Exploring StackOverflow with DuckDB on MotherDuck (Part 2)
2023/10/02 - 11 min read
BYFrom Local to Cloud - Loading our Database into MotherDuck and Querying it with AI Prompts
In the first part of the series we looked at the full StackOverflow dump as an interesting dataset to explore with DuckDB. We downloaded the data, converted it to CSV and loaded it into DuckDB and explored tags, users and posts a bit before exporting the database to Parquet. Today we want to move from our local evironment to MotherDuck, where we want to look at importing these parquet files into a database, sharing that database with you and exploring the data with the new AI prompt features.
Getting started with MotherDuck
DuckDB itself is focusing on local, and in-process execution of the analytical database engine. While you can access remote data, it’s downloaded to your machine every time you access the remote files, so you really might want to move your DuckDB execution to where the data lives.
To make it easier to query data that resides in other, remote locations, MotherDuck offers a managed service that allows you to run DuckDB in the cloud.
With MotherDuck you can query the data on your cloud storage transparently as if it was local. But what’s even better, is you can join and combine local tables transparently with data in tables residing in the cloud. The MotherDuck UI runs a build of DuckDB WASM in your browser, so the operations in the database that can be executed and rendered locally, are executed inside your web-browser.
Here is a picture of the architecture from the documentation:
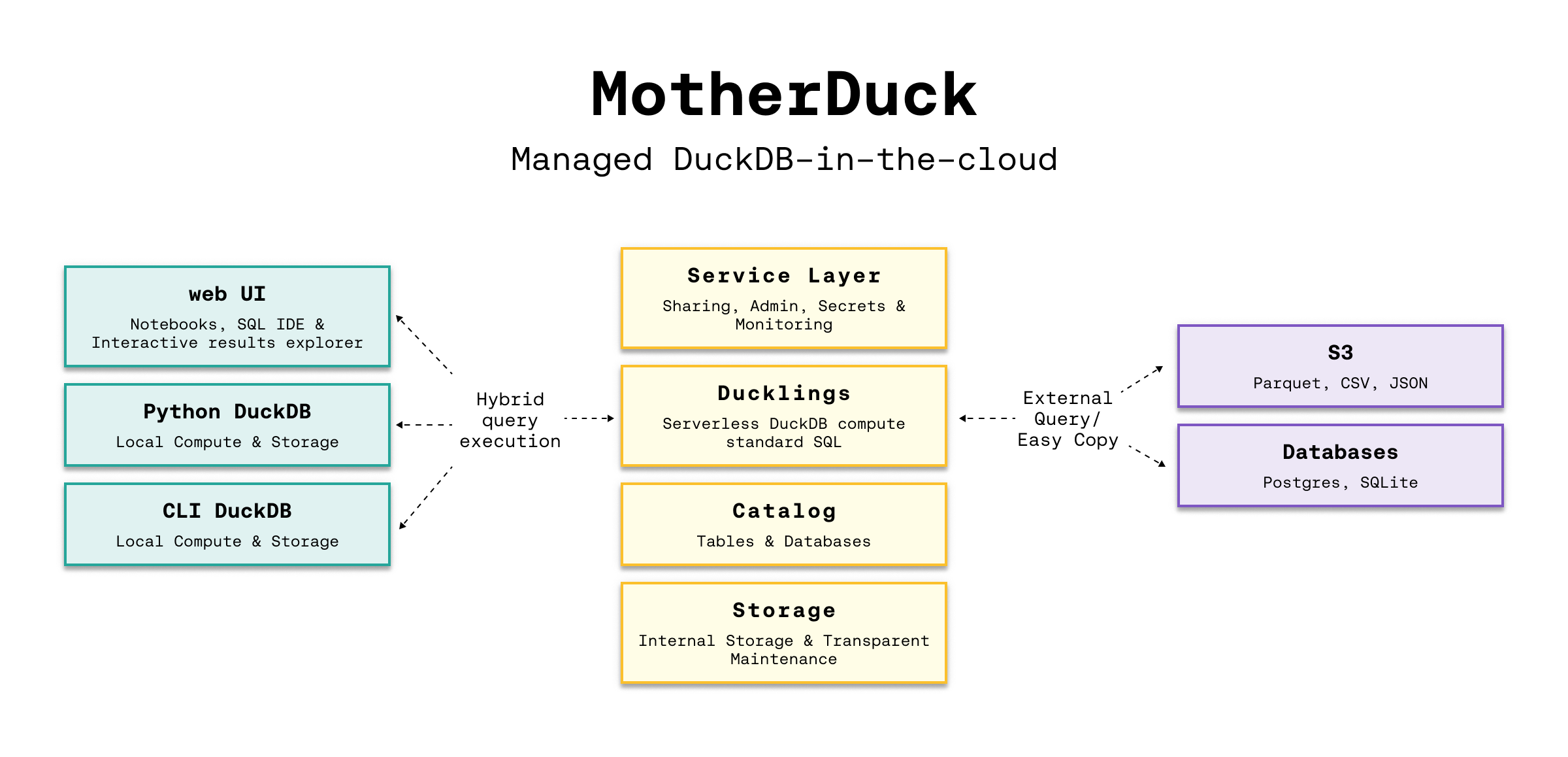
Motherduck also integrates with Python and all the other access libraries and integrations for DuckDB.
If you already signed up, you can just log-in to MotherDuck, otherwise you can create an account on the homepage (via Google, GitHub or email auth).
Anywhere you can run DuckDB you can use MotherDuck as it connects through an official DuckDB extension which is downloaded & loaded as soon as you connect to a motherduck database through .open md: or similar commands.
Copy code
.open md:
Attempting to automatically open the SSO authorization page
in your default browser.
1. Please open this link to login into your account:
https://auth.motherduck.com/activate
2. Enter the following code: XXXX-XXXX
Token successfully retrieved ✅
You can store it as an environment variable to avoid having to log in again:
$ export motherduck_token='eyJhbGciOiJI..._Jfo'
Once you have an account you get a motherduck_token, which you need to connect to MotherDuck. Best to set the token as an environment variable, instead of a database variable, because opening a new database wipes the settings in DuckDB (trust me, I tried).
If you want to explore the MotherDuck UI first, feel free to do so, you can create new databases, upload files and create tables from those. You can run queries and get a nice pivotable, sortable output table with inline frequency charts in the header.
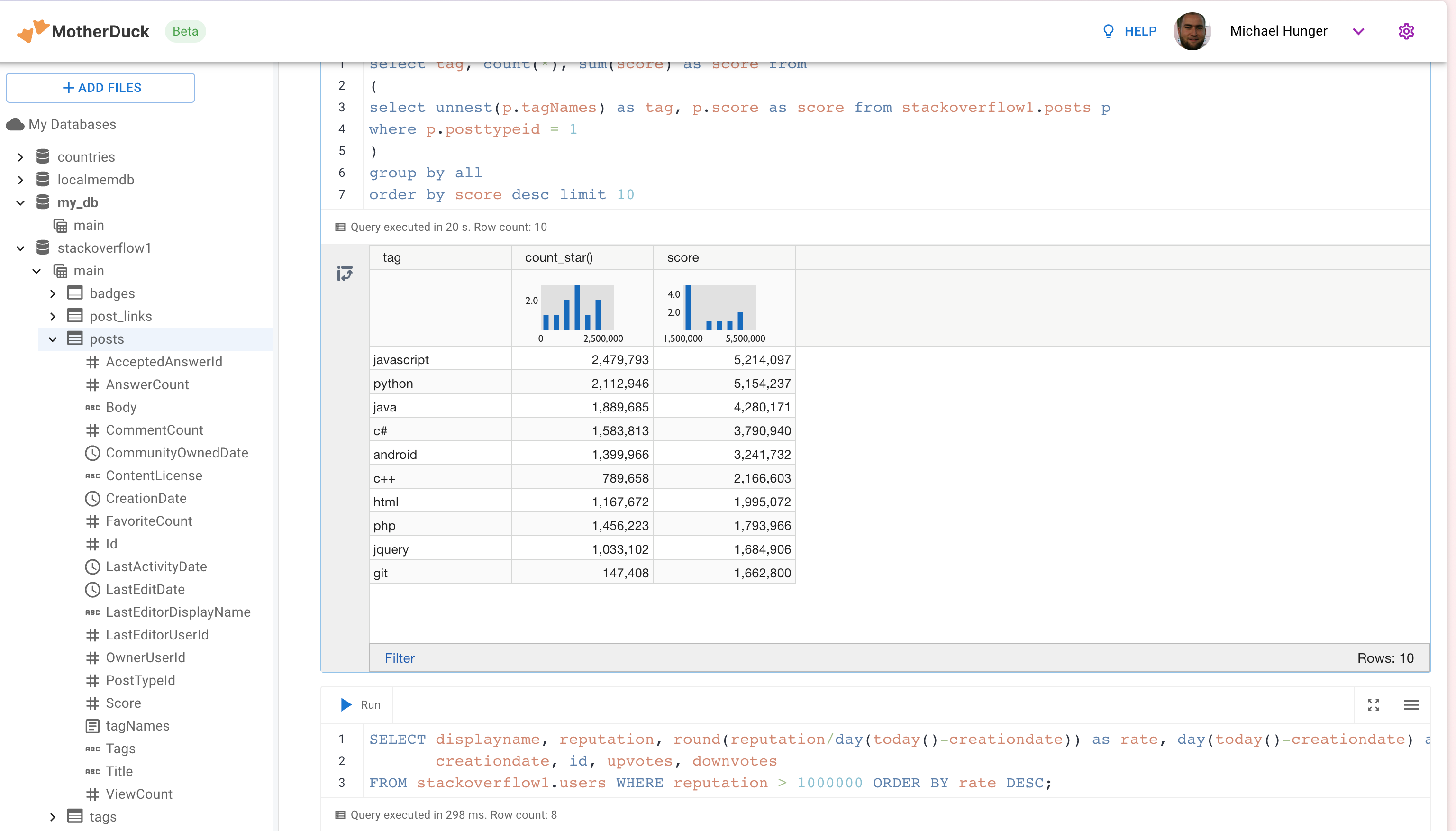
Loading our StackOverflow Data into MotherDuck
You have the option of uploading your local database with single command, which is really neat.
Copy code
CREATE DATABASE remote_database_name FROM CURRENT_DATABASE();
-- or more generally
CREATE DATABASE remote_database_name FROM '<local database name>';
There are only two caveats, the local and remote name must be different, otherwise you might get the error below.
Catalog Error: error while importing share: Schema with name <local-database-name> does not exist!
And for the size of our StackOverflow database and the it took quite some time to finish the upload, around 1 hour, sending 15GB of data for our 11GB database.
So we can either create the database on the MotherDuck UI and import our tables from our Parquet files on S3, or upload the database from our local system.
For creating the database and tables from Parquest, we use the web interface or DuckDB on the local machine, connected to MotherDuck. Here are the SQL commands you need to run.
Copy code
create database so;
create table users as
from 's3://us-prd-motherduck-open-datasets/stackoverflow/parquet/2023-05/users.parquet';
-- Run Time (s): real 10.401 user 0.006417 sys 0.003527
describe users;
┌────────────────┬─────────────┐
│ column_name │ column_type │
│ varchar │ varchar │
├────────────────┼─────────────┤
│ Id │ BIGINT │
│ Reputation │ BIGINT │
│ CreationDate │ TIMESTAMP │
│ DisplayName │ VARCHAR │
│ LastAccessDate │ TIMESTAMP │
│ AboutMe │ VARCHAR │
│ Views │ BIGINT │
│ UpVotes │ BIGINT │
│ DownVotes │ BIGINT │
│ Id │ BIGINT │
│ Reputation │ BIGINT │
│ CreationDate │ TIMESTAMP │
│ DisplayName │ VARCHAR │
│ LastAccessDate │ TIMESTAMP │
│ AboutMe │ VARCHAR │
│ Views │ BIGINT │
│ UpVotes │ BIGINT │
│ DownVotes │ BIGINT │
├────────────────┴─────────────┤
│ 18 rows │
└──────────────────────────────┘
Run Time (s): real 0.032 user 0.026184 sys 0.002383
-- do the same for the other tables
create table comments as
from 's3://us-prd-motherduck-open-datasets/stackoverflow/parquet/2023-05/comments.parquet';
create table posts as
from 's3://us-prd-motherduck-open-datasets/stackoverflow/parquet/2023-05/posts.parquet';
create table votes as
from 's3://us-prd-motherduck-open-datasets/stackoverflow/parquet/2023-05/votes.parquet';
create table badges as
from 's3://us-prd-motherduck-open-datasets/stackoverflow/parquet/2023-05/badges.parquet';
create table post_links as
from 's3://us-prd-motherduck-open-datasets/stackoverflow/parquet/2023-05/post_links.parquet';
create table tags as
from 's3://us-prd-motherduck-open-datasets/stackoverflow/parquet/2023-05/tags.parquet';
In the left sidebar of the web interface, now the database so and the tables should show up, if not, refresh the page.
Querying the Data with AI 🤖
A while ago MotherDuck released a new generative AI feature that allows you to
- query your data using natural language
- generate and fix SQL statements and
- describe your data.
As LLMs, GPT and foundational models are close to my heart, I was really excited to try these out.
It works actually already quite well, let’s see how it does on this dataset.
The schema description is a bit uninspiring, I could have seen the same by just looking at the table list. As expected from probabilistic models it returns different results on each run.
Copy code
CALL prompt_schema();
summary = The database contains information related to posts, comments, votes, badges, tags, post links, and users for a platform.
Run Time (s): real 1.476 user 0.001069 sys 0.000778
summary = The database schema represents a collection of data about various aspects of a community platform, including users, posts, comments, tags, badges, votes, and post links.
Ok, let’s try a simple question: What are the most popular tags?
Copy code
.mode duckbox
pragma prompt_query('What are the most popular tags?');
┌────────────┬─────────┐
│ TagName │ Count │
│ varchar │ int64 │
├────────────┼─────────┤
│ javascript │ 2479947 │
│ python │ 2113196 │
│ java │ 1889767 │
│ c# │ 1583879 │
│ php │ 1456271 │
│ android │ 1400026 │
│ html │ 1167742 │
│ jquery │ 1033113 │
│ c++ │ 789699 │
│ css │ 787138 │
├────────────┴─────────┤
│ 10 rows 2 columns │
└──────────────────────┘
-- Run Time (s): real 3.763 user 0.124567 sys 0.001716
Nice, what is the SQL it might have used for that (probabilistically it could have been slightly different)?
Copy code
.mode line
call prompt_sql('What are the most popular tags?');
-- query = SELECT TagName, Count FROM tags ORDER BY Count DESC LIMIT 5;
-- Run Time (s): real 2.813 user 2.808042 sys 0.005866
Looks good to me, it’s even smart enough to use the attribute and ordering and limit to get "most popular" tags. The runtime for these AI prompts is between 2 and 10 seconds almost exclusively depending on the processing time of the LLM.
That was pretty easy, so let’s see how it deals a few more involved questions.
- What question has the highest score and what are it’s other attributes?
- Which 5 questions have the most comments, what is the post title and comment count
Copy code
pragma prompt_query("What question has the highest score and what are it's other attributes?");
Id = 11227809
PostTypeId = 1
AcceptedAnswerId = 11227902
CreationDate = 2012-06-27 13:51:36.16
Score = 26903
ViewCount = 1796363
Body =
OwnerUserId = 87234
LastEditorUserId = 87234
LastEditorDisplayName =
LastEditDate = 2022-10-12 18:56:47.68
LastActivityDate = 2023-01-10 04:40:07.12
Title = Why is processing a sorted array faster than processing an unsorted array?
Tags = <java><c++><performance><cpu-architecture><branch-prediction>
AnswerCount = 26
CommentCount = 9
FavoriteCount = 0
CommunityOwnedDate =
ContentLicense = CC BY-SA 4.0
call prompt_sql("What question has the highest score and what are it's other attributes?");
query = SELECT *
FROM posts
WHERE PostTypeId = 1
ORDER BY Score DESC
LIMIT 1;
Run Time (s): real 3.683 user 0.001970 sys 0.000994
Ok, not bad, it’s nice that it detects that PostTypeId = 1 are questions (or known that from its training data on Stackoverflow), now lets go for the next one.
Copy code
.mode duckbox
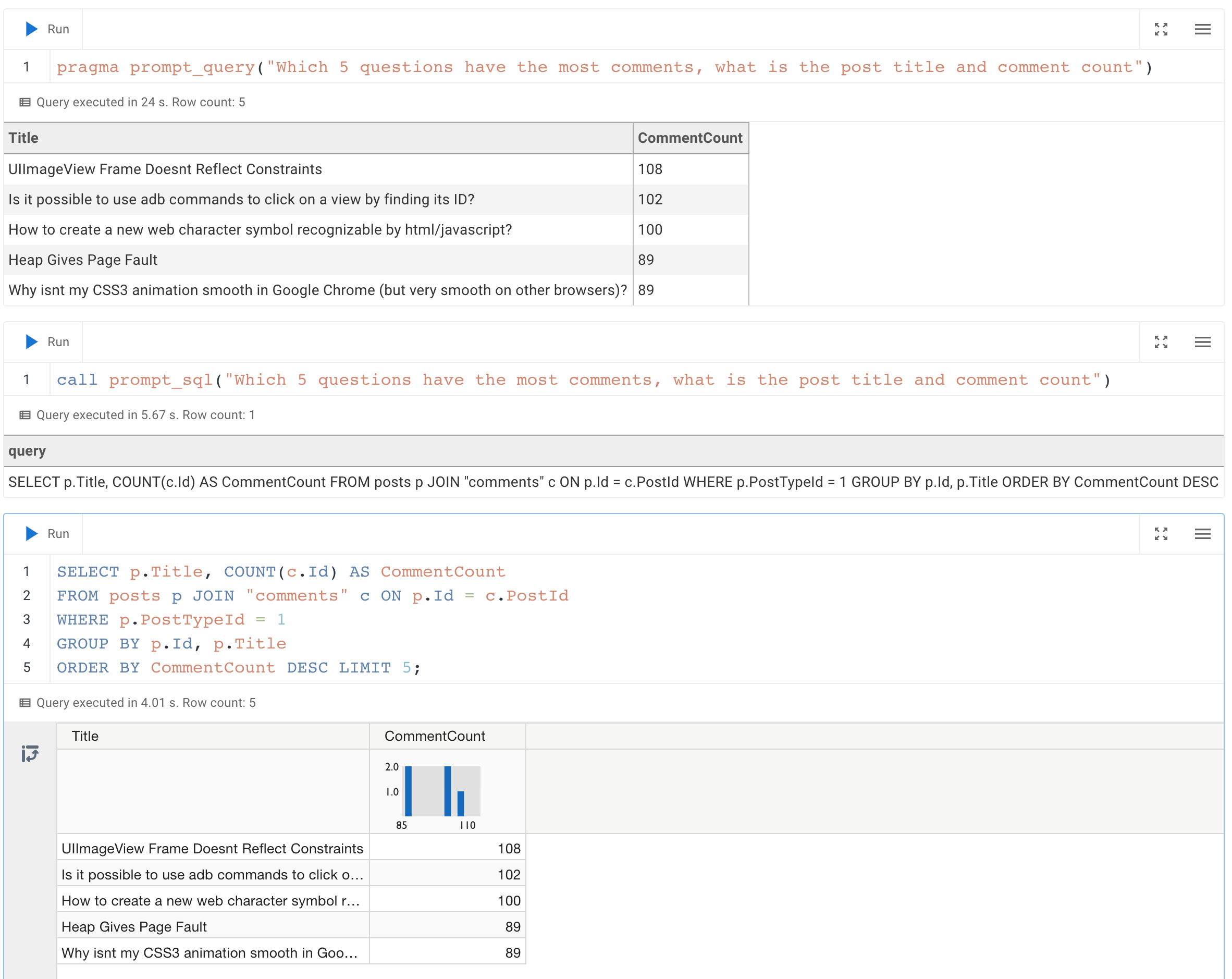
pragma prompt_query("Which 5 questions have the most comments, what is the post title and comment count");
┌───────────────────────────────────────────────────────────────────────────┬───────────────┐
│ Title │ comment_count │
│ varchar │ int64 │
├───────────────────────────────────────────────────────────────────────────┼───────────────┤
│ UIImageView Frame Doesnt Reflect Constraints │ 108 │
│ Is it possible to use adb commands to click on a view by finding its ID? │ 102 │
│ How to create a new web character symbol recognizable by html/javascript? │ 100 │
│ Why isnt my CSS3 animation smooth in Google Chrome (but very smooth on ot │ 89 │
│ Heap Gives Page Fault │ 89 │
└───────────────────────────────────────────────────────────────────────────┴───────────────┘
Run Time (s): real 19.695 user 2.406446 sys 0.018353
.mode line
call prompt_sql("Which 5 questions have the most comments, what is the post title and comment count");
query = SELECT p.Title, COUNT(c.Id) AS comment_count
FROM posts p
JOIN comments c ON p.Id = c.PostId AND p.PostTypeId = 1
GROUP BY p.Title
ORDER BY comment_count DESC
LIMIT 5;
Run Time (s): real 4.795 user 0.002301 sys 0.001346
This is what it looks like in the MotherDuck UI:
Actually the comment count is a column on the posts table, so it could have used that, let’s see if we can make it use only the one table.
Copy code
call prompt_sql("System: No joins! User: Which 5 questions have the most comments, what is the post title and comment count");
query = SELECT Title, CommentCount
FROM posts
WHERE PostTypeId = 1
ORDER BY CommentCount DESC
LIMIT 5;
Run Time (s): real 3.587 user 0.001733 sys 0.000865
Nice, that worked!
You can also use prompt_fixup to fix the SQL for a query, e.g. the infamous, "I forgot GROUP BY".
Copy code
call prompt_fixup("select postTypeId, count(*) from posts");
query = SELECT postTypeId, COUNT(*) FROM posts GROUP BY postTypeId
Run Time (s): real 12.006 user 0.004266 sys 0.002980
Or fixing a wrong join column name, or two.
Copy code
call prompt_fixup("select count(*) from posts join users on posts.userId = users.userId");
query = SELECT COUNT(*) FROM posts JOIN users ON posts.OwnerUserId = users.Id
Run Time (s): real 2.378 user 0.001770 sys 0.001067
That’s a really neat feature, hope they use it in their UI when your query would encounter an error with an explain in the background.
Data Sharing
To make this data available to others, we can use the CREATE SHARE command.
If we run it, we will get a shareable link, that others can use with ATTACH to attach our database. Currently it takes about a minute to create the share, but in the future it will be a zero-copy operation.
Copy code
-- CREATE SHARE <share name> [FROM <database name>];
CREATE SHARE so_2023_05 FROM so;
-- share_url = md:_share/so/373594a2-06f7-4c33-814e-cf59028482ca
-- Run Time (s): real 63.335 user 0.014849 sys 0.013110
-- ATTACH '<share URL>' [AS <database name>];
ATTACH 'md:_share/so/373594a2-06f7-4c33-814e-cf59028482ca' AS so;
-- show the contents of the share
DESCRIBE SHARE "so_2023_05";
LIST SHARES;
-- After making changes to the shared database, you need to update the share
UPDATE SHARE "so_2023_05";
Today we explored the MotherDuck interface, created a database and populated it with tables using Parquet data on S3. That worked really well and you should be able to do this with your own data easily.
Then we tried the new AI prompts on MotherDuck, which work quite well, of course not 100% but often good enough to get a starting point or learn something new. Given the amount of SQL information that was used to the train the LLMs plus the additional schema information, that is not surprising. SQL (derived from structured english query language SEQUEL) is just another langauge for the LLM to translate into, much like Korean or Klingon.
So while you’re waiting for the third part of the blog series, you can attach our share (which is public) and run your own queries on it.
In the third part we want to connect to our StackOverflow database on MotherDuck using Python and explore some more ways accessing, querying and visualizing our data.
Please share any interesting queries or issues on the MotherDuck Slack channel.
Start using MotherDuck now!

