
2024/11/12 - Simon Späti
15+ Companies Using DuckDB in Production: A Comprehensive Guide
Discover how companies are running DuckDB in production
- 10 min read
BY- 10 min read
BYDo you remember the good old times of Twitter? When you could fetch data through the API in real-time, allowing people to build tools on top of it. These times are back. Now, with Bluesky, you can do the same.
What is Bluesky? Bluesky is a social network like Twitter and Threads, but unlike them, it is fully open-source. It is growing by 1 million new users daily, and we can all follow along with the numbers and create new tools.
In this article, we do exactly that. We'll get analytics from Bluesky leveraging DuckDB and MotherDuck, and we'll explore the open APIs and streams so that you can build your own dashboards, tools, and visualizations. No one should stop you from getting your own insights from the data, and Bluesky is the perfect place to start.
Live post visualized in 3D, made with Bluesky Firehose
Bluesky is a social app for web, Android, and iOS, and leverages an innovative decentralized social networking protocol called ATProto. If Bluesky goes down, the protocol and your posts/data stay, and the new UI can be rebuilt. Two alternative UIs are already built on top of ATProto: Frontpage, an alternative Hackernews, and Smoke Signal, an RSVP management app.
These don't use all the features ATProto provides, but specific information about the user and information that helps the app serve its particular purpose. You can also start cross-using or displaying information from the protocol. For example, you could show posts with a specific hashtag or people from a particular area for each meetup. The use cases are endless.
Another feature that Bluesky and ATProto have is decentralization. Bluesky revolutionized this with the ATProto. Although, by default, the content is hosted on the Bluesky Personal Data Server (PDS) server, everyone can host their content on their server, and the interface is your handle, the same as it was with the web.
Interestingly, this approach is a return to the old web, giving more power to the people and moving away from prominent social media companies that control everything. Dan illustrates this best in his video about Web Without Walls, showcasing it with blogs you own, interlinked to other blogs and websites from your server to the other. Today, centralized social media platforms host and own all your content on their servers; without them, your content is lost, too.
 Illustration going from websites to centralized social media platforms to a decentralized AT Protocol.
Illustration going from websites to centralized social media platforms to a decentralized AT Protocol.
Decentralization and hosting of your server are achieved through the so-called Personal Data Server (PDS), which is also open-source. Interestingly, each user's data is implemented and stored with a single SQLite database. This means there are around 19 million as of now, but when you run your own, you could implement it with any backend, e.g., DuckDB. 😉
Check out ATProto Browser to see all artifacts attached to the protocol.
Check all your artifacts, such as posts, likes, etc., on the ATProto Browser, such as the events mentioned above or Frontpage interactions. E.g., for my handle, this looks like this:
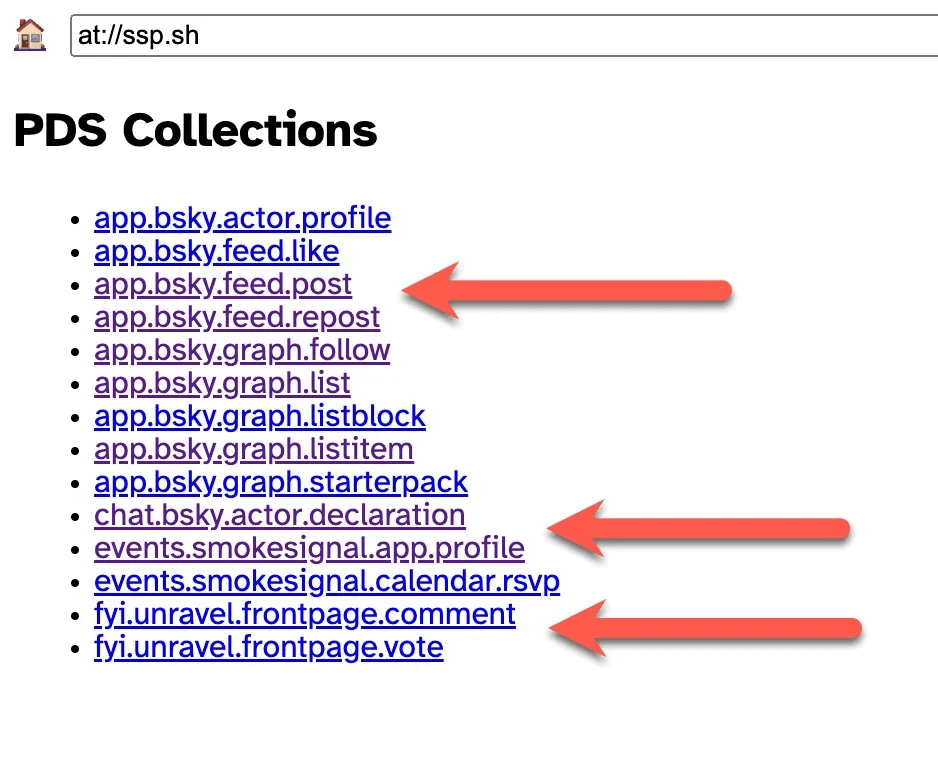
Before we get into some code examples, here is a quick note on the philosophy behind Bluesky and how it differs from Twitter, Instagram, and LinkedIn. Instead of one colossal algorithm deciding what we see and what not, Bluesky works based on people and feeds. The feeds are either created by Bluesky (e.g., popular with friends, quiet posters, likes of likes, etc.) or can be created by users themselves.
This way, you are in control of what you see. The "Discover" feed is closest to other social media algorithms.
Let's have some fun.
Not only is everything open-source but the APIs and Jetstreams (streams of posts, likes, etc.) can also be queried for free. Let's explore some hands-on examples.
To illustrate, you can simply read the post with DuckDB - e.g. reading my last 5 posts
Copy code
SELECT * FROM read_json_auto('https://public.api.bsky.app/xrpc/app.bsky.feed.getAuthorFeed?actor=did:plc:edglm4muiyzty2snc55ysuqx&limit=10')
The read_json_auto works on any JSON file and API endpoint if there aren't any http headers or other things that need to be set.
To find the unique Bluesky-ID, aka the Decentralized Identifier (DID) that you need for the above query we need to do another GET request to https://public.api.bsky.app/xrpc/com.atproto.identity.resolveHandle?handle=my_handle
Copy code
D SELECT * FROM read_json_auto('https://public.api.bsky.app/xrpc/com.atproto.identity.resolveHandle?handle=ssp.sh');
┌──────────────────────────────────┐
│ did │
│ varchar │
├──────────────────────────────────┤
│ did:plc:edglm4muiyzty2snc55ysuqx │
└──────────────────────────────────┘
D
It's worth noting that there's also a community DuckDB extension for HTTP requests, which is more powerful and allows you to set headers, etc. You can install it with INSTALL http_client FROM community; and then use it with http_get or http_post.
Copy code
INSTALL http_client FROM community;
LOAD http_client;
WITH __input AS (
SELECT
http_get('https://public.api.bsky.app/xrpc/com.atproto.identity.resolveHandle?handle=ssp.sh') AS res
)
SELECT
res::json->>'body' as identity_json
FROM __input;
identity_json
------------------------------------------
{"did":"did:plc:edglm4muiyzty2snc55ysuqx"}
Getting your feed then will be just another request to this endpoint,https://public.api.bsky.app/xrpc/app.bsky.feed.getAuthorFeed?actor=<my_did>&limit=100 with your DID.
To read the most engaging posts with this endpoint and plot a little bar chart that comes with DuckDB included, we can create a MACRO as follows.
Copy code
-- setting the did value as variable
SET variable did_value = 'did:plc:edglm4muiyzty2snc55ysuqx';
Copy code
CREATE MACRO get_engagement_data(did_value) AS TABLE (
WITH raw_data AS (
-- Use the DID parameter to construct the URL
SELECT * FROM read_json_auto(
'https://public.api.bsky.app/xrpc/app.bsky.feed.getAuthorFeed?actor=' || did_value || '&limit=100'
)
),
unnested_feed AS (
SELECT unnest(feed) AS post_data FROM raw_data
),
engagement_data AS (
SELECT
RIGHT(post_data.post.uri, 13) AS post_uri,
post_data.post.author.handle,
LEFT(post_data.post.record.text, 50) AS post_text,
post_data.post.record.createdAt AS created_at,
(post_data.post.replyCount +
post_data.post.repostCount +
post_data.post.likeCount +
post_data.post.quoteCount) AS total_engagement,
post_data.post.replyCount AS replies,
post_data.post.repostCount AS reposts,
post_data.post.likeCount AS likes,
post_data.post.quoteCount AS quotes
FROM unnested_feed
)
SELECT
post_uri,
created_at,
total_engagement,
bar(total_engagement, 0,
(SELECT MAX(total_engagement) FROM engagement_data),
30) AS engagement_chart,
replies, reposts, likes, quotes,
post_text
FROM engagement_data
ORDER BY total_engagement DESC
LIMIT 30
);
Copy code
SELECT * FROM get_engagement_data(getvariable('did_value'));
That looks something like this:

Note: The API limit is around 100, so if you want more than 100, you'll need to paginate or write code.
If you want all the posts, you can use the Python SDK to interact with the AT Protocol.
You can subscribe to the stream with this snippet: firehose.py.
It will stream everything and looks like this:
 If you want a stream dedicated to hashtags, for instance, #datasky and #databs, check the code snippet hashtag_databs.py, which captures all posts sent with these hashtags.
If you want a stream dedicated to hashtags, for instance, #datasky and #databs, check the code snippet hashtag_databs.py, which captures all posts sent with these hashtags.
I also created streaming_into_motherduckdb.py that lists both hashtags, writes them to parquet files and uploads them to a public DuckDB database hosted on MotherDuck. If you create an account for free, you can query my shared DuckDB database with ATTACH 'md:_share/bsky/c07e1ca0-6b51-4906-96cd-b310ec35e562' as md_bsky and query a couple of posts I uploaded for test.
Copy code
❯ duckdb
D ATTACH 'md:_share/bsky/c07e1ca0-6b51-4906-96cd-b310ec35e562' as md_bsky;
D from md_bsky.posts limit 5;
┌──────────────────────┬──────────────────────┬──────────────────────┬──────────────────────┬──────────────────────┬──────────────────────┬─────────┬─────────┐
│ uri │ cid │ author │ text │ created_at │ indexed_at │ hashtag │ langs │
│ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │ varchar │
├──────────────────────┼──────────────────────┼──────────────────────┼──────────────────────┼──────────────────────┼──────────────────────┼─────────┼─────────┤
│ at://did:plc:6czr5… │ bafyreiddu2muv2yo5… │ bramz.bsky.social │ #databs, what Pyth… │ 2024-11-18T08:52:4… │ 2024-11-18T08:52:4… │ databs │ en │
│ at://did:plc:edglm… │ bafyreiebsxxsgtzba… │ ssp.sh │ #databs test :) │ 2024-11-18T08:31:5… │ 2024-11-18T08:31:5… │ databs │ en │
│ at://did:plc:jfda6… │ bafyreifizd4lxahgq… │ victorsothervector… │ (last thing before… │ 2024-11-18T07:48:1… │ 2024-11-18T07:48:1… │ databs │ en │
│ at://did:plc:iyv5h… │ bafyreifieocd3grqb… │ rkv2401.bsky.social │ Does anyone know o… │ 2024-11-18T06:59:0… │ 2024-11-18T06:59:0… │ databs │ en │
│ at://did:plc:je4jm… │ bafyreics4cctwgzw6… │ maninekkalapudi.io │ Entering the dark … │ 2024-11-18T03:51:5… │ 2024-11-18T03:51:5… │ databs │ en │
└──────────────────────┴──────────────────────┴──────────────────────┴──────────────────────┴──────────────────────┴──────────────────────┴─────────┴─────────┘
You could do the same within MotherDuck's platform and make use of the visualization features and the benefits of the collaborative notebook approach.
You can also use Jake's great collection, where he shares the Jetstream as Cloudflare R2 to query openly with DuckDB:
Copy code
❯ duckdb
D attach 'https://hive.buz.dev/bluesky/catalog' as bsky;
select count(*) from bsky.jetstream;
100% ▕████████████████████████████████████████████████████████████▏
D select count(*) from bsky.jetstream;
┌──────────────┐
│ count_star() │
│ int64 │
├──────────────┤
│ 500000 │
└──────────────┘
It also works in the browser - check it here DuckDB Wasm – DuckDB:
 Image by Jake
Image by Jake
There are currently many collaboration efforts going on, and hourly, new things are shared among the new, friendly Bluesky community. Many people try to help each other and build the best data tooling around Bluesky and ATProto. Here is the one I came across lately (I'm sorry if I forgot anyone):
#databs and datasky hereI hope we can work together collaboratively and build the best Bluesky tools for data people. If not us, then who? 😀
2024/11/12 - Simon Späti
Discover how companies are running DuckDB in production
2024/11/14 - Mehdi Ouazza
Discover how catalog became crucial for Lakehouse and how DuckDB can help as a catalog