back on the first request that "real-time is a must" to avoid added complexity. It's not what's needed in most cases.
6. How Do You Approach Taking Over a Data Stack When the OG Creator Left?
NOTE: Context Inheriting someone else's data infrastructure is like being handed the keys to a mysterious machine with no manual. Documentation is sparse, tribal knowledge has walked out the door, and you're expected to keep everything running while figuring out how it all works. This scenario is more common than you'd think.Mehdi explains how to avoid this happening: "You don't 😅, to be honest. This is something you can either avoid by documenting and conducting knowledge-sharing sessions at your current job. If you are applying to a new job, ask how they handle this. There's always a risk, but in the end, if someone wrote gigantic SQL spaghetti and it falls on you, there's no option but to either leave the company or go through a hard time."
Julien says to accept legacy: "The biggest pitfall is trying to recreate everything to your 'taste.' Accept the legacy and adapt or improve one thing at a time, following the motto: 'don't touch what works today.' If you try to improve something that already works, you're taking a super high risk. First, you need to match the existing functionality, and only then start adding real value. Focus on new areas where your impact goes from 0 → 1, not 0.5 → 1, and learn to accept the existing legacy 'bad' code."
Simon emphasizes understanding the underlying business: "This happens all too often in DE. Even more so, the used tool might already not be maintained anymore. Usually, I learned that it is best to try to run it, document alongside, and directly plan to exchange things you know work better, or make a plan for how to improve, as otherwise you will maintain something you potentially won't understand forever (why decisions had been made), and won't improve the status quo. Again, talk to the business experts to understand the overall goal, not the CASE WHEN in an SQL statement, so you understand more broadly before the details."
Ben starts with understanding the why: "I work to understand the data stack from both the top down and bottom up. That is to say, I talk to the end-users who are using the dashboards, reports, or other products that sit on top of the data stack. My goal is to understand why various products exist and their role in the business. It also often exposes some business logic, why some decisions were made, and hopefully provides me with points of contact for future questions I'll have while going through the code base. From there, I'll go through the code base. If there is a diagram of how everything flows, I'll update it as required, and if not, I'll put one together. This exercise helps both myself and future developers see how data goes from point A to point B. From there, if anything needs to be changed, I create a list from highest to lowest priority and start updating as time allows. Generally, I don't recommend a complete rebuild, as you'll likely lose some business logic somewhere that only the original creator knows why it existed."
TLDR; The key seems to be documentation, either while implementing it or after you take over a stack, and also resisting the urge to rebuild everything immediately.
7. How Did You Learn Linux Skills? And What Are the Minimum Skills for Linux You Recommend? Or Are They Not Required
NOTE: Context Linux remains the backbone of most data infrastructure, yet many aspiring data engineers wonder how deep their Linux knowledge needs to go. With cloud platforms abstracting away much of the complexity, the question of what Linux skills are truly essential has become increasingly relevant.Mehdi advocates to learn locally on the machine: "I would say that navigating your local laptop using the terminal (creating, editing, and deleting files) are the basics. Bash scripting comes in handy when you need to automate tasks. Most skills can be learned quickly on the job, so I would just recommend sticking to the basics."
Julien says learn by doing: "By doing, like most people 🙂 — basic Bash for navigation and Vim for editing."
Simon explains how learning something hard might pay back down the line: "If you work more on the business side of data engineering, they are less relevant. But as a data engineer that does infra or automates things, you won't get around it. And the earlier you learn some basic commands in the terminal and know it's not that dangerous, the better. I have written what to learn; check out Linux DE Fundamentals. I'm also a big fan of Neovim—very hard initially, but very high payoff down the road. If you are able to exit vim, you'll be prepared to run any command in the terminal 😉"
Ben learned the hard way: "One of the early companies I worked for had a lot of semi-automated processes. Some of which crossed between Microsoft and Linux and required walking through a run-book to launch new versions of code to production. So, the hard way. In terms of what you need to know, being able to find your way around via Bash and automate some basic tasks will always be useful, and make sure you can exit Vim while saving."
TLDR; Basic terminal navigation and Bash are needed, and learned through practical experience rather than formal study.
8. How Do You Handle the "Can I Export It to Excel" Request by the Business?
NOTE: Context After building sophisticated visualizations and interactive dashboards, hearing "Can we export this to Excel?" can feel shattering. Yet this request is ubiquitous in business environments where Excel remains the universal tool of choice. Balancing modern data practices with practical business needs is an art form.Mehdi highlights the need for balance: "It's a balance. You don't want to forbid some stakeholders from using Excel as a last mile if they need to. But if they spent too much time there, there's probably some transformation that should be offloaded upstream through a proper data pipeline."
Julien embraces it as a first prototype: "That's perfect for a v0 — let people play with the data. Observe what they're building in Excel, gather requirements from there, and then gradually move that logic into a properly tested pipeline, iteratively."
Simon mentions the win-win aspect: "That is a hard one that I always wanted to avoid in the beginning. Even Access databases that had a built-in UI was something I had to deal with. Lots of VBA I have rewritten to SQL 🙈. But why, you might ask? I'd say, embrace Excel as early as possible; make it always an option to export, though not the most common goal (as you want to have a common understanding with a set of common numbers), but your users will love you :). And also, you might profit as power users will overengineer everything, but you might ask them for the Excel and get a validated number and ETL code for free, that you can integrate then into an ETL workflow and BI dashboard for everyone to see. So, win-win in the end."
Ben's not fighting Excel: "Most dashboards allow for this, so I don't completely fight it. But I often start my deliverables as a data export first, anyway. Whether it's just a few key numbers or a larger data set, it helps me walk through with the end-user what they'd actually want to do with the raw data if I gave it to them. How raw the data is will be dependent on how much the end-user likes munging through data themselves."
TLDR; Excel can be a valuable signal rather than a problem as the first impulse would suggest.
9. How Do You Save Cloud Costs? What Practices or Tools Do You Use?
NOTE: Context Cloud costs can spiral out of control quickly in data engineering. Many use DuckDB, e.g. the user from this question saved 79% on Snowflake BI spend with DuckDB.Mehdi explains to first ask the right questions: "Be knowledgeable about the footprint of your data stack and your data pipelines. How many pipelines are you running per day? What's the typical frequency? How large is the data you compute per day? What's the total size of your data? What are the largest used/unused datasets? Once you can answer some of these questions, optimizations are pretty trivial."
Julien emphasizes setting alarms: "Good FinOps practices: alerting to catch unexpected spend early, and hard limits to prevent runaway costs."
Simon on optimizing data flow: "This is a hard one too. You can't generalize. But usually, the better you understand data flow and how to model data, the cheaper it gets, regardless of the tools."
Ben provides key ways to approach this: "As a consultant, I often get asked to help reduce costs. There are a few key ways I've done so in the past: improved the performance of long-running queries as well as improved data models, removed overly nested views that are connected to dashboards that load live every time, changed ELT tools, consolidated tools and vendors, negotiated vendor prices."
TLDR; First, proactive monitoring and understanding where the cost comes from, and then optimize costs.
10. What's the One Most Important Insight You Learned Over the Years That You Want to Share with Readers, if You Can Only Choose One, That Makes Them a Better DE?

Mehdi on learning outside comfort zone: "The best data engineers step outside their technical comfort zone and engage with stakeholders. Whether they're software engineers, business teams, or others. Data engineering sits at the heart of so many things, and understanding how people actually use the data will take you much further than the average DE who only focuses on pipelines and infrastructure."
Julien on designing for recoverability: "Your pipeline will break — always think ahead about how you'd replay or backfill data. Maintenance is the most expensive part of any data platform, so designing for recoverability upfront pays off massively. And of course: document as if you'll take over the project alone tomorrow."
Simon on business-first: "Data modeling, and listening or asking questions to the business users. The technical stuff we can always figure out, even more so with Claude Code these days. But a good instinct and common sense can only be learned through experience and curiosity toward people."
Ben suggests thinking it through: "Don't let other companies' tech diagrams and system designs be the only thing that guides you. Not every problem requires a hammer, and part of your job is to think through what you're trying to build and which tools are best suited for it. I've seen far too many systems end up overcomplicated, bringing in ten tools where three would have done fine. Then, the team's job becomes focused on managing the tools instead of trying to deliver any value to the business."
TLDR; Look outward to stakeholders, understanding business needs while building in foreseeable technical failure to make recovery easier.
That's a Wrap
I (Simon) hope you enjoyed this format. A big thanks to Julien and Ben, who voluntarily spent time to enlighten us with their wisdom, and of course also to Mehdi, who was up for this format, connected us, and gave his expertise too.
It was a lot of fun for me putting this together, and I hope you can learn something. I'm interested in your opinion too: do you see it differently than any of us? Please comment wherever you found this article, or let me know on Slack or elsewhere.
If you haven't gotten enough answers, feel free to click on the Reddit badges above to follow along with the comments and discussions directly, where the source of each question came from.
Start using MotherDuck now!
PREVIOUS POSTS

2025/10/09 - Alex Monahan, Garrett O'Brien
DuckDB 1.4.1 and DuckLake 0.3 Land in MotherDuck: New SQL Syntax, Iceberg Interoperability, and Performance Gains
MotherDuck now supports DuckDB 1.4.1 and DuckLake 0.3, with new SQL syntax, faster sorting, Iceberg interoperability, and more. Read on for the highlights from these major releases.
