Union and MotherDuck's Orchestrated Approach to Advanced Analytics
2024/10/18 - 13 min read
BYIntroduction
Flyte, a workflow orchestration ecosystem, has always been about simplifying the complexities of data processing and orchestration. The platform has continuously evolved to empower data teams with tools that offer both flexibility and power. With the introduction of the DuckDB plugin integrated with MotherDuck, Flyte takes another significant step forward.
DuckDB is an in-process database, meaning it runs within the same memory space as the application using it, increasing performance and simplicity. Naturally, when executing in-process queries on large data, memory and compute are top of mind. Flyte fits in here nicely, allowing users to easily handle scalability, concurrency and resource requirements of workloads using its DuckDB plugin. Taking this a step further, the plugin can extend DuckDB workflows to leverage MotherDuck's powerful data warehousing capabilities, all while maintaining the simplicity and flexibility that Flyte is known for. With the MotherDuck integration, you can run queries across both in-memory data and persistent data stored in MotherDuck, opening up a world of possibilities for data analysis and reporting. An added benefit of MotherDuck is that it natively handles DuckDB's single-file storage format, which supports ACID compliance, relieving users of the need to manage this locally as they would with DuckDB.
In this blog post, we'll walk through a practical example of how you can set up and utilize this integration. We'll cover everything from setting up your MotherDuck account and securely managing authentication tokens to writing and executing queries that span both local and remote data sources. By the end, you'll see how to build a Flyte workflow that not only automates your data pipelines but also provides visual insights into your data—all powered by Union, an orchestration platform extending the capabilities of Flyte. We’ll highlight some Union-specific features like the union CLI for secret management, Artifacts for maintaining data lineage, as well as the Union UI, which offers an enhanced experience for managing and visualizing your workflows.
Let’s first introduce the plugin, and then take a look at a larger example running hybrid execution DuckDB queries within Union workflows. In this blog post, we'll walk through a practical example of how you can set up and utilize this integration. We'll cover everything from setting up your MotherDuck account and securely managing authentication tokens to writing and executing queries that span both local and remote data sources. By the end, you'll see how to build a Flyte workflow that not only automates your data pipelines but also provides visual insights into your data—all powered by Union, an orchestration platform extending the capabilities of Flyte. We’ll highlight some Union-specific features like the union CLI for secret management, Artifacts for maintaining data lineage, as well as the Union UI, which offers an enhanced experience for managing and visualizing your workflows.
Let’s first introduce the plugin, and then take a look at a larger example running hybrid execution DuckDB queries within Union workflows.
The Plugin
The new Flyte DuckDB plugin with MotherDuck integration is designed to be intuitive and easy to use. Flyte’s existing DuckDB plugin provides a DuckDBQuery task type that can be called within a workflow. To allow for your DuckDB queries to now access MotherDuck, you just need to specify the MotherDuck DuckDBProvider to the DuckDBQuery and pass your MotherDuck authentication token as a Union secret. Let’s see how this can be done in three steps:
Step 1:
Sign up for a free Motherduck account and create an authentication token.
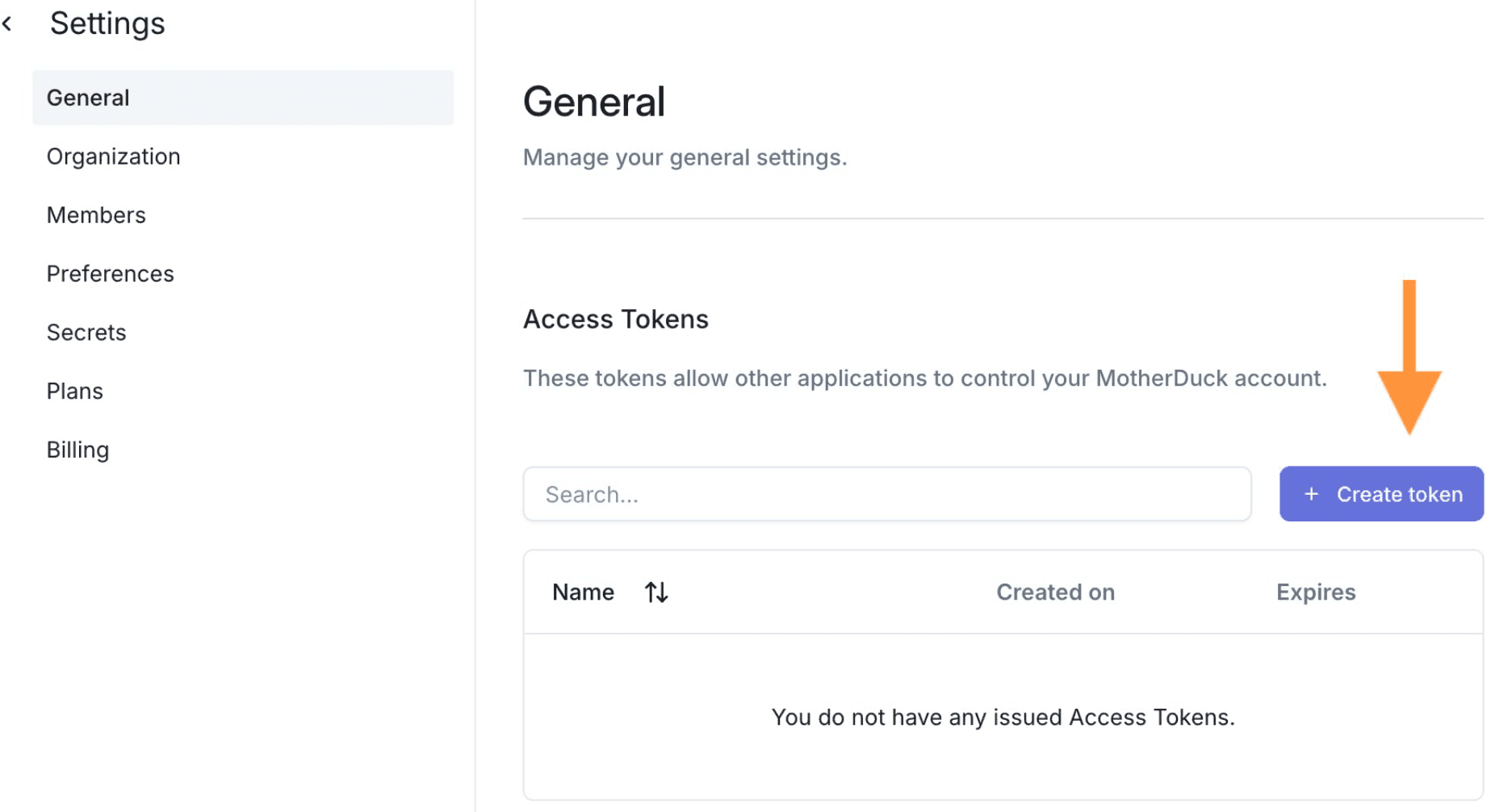
Step 2: Securely store your MotherDuck authentication token on Union as a secret using the union CLI tool:
Copy code
~ union create secret motherduck_token Enter secret value: ...
Step 3: Install the plugin and define your DuckDB query task for integration with MotherDuck:
Copy code
# motherduck_wf.py
my_query = DuckDBQuery(
name="my_query",
query="SELECT MEAN(trip_time) FROM sample_data.nyc.rideshare",
provider=DuckDBProvider.MOTHERDUCK,
secret_requests=[Secret(key="motherduck_token")],
)
@workflow
def wf() -> pd.DataFrame:
return my_query()
You can then run locally:
Copy code
~ pip install flytekitplugins-duckdb
~ union run motherduck_wf.py wf
Running Execution on local.
mean(trip_time)
0 1188.595344
Or remotely on a Union cluster:
Copy code
~ union run --remote motherduck_wf.py wf
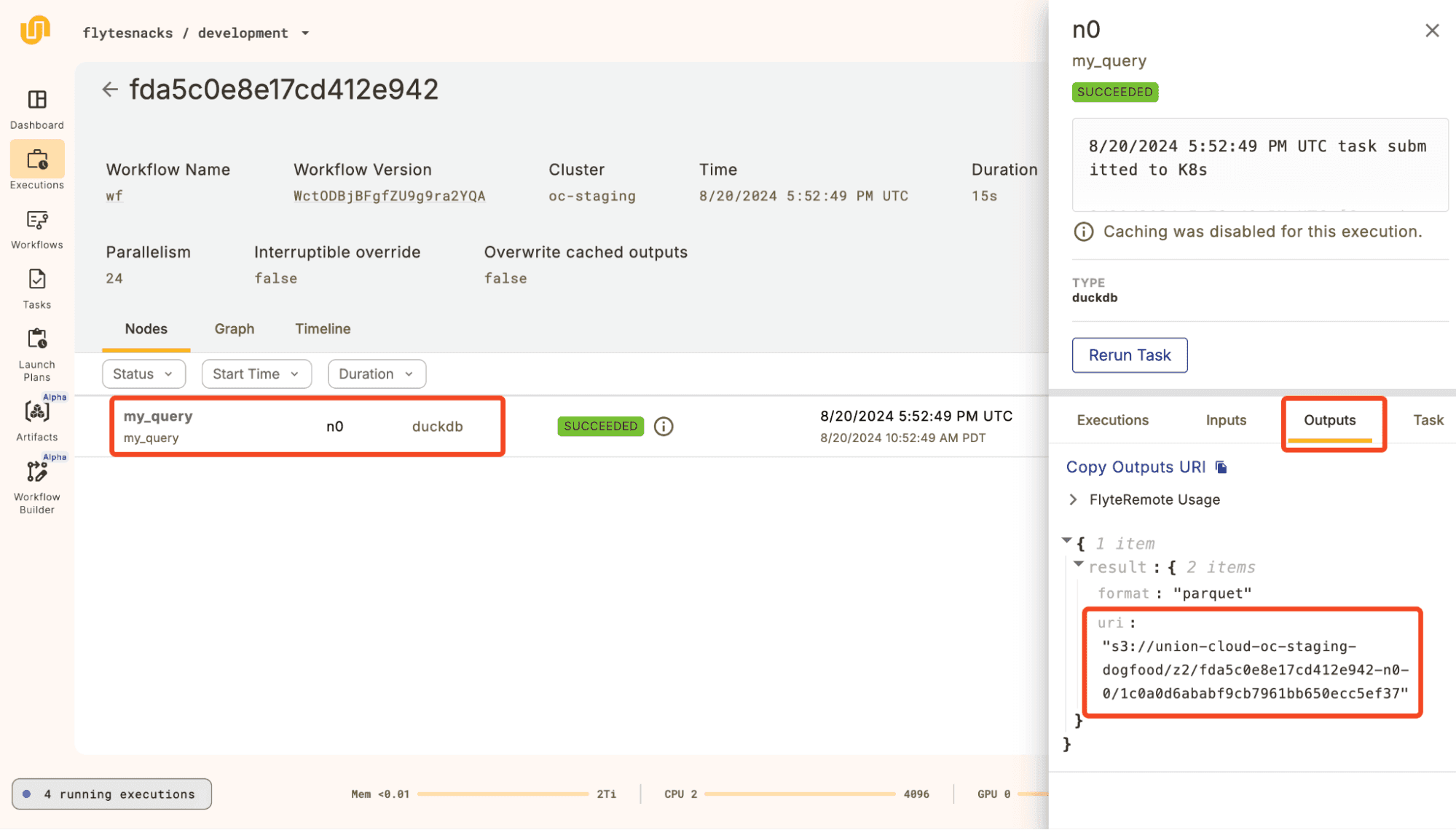
Copy code
~ python -c "
import pandas as pd;
df = pd.read_parquet('s3://union-cloud-oc-staging-dogfood/z2/fda5c0e8e17cd412e942-n0-0/1c0a0d6ababf9cb7961bb650ecc5ef37');
print(df.head())"
mean(trip_time)
0 1188.595344
Example: Ecommerce Summary and Natural Language to DuckDB Query Pipeline
The ability to work with both in-memory and persistent data within a single workflow has significant real-world implications. In-memory data offers speed and flexibility, making it ideal for processing real-time or recent data, such as ongoing transactions or daily updates. However, this data is ephemeral, meaning it disappears once the workflow ends. On the other hand, persistent data, stored in solutions like MotherDuck, is crucial for maintaining historical records, performing long-term trend analysis, and ensuring data consistency across workflows.
To demonstrate hybrid query execution as described above, we will use a Kaggle online retail dataset which contains two years of retail transaction data. The example will operate under the following scenario:
- We have a large set of historical transaction data that lives in MotherDuck. MotherDuck helps us persist the data so we can make DuckDB queries on non-in-process data. We will use the 2009-2010 data as our “historical” data.
- As time passes, we get new transaction data from an upstream process, say, every month or every week. This is in-memory data for which we would like to gather analytics in comparison to our historical data; we will call it “recent” data. For example, we might want to see which customer’s spending patterns in the recent data changed the most compared to the historical data.
Given the above scenario, let’s say we want to do the following:
- Run a workflow that creates a summary report of the most important trends we see when comparing the recent and historical data. We want this workflow to run whenever some upstream process generates new data.
- We can use the new DuckDB plugin to query our in-memory data and MotherDuck data at the same time.
- We can use Decks to visualize the results of our summary queries.
- We can use Artifacts and Launch Plans to have the workflow run automatically whenever new data is generated.
- Have the ability for a user to prompt the workflow with a natural language question regarding the contents of the historical data, recent data, or both. This can be a powerful feature if the summary report does not touch on an area of interest and the user does not wish to construct a DuckDB query.
- We can use function calling with the OpenAI python client to get GPT 4o to construct DuckDB queries and run these using the Flyte DuckDB plugin.
Let’s see how the DuckDB and MotherDuck integration can be used for this example.
To start, our project will be structured as follows:
Copy code
~ tree .
.
├── duckdb_artifacts.py <-- Here Union artifacts and triggers are defined
├── ecommerce_wf.py <-- Here is where we will put our main Union workflows
├── openai_tools.py <-- Here we define prompts and functions for openai function calling
├── plots.py <-- Here where we construct plots for the summary report
└── queries.py <-- Here is where we define the static DuckDB queries used for the report
As Flyte tasks run in containers on kubernetes pods, we can define our container dependencies using an ImageSpec rather than having to write a DickerFile:
Copy code
image = ImageSpec(
name="motherduck-image",
registry=os.environ.get("DOCKER_REGISTRY", None),
packages=["union==0.1.68", "pandas==2.2.2", "plotly==5.23.0", "pyarrow==16.1.0", "flytekitplugins-openai==1.13.8", "flytekitplugins-duckdb==1.13.8"],
)
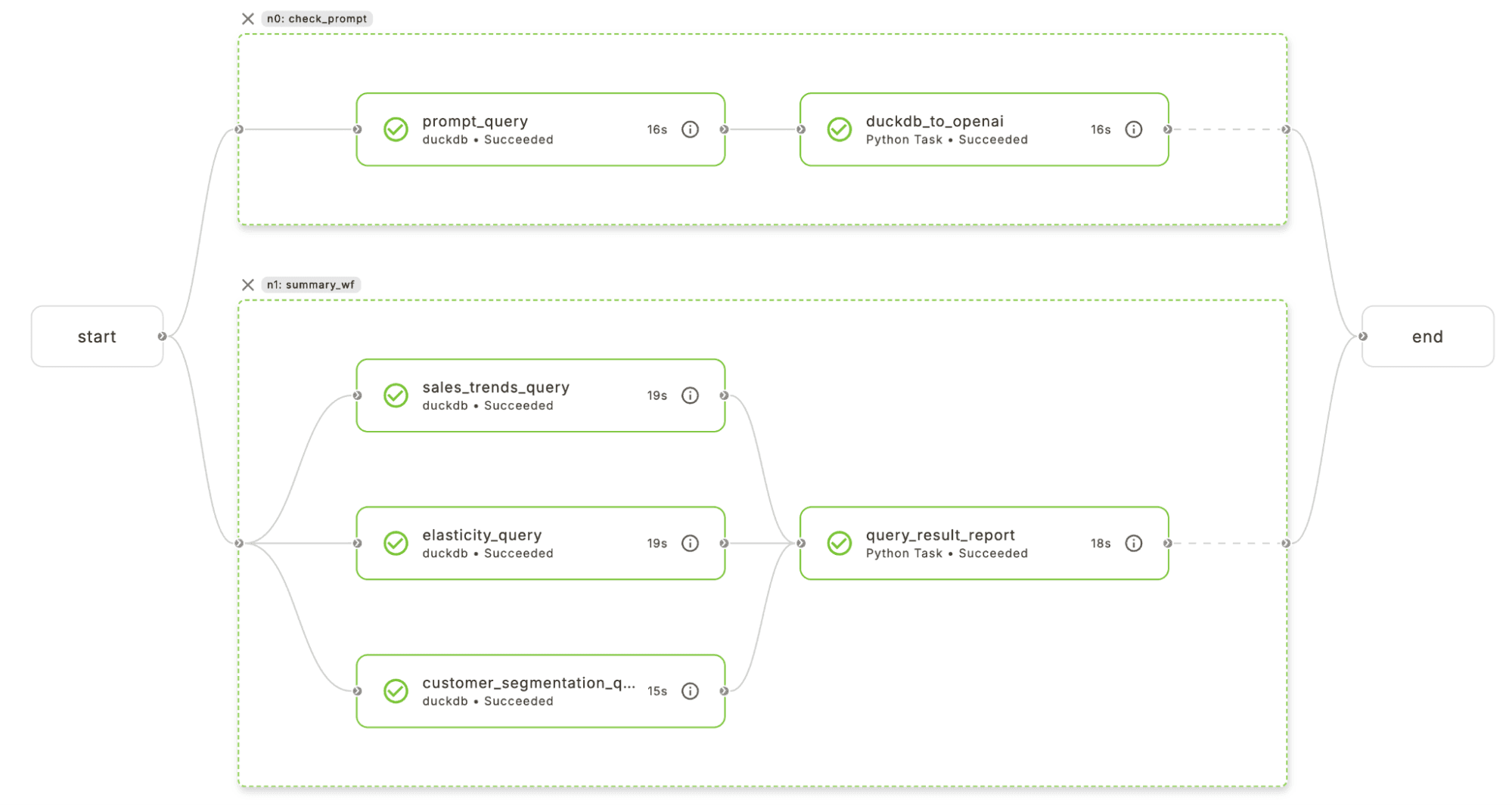
The workflow used to create the above figure is the user_prompt_wf defined in ecommerce_wf.py as follows:
Copy code
@workflow
def summary_wf(recent_data: pd.DataFrame = RecentEcommerceData.query()):
# Make plots
sales_trends_result = sales_trends_query_task(mydf=recent_data)
elasticity_result = elasticity_query_task(mydf=recent_data)
customer_segmentation_result = customer_segmentation_query_task(mydf=recent_data)
query_result_report(
sales_trends_result=sales_trends_result,
elasticity_result=elasticity_result,
customer_segmentation_result=customer_segmentation_result,
)
@workflow
def user_prompt_wf(prompt: str, recent_data: pd.DataFrame = RecentEcommerceData.query()) -> str:
# Answer prompt
answer, query = check_prompt(recent_data=recent_data, prompt=prompt)
# Make Summary
summary_wf(recent_data=recent_data)
return answer
We intentionally decouple the summarization and prompting components by calling summary_wf within user_prompt_wf—a pattern that will help with automatic triggering of summary_wf later on. Before we dig into the tasks of this workflow, let’s take note of the input. The first input recent_data is a pandas dataframe that has a default value of RecentEcommerceData.query(). RecentEcommerceData is a Union artifact defined in duckdb_artifacts.py which represents recent transaction data created by some upstream process. Artifacts let us decouple workflow, follow data lineage, and automatically trigger other workflows based on upstream output. The .query() method queries Union for the most recent instance of RecentEcommerceData. The second input prompt can be optionally added if the user runs this pipeline manually and wishes to make a query on the historical data and recent data using natural language. We will look at how this workflow is automatically triggered or manual run later.
Query Summary Report
Let’s now take a look at the tasks that generate our summary report. sales_trends_query_task, elasticity_query_task, and customer_segmentation_query_task are all DuckDBQuery tasks which run different queries in parallel and are defined in queries.py. Let’s look at sales_trends_query_task as an example.
Copy code
from queries import sales_trends_query
sales_trends_query_task = DuckDBQuery(
name="sales_trends_query",
query=sales_trends_query,
inputs=kwtypes(mydf=pd.DataFrame),
provider=DuckDBProvider.MOTHERDUCK,
secret_requests=[Secret(key="motherduck_token")],
)
We can see that sales_trends_query_task will have an input argument called mydf which is a pandas dataframe that we can query at the same time as our remote data in MotherDuck in a table called e_commerce.year_09_10 (you can see how to add data to MotherDuck here). Let’s look at the actual query below which compares the average quantity of products sold:
Copy code
sales_trends_query = """
WITH HistoricalData AS (
SELECT
StockCode,
Description,
AVG(Quantity) AS Avg_Quantity_Historical
FROM
e_commerce.year_09_10
WHERE
Quantity > 0 AND Description IS NOT NULL
GROUP BY
StockCode, Description
),
RecentData AS (
SELECT
StockCode,
AVG(Quantity) AS Avg_Quantity_Recent
FROM
mydf
WHERE
Quantity > 0 AND Description IS NOT NULL
GROUP BY
StockCode
)
SELECT
HistoricalData.StockCode,
HistoricalData.Description,
HistoricalData.Avg_Quantity_Historical,
RecentData.Avg_Quantity_Recent
FROM
HistoricalData
LEFT JOIN
RecentData
ON
HistoricalData.StockCode = RecentData.StockCode
WHERE
RecentData.Avg_Quantity_Recent IS NOT NULL
ORDER BY
(RecentData.Avg_Quantity_Recent - HistoricalData.Avg_Quantity_Historical) DESC
"""
After we call our three DuckDBQuery tasks, we have three dataframes called sales_trends_result, elasticity_result, and customer_segmentation_result which we can feed into our plotting task called query_result_report which has Flyte Decks enabled. When a Deck is enabled for a task, a “Flyte Deck” button appears in the UI which, by default, produces visuals for an execution timeline, source code, downloadable dependencies, and task inputs and outputs including rendered dataframes if applicable. We can attach additional interactive plots showing visual summaries of the DuckDB query results we produced (see GitHub for the task and plotting code).
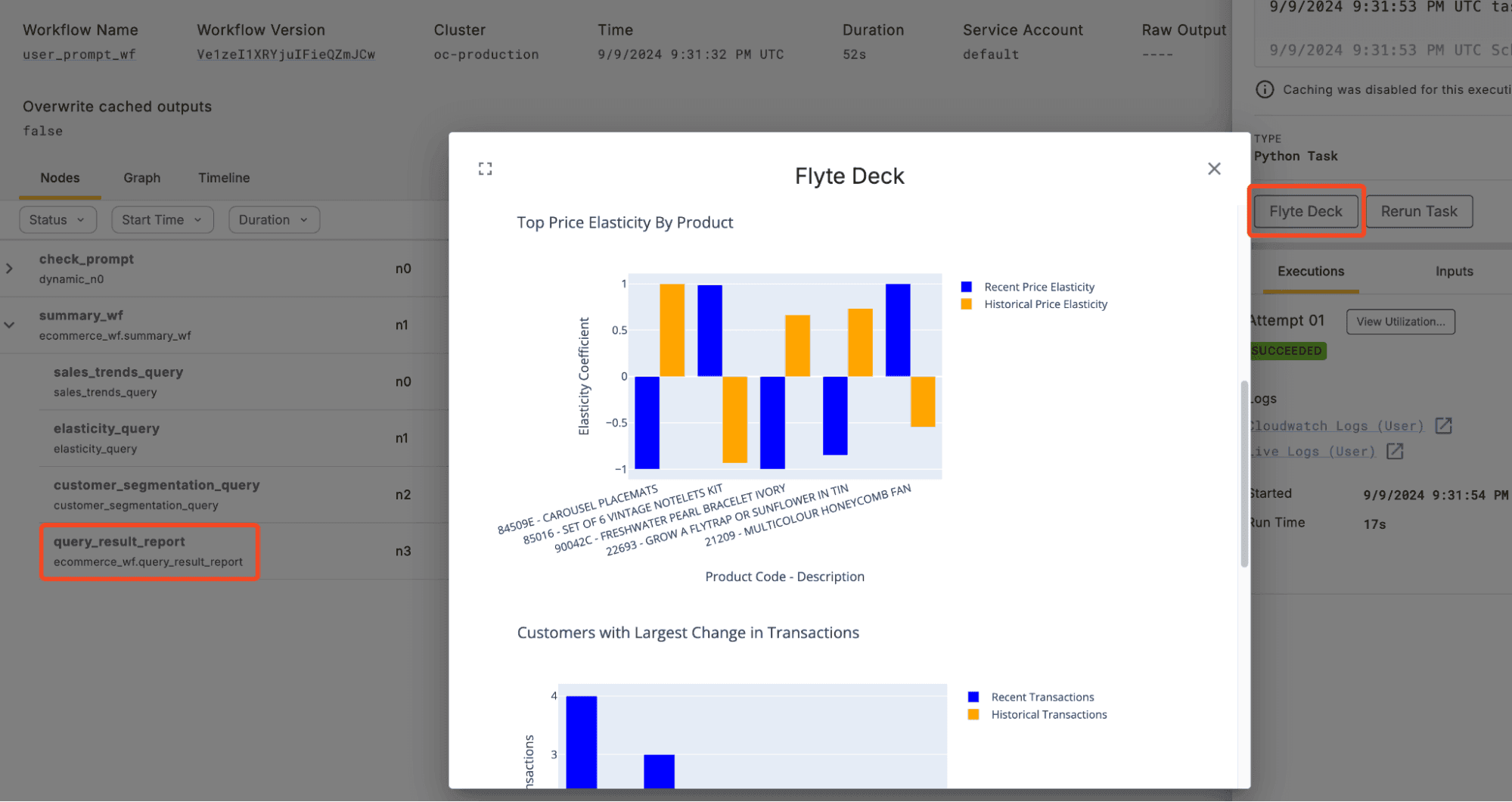
Natural Language to DuckDB
Now, let’s take a look at the part of the workflow which optionally takes a user prompt in natural language and queries our local dataframe and MotherDuck to find the answer. We will first note the use of the @dynamic decorator rather than the conventional @task decorator. A typical Flyte DAG is constructed at compile time, however, since the presence and content of prompt influences if we call subsequent tasks and therefore the structure of the DAG, we use @dynamic as it lets us compile the DAG at runtime. We will also add retries to this task as the non-determinism of GPT 4o may result in responses that are malformed and cause errors. Finally let’s note the inclusion of the motherduck_token and openai_token that are used to authenticate with the DuckDB and OpenAI clients (openai_token is set up similar to motherduck_token using secrets).
Copy code
@dynamic(container_image=image, retries=3,secret_requests=[Secret(key="motherduck_token"), Secret(key="openai_token")])
def check_prompt(recent_data: pd.DataFrame, prompt: str) -> Tuple[str, str]:
# set up secrets clients
...
# pass prompt to openai to select a tool
messages = [{
"role": "user",
"content": f"{prompt}"
}]
tools = get_tools(con=con)
response = openai_client.chat.completions.create(
model=GPT_MODEL,
messages=messages,
tools=tools,
tool_choice="auto"
)
response_message = response.choices[0].message
tool_calls = response_message.tool_calls
# if openai selected duckdb tool, pass query to duckdb and format response
if tool_calls:
tool_call_id = tool_calls[0].id
tool_function_name = tool_calls[0].function.name
tool_query_string = json.loads(tool_calls[0].function.arguments)['query']
if tool_function_name == DUCKDB_FUNCTION_NAME:
results = prompt_query_task(query=tool_query_string, mydf=recent_data)
messages.append(response_message)
content = duckdb_to_openai(messages=messages, results=results, tool_call_id=tool_call_id,tool_function_name=tool_function_name)
return content, tool_query_string
else:
raise FlyteRecoverableException(f"Error: function {tool_function_name} does not exist")
else:
return response_message.content, "No query."
In the above code snippet, we request a DuckDB query from OpenAI. If GPT 4o deems the prompt relevant, we use the response to query our recent_data and MotherDuck table using prompt_query_task, followed by a final OpenAI request (in duckdb_to_openai) to format the natural language response given the DuckDB query result and the original user prompt. If GPT 4o instead deems the prompt to not be relevant to our datasets of interest, we skip the DuckDB query altogether. Let’s take a moment to look at how prompt_query_task differs from the other DuckDBQuery tasks we looked at so far. prompt_query_task is defined as follows:
Copy code
prompt_query_task = DuckDBQuery(
name="prompt_query",
inputs=kwtypes(query=str, mydf=pd.DataFrame),
provider=DuckDBProvider.MOTHERDUCK,
secret_requests=[Secret(group=None, key="motherduck_token")],
)
Note the inclusion of query in the inputs which allows us to provide the query when we call prompt_query_task rather than when we define it as we did for the previous DuckDBQuery tasks.
To see further implementation details including GPT 4o prompting and using DuckDB to extract the table schema from MotherDuck, see GitHub. Now let’s take a look at this workflow in action. Let’s kick off the workflow with a user prompt using the union CLI too (recall that this will use the most recent RecentEcommerceData artifact when running queries):
Copy code
~ union run --remote ecommerce_wf.py user_prompt_wf --prompt="How many customers are there in the historical data compared to the recent data?"
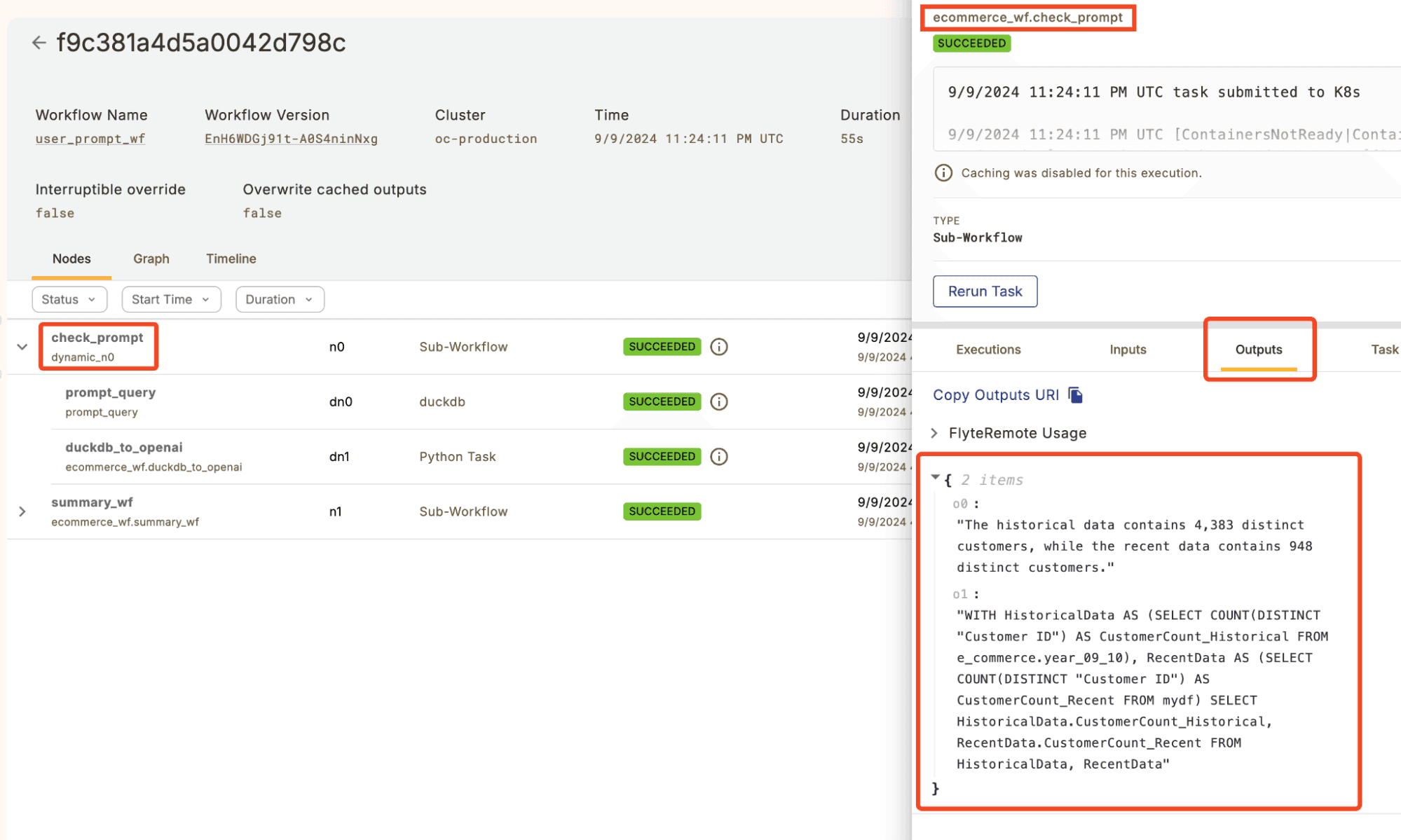
Looking at the Union UI, we see the two outputs of check_prompt, the natural language output, and the query used to find the answer.
Note that Flyte conveniently abstracts the dataflow between workflow tasks. For example, as the DuckDB query runs in a separate container from the OpenAI request, the query response dataframe that both use needs to be offloaded to blob storage and passed between. Leveraging Flytes data lineage, we can easily extract and inspect any intermediary data we are interested in. For example, let’s look at the query result of the prompt_query task (we can find the S3 URI we need in the Union UI).
Copy code
~ python -c "
import pandas as pd;
df = pd.read_parquet('s3://union-oc-production-demo/su/f9c381a4d5a0042d798c-n0-0-dn0-0/8551d2d3af6466fc0d79668aeec29440');
print(df.head())"
Customer_Count_Historical Customer_Count_Recent
0 4383 948
Finally, let’s look at the UI to get an idea of runtime for our various tasks.
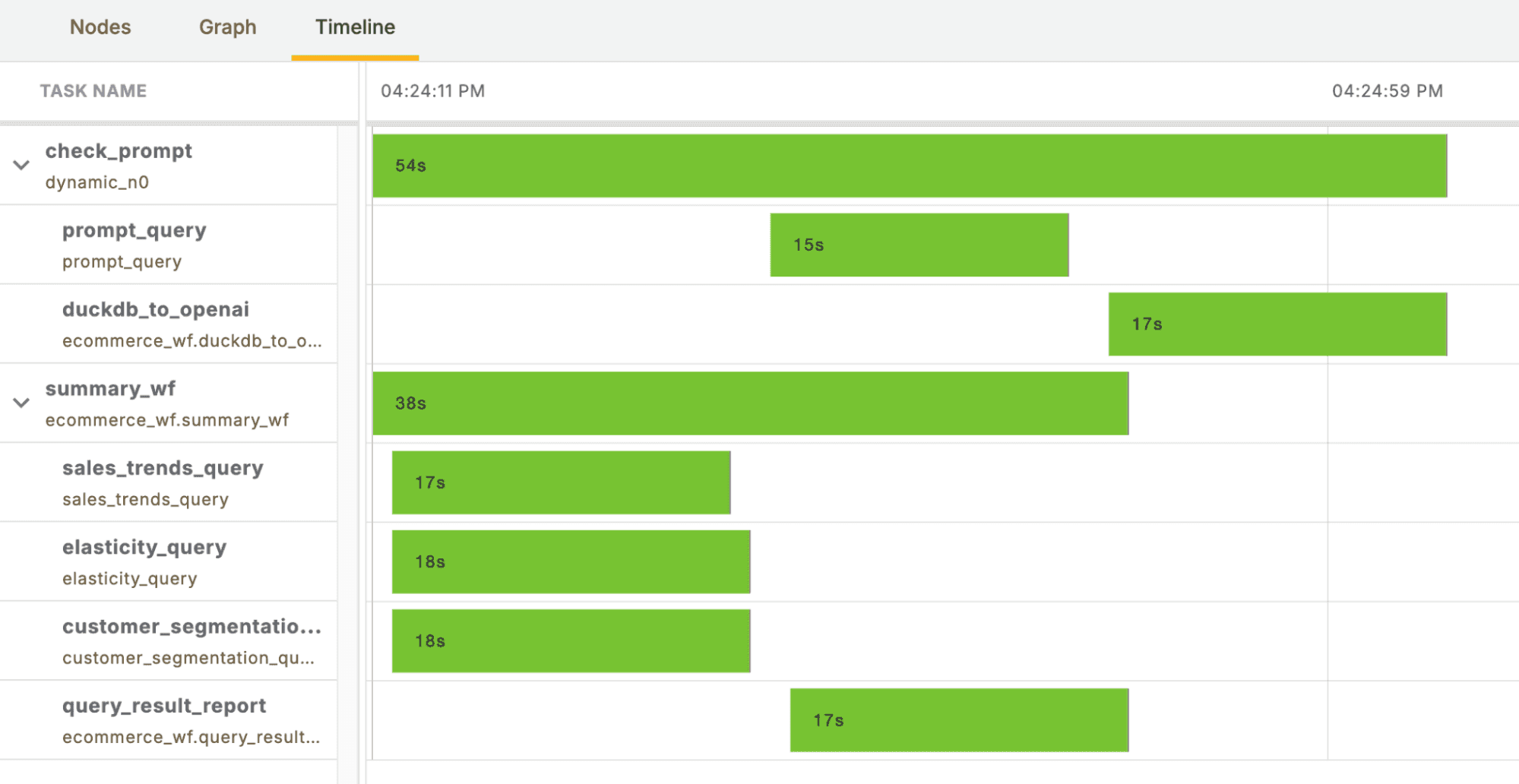
The efficiency of DuckDB and MotherDuck to run analytical queries is clearly leveraged, especially considering the hybrid execution of the queries and the overhead of starting kubernetes pods in Flyte. We should also note the parallel nature of Flyte tasks given that our query summary Flyte Deck was created at the same time as our natural language to DuckDB job. This is only scratching the surface of parallelization in Flyte; see map tasks for more.
We will cap off this example by defining a Launch Plan which will trigger our summery_wf automatically upon the creation of a RecentEcommerceData artifact from an upstream workflow and send us a notification to our email or Slack when the workflow has completed.
Copy code
downstream_triggered = LaunchPlan.create(
"summary_lp",
summary_wf,
trigger=OnArtifact(
trigger_on=RecentEcommerceData,
),
notifications=[
Email(
phases=[WorkflowExecutionPhase.FAILED, WorkflowExecutionPhase.SUCCEEDED],
recipients_email=["<some-email>"],
)
]
)
This can be registered using the union CLI:
Copy code
~ union register ecommerce_wf.py
~ union launchplan --activate summary_lp
Try It Yourself
The integration of Flyte's DuckDB plugin with MotherDuck offers a practical and powerful solution for handling hybrid data processing workflows. You can find the code for this example on github and more information on the DuckDB plugin in the Flyte documentation. Please don’t hesitate to reach out to the Union team, or or try Union Serverless out for free.
Start using MotherDuck now!