LLM-driven data pipelines with prompt() in MotherDuck and dbt
2024/12/12 - 7 min read
BYA large portion of an organization’s data often exists in unstructured form - text - making it hard to analyze when compared to well-organized, formatted, structured data. In the past, analyzing such unstructured data posed a significant challenge due to complex or otherwise limited tooling. However, with large language models (LLMs), transforming and analyzing unstructured data is now much more accessible. These models can extract valuable information and produce structured, typed outputs from unstructured sources, greatly simplifying the data transformation process.
We released the prompt() function a few weeks ago, which enables transforming unstructured data sitting in a data warehouse into structured data that can be easily analyzed. This function applies LLM-based operations to each row in a dataset, while automatically handling parallel model requests, batching, and data type conversions in the background.

For example (see figure above), consider a single customer’s product review. It can be transformed to extract multiple attributes. When thousands of such reviews undergo the same process, these extracted attributes can be aggregated to enable a more detailed analysis.
Integrating into SQL-Driven Interfaces
By offering a SQL-based API to large language models, the prompt() function makes it straightforward to incorporate unstructured data transformations into any SQL-driven environment. Analytical platforms, BI dashboards, and even frameworks like dbt can be integrated easily. In this blog, we’ll show you how to set up a dbt pipeline to extract and analyze unstructured data with SQL.
prompt() in a dbt project
We’ll work with a sample of Toys and Games reviews from the Amazon dataset available here: https://amazon-reviews-2023.github.io/. Here is a preview of the raw reviews:
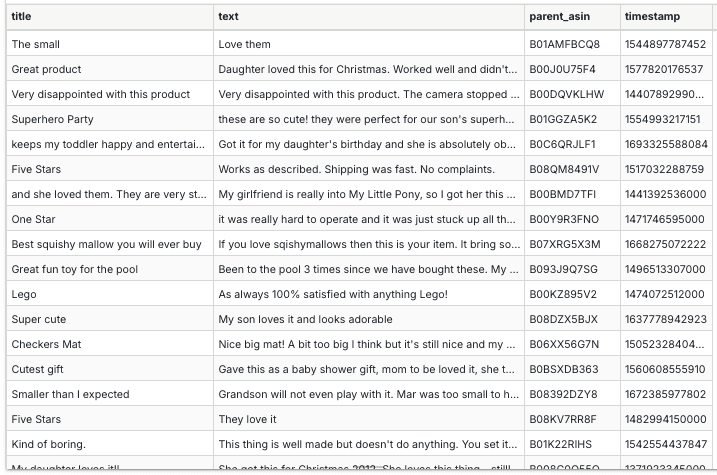
An extraction and transformation model for the above reviews would look like the following:
Copy code
{{ config(materialized="table") }}
select parent_asin, prompt_struct_response.*
from
(
select
parent_asin,
prompt(
'You are a very helpful assistant. You are given a product review title and test.\n'
|| 'You are required to extract information from the review.\n'
|| 'Here is the title of the review:'
|| '```'
|| title
|| '```'
|| 'Here is the review text:'
|| '```'
|| 'text'
|| '```',
struct := {
-- Sentiment
sentiment:'VARCHAR',
-- Feature mentions
product_features:'VARCHAR[]',
pros:'VARCHAR[]',
cons:'VARCHAR[]',
-- Quality indicators
has_size_info:'BOOLEAN',
mentions_price:'BOOLEAN',
mentions_shipping:'BOOLEAN',
mentions_packaging:'BOOLEAN',
-- Comparative analysis
competitor_mentions:'VARCHAR[]',
previous_version_comparison:'BOOLEAN',
-- Usage context
use_case:'VARCHAR[]',
purchase_reason:'VARCHAR[]',
time_owned:'VARCHAR',
-- Issues and concerns
reported_issues:'VARCHAR[]',
quality_concerns:'VARCHAR[]',
-- Customer service interaction
customer_service_interaction:'BOOLEAN',
customer_service_sentiment:'VARCHAR'
},
struct_descr := {
sentiment:'the sentiment of the review, can only take values `positive`, `neutral` or `negative`',
product_features:'a list of features mentioned in the review, if none mentioned return empty array',
pros:'a list of pros or positive aspects mentioned in the review, if none mentioned return empty array',
cons:'a list of cons or negative aspects mentioned in the review, if none mentioned return empty array',
has_size_info:'indicates if the review mentions size information',
mentions_price:'indicates if the review mentions price information',
mentions_shipping:'indicates if the review mentions shipping information',
mentions_packaging:'indicates if the review mentions packaging information',
competitor_mentions:'a list of competitors mentioned in the review, if none mentioned return empty array',
previous_version_comparison:'indicates if the review compares the product to a previous version',
use_case:'a list of use cases mentioned in the review, if none return empty array',
purchase_reason:'a list of purchase reasons mentioned in the review, if none return empty array',
time_owned:'the time the reviewer has owned the product, if mentioned return the time what ever was written in text, if not mentioned return empty string',
reported_issues:'a list of issues reported in the review, if none return empty array',
quality_concerns:'a list of quality concerns mentioned in the review, if none return empty array',
customer_service_interaction:'indicates if the review mentions customer service interaction',
customer_service_sentiment:'the sentiment of the customer service interaction, can only take values `positive`, `neutral` or `negative`'
}
) as prompt_struct_response
from reviews_raw
)
Here, the prompt() function takes the review’s title and text along with the expected return struct format. The struct_descr describes each attribute of that struct, giving additional context to the model to extract the data. Together, the struct format and struct_descr are responsible for getting the structured response from the model. Upon running this, we get a table with all the attributes destructured into their respective columns. (Note: in DuckDB to unnest a struct you can make use of the .* operator on the struct type column)
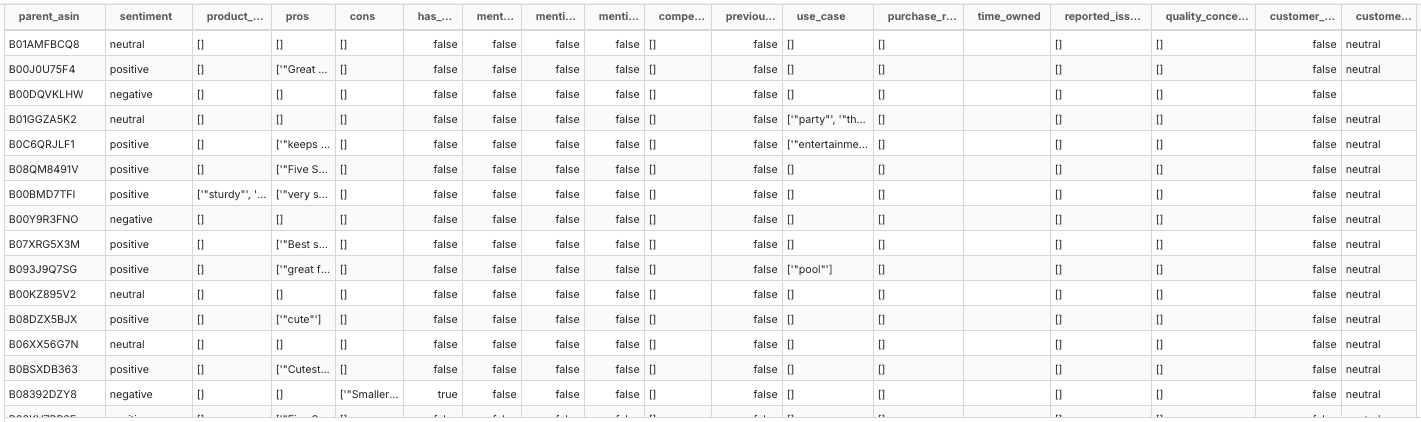
This enables more detailed product-level analysis. For instance, we can group list-type attributes by product and determine their distinct values. Using DuckDB’s unnest, array_agg, and array_distinct functions, we can expand, aggregate, and refine these lists to unique entries.
Copy code
{{ config(materialized="view") }}
with
unnested_array_attributes as (
-- First unnest all arrays to get individual attributes
select
parent_asin,
-- Feature mentions
unnest(product_features) as product_features,
unnest(pros) as pros,
unnest(cons) as cons,
-- Comparative analysis
unnest(competitor_mentions) as competitor_mentions,
-- Usage context
unnest(use_case) as use_case,
unnest(purchase_reason) as purchase_reason,
unnest(reported_issues) as reported_issues,
unnest(quality_concerns) as quality_concerns
from {{ ref("reviews_attributes") }}
)
select
parent_asin,
-- Feature mentions
array_distinct(array_agg(product_features)) as product_features,
array_distinct(array_agg(pros)) as pros,
array_distinct(array_agg(cons)) as cons,
-- Comparative analysis
array_distinct(array_agg(competitor_mentions)) as competitor_mentions,
-- Usage context
array_distinct(array_agg(use_case)) as use_case,
array_distinct(array_agg(purchase_reason)) as purchase_reason,
array_distinct(array_agg(reported_issues)) as reported_issues,
array_distinct(array_agg(quality_concerns)) as quality_concerns
from unnested_array_attributes
group by parent_asin
Another opportunity with these extracted attributes is to aggregate boolean and numeric values across the table to produce certain metrics. For example, we could derive sentiment metrics from the sample dataset like this:
Copy code
{{ config(materialized="view") }}
SELECT
parent_asin,
COUNT(CASE WHEN sentiment = 'positive' THEN 1 END) as positive_count,
COUNT(CASE WHEN sentiment = 'neutral' THEN 1 END) as neutral_count,
COUNT(CASE WHEN sentiment = 'negative' THEN 1 END) as negative_count,
(positive_count - negative_count)::FLOAT / NULLIF(positive_count + neutral_count + negative_count, 0) as sentiment_score,
COUNT(CASE WHEN customer_service_sentiment = 'positive' THEN 1 END) as positive_service_count,
COUNT(CASE WHEN customer_service_sentiment = 'neutral' THEN 1 END) as neutral_service_count,
COUNT(CASE WHEN customer_service_sentiment = 'negative' THEN 1 END) as negative_service_count,
(positive_service_count - negative_service_count)::FLOAT / NULLIF(positive_service_count + neutral_service_count + negative_service_count, 0) as service_sentiment_score,
FROM {{ ref("reviews_attributes") }}
GROUP BY parent_asin
You would’ve noticed above that the last two models are materialized as views, which is effective for frequently changing datasets. Views query the underlying data dynamically, ensuring up-to-date results without duplicating tables.
Incremental updates
By default, dbt runs full refreshes, which recreates the table each time the model is executed. This approach isn't practical for running LLMs on thousands of rows repeatedly. Instead, we can configure incremental updates by setting materialized='incremental', which tells dbt to append to the table if it already exists. Developers must however define which rows the model should process, typically using a timestamp column to track data freshness. dbt’s is_incremental() function allows conditional logic in a sql query, executing specific statements only when the table already exists - that is, for incremental updates. For our demo, we could set the materialization to incremental, use an event_timestamp column to track freshness, and apply the model only to rows with timestamps greater than the current maximum in the table. As an example, the following could represent the transformation model for incremental updates:
Copy code
{{
config(
materialized='incremental'
)
}}
select parent_asin, event_timestamp, prompt_struct_response.*
from
(
select
parent_asin,
event_timestamp,
prompt(
...slow_function...
) as prompt_struct_response
from reviews_raw
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where event_timestamp >= ( select max(event_time) from {{ this }} )
{% endif %}
)
Thanks to dbt’s incremental and full-refresh options, you can batch ingest only the latest data daily, saving costs and time, while still having the flexibility to reprocess all rows with a single command (dbt run model --full-refresh) if you update your prompt.
If you're curious about the implementation, check out the sample project in our GitHub repository here. The project has details on setting up dbt with DuckDB and MotherDuck, with sample configurations to materialize tables and views.
Conclusions
Integrating LLM-based data extraction into SQL workflows simplifies working with unstructured data in a data warehouse. With the prompt() function, free-form text can be transformed into structured outputs directly within your existing pipelines. This streamlines tasks like sentiment analysis and attribute extraction, enabling deeper insights from previously challenging data—all within the comfort of your SQL environment.
Share your feedback
Structured data generation with the prompt() function unlocks a great opportunity to analyze unstructured text data that otherwise would have been challenging. And, did you know that we also have an embedding() function to generate vector embeddings for text, enabling vector search in SQL? We’re happy to hear feedback, so please join our community slack channel to let us know what you think. Happy MotherDucking!
Start using MotherDuck now!

