
2025/05/08 - Simon Späti
DuckDB Ecosystem: May 2025
DuckDB news: Metabase driver queries Parquet files directly. FlockMTL integrates LLMs into SQL workflows. Doom clone runs in DuckDB-WASM. Spatial wins top honors.
- 12 min read
BY- 12 min read
BYIt's 2:30 AM. The office is empty. Your coffee's gone cold, and you're staring blankly at your screen as it mockingly displays: Error: Could not convert string 'N/A' to INTEGER on line 56,789. All you wanted was to import a "simple" CSV export from that upstream system. Sound familiar?
We've all been in CSV purgatory. That moment when what should be a five-minute task turns into a multi-hour ordeal because somewhere, buried deep in that innocent-looking file, lurks an inconsistent delimiter, a rogue quote, or my personal favorite—columns that mysteriously appear and disappear like fish fry diving underwater to avoid being eaten by our duck friends.
I've spent countless hours wrestling with problematic CSVs, but after discovering some of DuckDB's lesser-known features, those late-night CSV battles have become far less common. While DuckDB's automatic CSV reader is already impressively smart, knowing a few advanced techniques can save you from writing custom preprocessing scripts when things get messy.
In this guide, I'll share the DuckDB techniques that have repeatedly saved me from CSV hell:
Let's dive in and see if we can make your next CSV import session a little less...quackers.
Before attempting to load the data using DuckDB’s auto-detection capabilities, it's incredibly useful to understand what DuckDB thinks it's dealing with. Is it guessing the delimiter correctly? Did it detect the header? What types is it inferring? The sniff_csv() function is your reconnaissance tool here.
Instead of blindly running read_csv and potentially hitting errors, run sniff_csv first. It analyzes a sample of the file and reports back the detected dialect, types, header presence, and more.
Let’s imagine a file events.csv:
Copy code
EventDate|Organizer|City|Venue 2022-03-01|OpenTech|San Francisco, CA|Moscone Center, Hall A 2022-03-02|OpenTech|San Francisco, CA|Moscone Center, Hall B 2022-03-03|OpenTech|San Francisco, CA|Moscone Center, Hall C
Let's see what DuckDB makes of this:
Copy code
FROM sniff_csv('events.csv');
Copy code
FROM sniff_csv('http://duckdb-example-files.s3-website-us-east-1.amazonaws.com/2025-blog-post-taming-wild-csvs/events.csv');
You can also control how much of the file it samples:
Copy code
FROM sniff_csv('events.csv', sample_size=10000); -- Sample 10k rows
Or sample the whole file (careful with huge files!):
Copy code
FROM sniff_csv('events.csv', sample_size=-1);
The output provides a wealth of information in a single row table:
Delimiter, Quote, Escape, NewLineDelimiter: The detected structural characters.SkipRows: Number of rows it thinks should be skipped at the start.HasHeader: Boolean flag if a header is detected.Columns: A list of structs showing detected column names and types (e.g., {'name': 'VARCHAR', 'age': 'BIGINT'}).DateFormat, TimestampFormat: Any special date/time formats it detected.Prompt: This is extremely useful! It gives you a read_csv command with all the detected options explicitly set. You can copy, paste, and modify this as needed.Running sniff_csv first can save you significant guesswork when an import fails. If the detected Delimiter is wrong, or it thinks HasHeader is true when it isn't, you know exactly which options to override in your read_csv call.
DuckDB's CSV sniffer actually operates through multiple phases to determine the best way to read your file:
Dialect Detection: At the time of writing, sniffer tests 24 different combinations of dialect configurations (delimiters, quotes, escapes, newlines) to see which one creates the most consistent number of columns across rows.
Type Detection: After determining the dialect, the sniffer analyzes the first chunk of data (2048 rows by default) to detect column types, trying to cast values from most to least specific types (SQLNULL → BOOLEAN → BIGINT → DOUBLE → TIME → DATE → TIMESTAMP → VARCHAR).
Header Detection: The sniffer checks if the first valid line can be cast to the detected column types. If it can't, that line is considered a header.
Type Replacement: If you specified column types, they override the sniffer's detected types.
Type Refinement: The sniffer validates the detected types on more data using vectorized casting.
Here's a code example showing how to inspect what the sniffer sees in a more complex scenario:
Copy code
-- Examine what the sniffer detects with a larger sample size
SELECT
Delimiter, Quote, Escape, SkipRows, HasHeader, DateFormat, TimestampFormat
FROM sniff_csv('events.csv', sample_size=50000);
-- To see the detected column types
SELECT unnest(Columns)
FROM sniff_csv('events.csv');
When I was working with a dataset containing 20+ columns of mixed types, the unnest(Columns) trick was particularly helpful to see exactly which columns were being detected as which types, saving a ton of back-and-forth troubleshooting.
So sniff_csv looks good, but your file still has issues—maybe just a few problematic rows scattered throughout millions of good ones. By default, DuckDB will halt the import on the first error. But often, you just want the valid data and to deal with the bad rows separately.
ignore_errors)The simplest approach is to tell DuckDB to skip rows that cause parsing or casting errors using ignore_errors = true.
Let's imagine a file faulty_folks.csv:
Copy code
Name,Age Alice,30 Bob,forty-two Charlie,35
Trying to read this normally with explicit types will fail on Bob's age:
Copy code
-- This will error out!
SELECT * FROM read_csv('faulty_folks.csv', header=true, columns={'Name':'VARCHAR', 'Age':'INTEGER'});
But if we just want Alice and Charlie:
Copy code
SELECT * FROM read_csv('faulty_folks.csv',
header = true,
-- Specify expected types
columns = {'Name': 'VARCHAR', 'Age': 'INTEGER'},
ignore_errors = true -- The key part!
);
Explanation:
columns we expect, including the INTEGER type for Age.ignore_errors = true tells the reader: if you hit a row where 'Age' can't become an INTEGER (like "forty-two"), just drop that row and keep going.Output:
| Name | Age |
|---|---|
| Alice | 30 |
| Charlie | 35 |
Bob gets left behind, but the import succeeds with the valid rows. This approach skips rows with various issues: casting errors, wrong number of columns, unescaped quotes, etc.
Ignoring errors is okay, but generally, you need to know what went wrong and which rows were rejected. Maybe you need to fix the source data or report the issues. This is where store_rejects = true becomes invaluable.
When you use store_rejects, DuckDB still skips the bad rows (like ignore_errors), but it also logs detailed information about each rejected row and the error encountered into two temporary tables: reject_scans and reject_errors.
Copy code
-- Read the file, storing rejected rows
SELECT * FROM read_csv(
'faulty_folks.csv',
header = true,
columns = {'Name': 'VARCHAR', 'Age': 'INTEGER'},
store_rejects = true -- Store info about errors
-- Optional: Customize table names and limit
-- rejects_scan = 'my_scan_info',
-- rejects_table = 'my_rejected_rows',
-- rejects_limit = 100 -- Store max 100 errors per file
);
-- Now, let's see what was rejected
FROM reject_errors;
-- And details about the scan itself
FROM reject_scans;
Explanation:
read_csv call runs, skips Bob's row, and returns Alice and Charlie just like before.store_rejects = true populates the temporary tables.FROM reject_errors; shows details about the failed rows:
scan_id, file_id: Link back to the specific scan/file.line: The original line number in the CSV.column_idx, column_name: Which column had the issue (if applicable).error_type: The category of error (e.g., CAST, TOO_MANY_COLUMNS).csv_line: The actual content of the rejected line.error_message: The specific error message DuckDB generated.FROM reject_scans; gives metadata about the read_csv operation itself (delimiter, quote rule, schema used, file path, etc.).I've found this incredibly useful for debugging dirty data. You get the clean data loaded and a detailed report on the rejects, all within DuckDB. No more grep-ing through massive files trying to find that one problematic line!
Sometimes, you just want to get the data in, even if it’s a little messy. That’s where DuckDB's more forgiving CSV parsing options can help you out. strict_mode = false option tells DuckDB to loosen up its parsing expectations. It will try to read rows even if they contain typical formatting problems like:
"15" Laptop").\n and \r\n).When you set strict_mode=false, you’re trusting DuckDB to make its best guess. That works great when you want results fast—but double-check the output if data precision matters!
Another commonly used option is null_padding = true, which handles rows that come up short, meaning they have fewer columns than expected. Instead of throwing an error, DuckDB just fills in the blanks with NULL.
Let’s look at an example. Here's a messy CSV file named inventory.csv:
Copy code
ItemID,Description,Price 101,"15" Laptop",999.99 102,"Wireless Mouse" 103,"Mechanical Keyboard",129.99,ExtraField
This file includes:
Try reading it normally:
Copy code
FROM read_csv('inventory.csv');
DuckDB will skip all lines except the last.
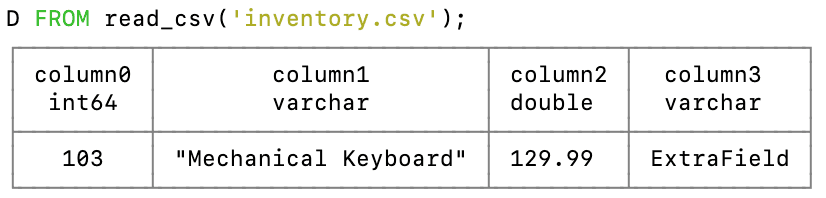
But with relaxed settings:
Copy code
-- Parsing a messy CSV while gracefully handling missing and extra fields
FROM read_csv('inventory.csv',
strict_mode = false, -- Forgive formatting quirks
null_padding = true -- Fill missing columns with NULLs
);
Resulting Table:
| ItemID | Description | Price | column3 |
|---|---|---|---|
| 101 | 15 Laptop | 999.99 | NULL |
| 102 | Wireless Mouse | NULL | NULL |
| 103 | Mechanical Keyboard | 129.99 | ExtraField |
Here's another common headache: you have multiple CSV files to load (e.g., monthly reports), but the columns aren't quite the same across files. Maybe a column was added in March, or the order changed in June. Trying to read them together with a simple read_csv('monthly_report_*.csv') might fail or produce misaligned data.
DuckDB's union_by_name = true option handles this elegantly. When reading multiple files (using globs or lists), it aligns columns based on their header names rather than their position. If a file is missing a column found in other files, it fills it with NULL.
Imagine report_jan.csv:
Copy code
UserID,MetricA,MetricB 1,10,100 2,15,110
And report_feb.csv:
Copy code
UserID,MetricB,MetricC,MetricA 3,120,xyz,20 4,125,abc,25
Notice the different order and the new MetricC in February.
Copy code
SELECT *
FROM read_csv(
['report_jan.csv', 'report_feb.csv'], -- List of files (or glob)
union_by_name = true -- The magic!
);
Explanation:
UserID, MetricA, MetricB, MetricC).MetricC in report_jan.csv), it inserts NULL.Output:
| UserID | MetricA | MetricB | MetricC |
|---|---|---|---|
| 1 | 10 | 100 | NULL |
| 2 | 15 | 110 | NULL |
| 3 | 20 | 120 | xyz |
| 4 | 25 | 125 | Abc |
While auto-detection is great, sometimes you know better, or the sample DuckDB takes isn't quite representative. Here are some ways to fine-tune the process:
Bigger Sample: If type detection seems off (e.g., a column that's mostly integers but has a few floats later gets detected as BIGINT), try increasing the sample size:
Copy code
SELECT * FROM read_csv('file.csv', sample_size = 50000);
-- Or scan the whole file (can be slow for huge files)
SELECT * FROM read_csv('file.csv', sample_size = -1);
Manual Types: Override specific column types if detection gets it wrong or if you want a different type:
Copy code
-- Override by name
SELECT * FROM read_csv('file.csv',
types = {'UserID': 'VARCHAR', 'TransactionAmount': 'DOUBLE'});
-- Or by position if no headers
SELECT * FROM read_csv('file.csv', header = false,
types = ['VARCHAR', 'DOUBLE', 'DATE']);
Force Header/No Header: If header detection fails (common if all columns look like strings):
Copy code
-- Force header presence
SELECT * FROM read_csv('file.csv', header = true);
-- Or no header with custom names
SELECT * FROM read_csv('file.csv',
header = false,
names = ['colA', 'colB', 'colC']);
Date/Timestamp Formats: If dates aren't ISO 8601 (YYYY-MM-DD) or times aren't standard:
Copy code
SELECT * FROM read_csv('file.csv',
dateformat = '%m/%d/%Y',
timestampformat = '%Y-%m-%dT%H:%M:%S.%f');
Everything is a String: If you want to load everything as VARCHAR and deal with types later:
Copy code
SELECT * FROM read_csv('file.csv', all_varchar = true);
Which Columns Can Be NULL?: By default, an empty field is treated as NULL. If empty strings should be valid values:
Copy code
SELECT * FROM read_csv('file.csv',
force_not_null = ['column_name1', 'column_name2']);
Clean Up Names: Got headers with spaces or weird characters?
Copy code
SELECT * FROM read_csv('file.csv', normalize_names = true);
This will automatically clean them up (replacing non-alphanumeric with _, etc.) during import.
For those really interested in CSV robustness, there's an intriguing benchmark called Pollock that evaluates how well different systems handle non-standard CSV files. The creators studied over 245,000 public CSV datasets to identify common violations of the RFC-4180 standard, then created test files with these issues.
In recent testing, DuckDB ranked #1 in the benchmark when configured to handle problematic files, correctly reading 99.61% of the data across all test files. Even in auto-detect mode with minimal configuration, DuckDB still managed to read about 90.75% of the data correctly.
This is practical validation that the approaches we've covered in this article can handle the vast majority of real-world CSV issues you'll encounter.
| System under test | Pollock score (simple) | Pollock score (weighted) |
|---|---|---|
| DuckDB 1.2 | 9.961 | 9.599 |
| SQLite 3.39.0 | 9.955 | 9.375 |
| UniVocity 2.9.1 | 9.939 | 7.936 |
| LibreOffice Calc 7.3.6 | 9.925 | 7.833 |
| SpreadDesktop | 9.929 | 9.597 |
| SpreadWeb | 9.721 | 9.431 |
| Python native csv 3.10.5 | 9.721 | 9.436 |
| Pandas 1.4.3 | 9.895 | 9.431 |
| MySQL 8.0.31 | 9.587 | 7.484 |
| Mariadb 10.9.3 | 9.585 | 7.483 |
We've covered quite a bit in our journey through DuckDB's CSV capabilities—from diagnosing issues with sniff_csv to handling errors with ignore_errors and store_rejects, merging inconsistent schemas with union_by_name, and fine-tuning the whole process with various overrides.
What I've come to appreciate about DuckDB is that its CSV reader isn't just a basic loader—it's a sophisticated tool designed to handle real-world data messiness directly within SQL. Most data tools can handle the perfect CSV file, but it's how they deal with the imperfect ones that really matters in day-to-day work.
By understanding these slightly more advanced options, you can often avoid external preprocessing steps, keeping your data loading logic right within your SQL workflow. The result is cleaner pipelines that are less likely to waddle when faced with unexpected CSV quirks.
The next time a tricky CSV lands on your desk, remember these techniques. They might just save you some time and frustration, letting you get back to the more interesting parts of data analysis sooner. Happy querying!
2025/05/08 - Simon Späti
DuckDB news: Metabase driver queries Parquet files directly. FlockMTL integrates LLMs into SQL workflows. Doom clone runs in DuckDB-WASM. Spatial wins top honors.

2025/05/12 - Mehdi Ouazza
Walkthrough of the new DuckDB UI features!