In the quest to handle their Big Data problems, software and hardware architects have been pursuing divergent strategies for the last 20 years. While software folks have been busy re-writing their code to scale out to multiple machines, hardware folks have been cramming more and more transistors and cores into a single chip so you can do more work on each machine.
As anyone who has had a programming interview can attest, if you have a linear progression and an exponential progression the exponential will dominate. Scale-out lets you scale linearly with cost. But Moore’s Law compounds exponentially with time, meaning if you do nothing for a few years you can scale up and get orders of magnitude improvements. In two decades, transistor density has increased by 1000x; something that might have taken thousands of machines in 2002 could be done today in just one.
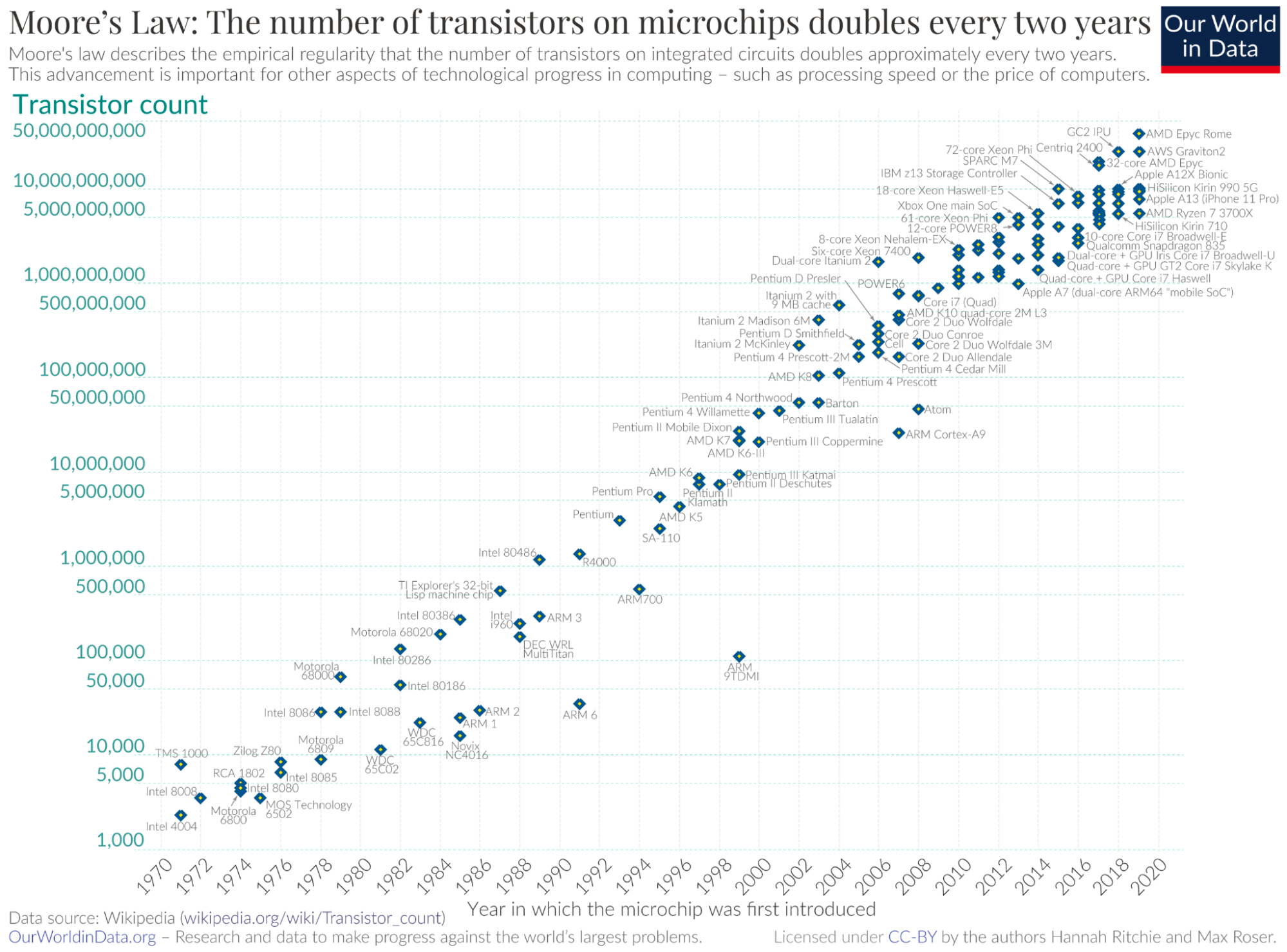 Image by Our World In Data, https://ourworldindata.org/moores-law
Image by Our World In Data, https://ourworldindata.org/moores-law
After such a dramatic increase in hardware capability, we should ask ourselves, “Do the conditions that drove our scaling challenges in 2003 still exist?” After all, we’ve made our systems far more complex and added a lot of overhead. Is it all still necessary? If you can do the job on a single machine, isn’t that going to be a better alternative?
This post will dig into why scale-out became so dominant, take a look at whether those rationales still hold, and then explore some advantages of scale-up architecture.
Why did we scale out in the first place?
First, a little bit of context. Twenty years ago, Google was running into scaling problems as they were trying to crawl and index the entire web. The typical way of dealing with this would have been to buy pricier machines. Unfortunately, they didn’t have a lot of money at the time and, regardless of cost, they were still going to hit limits as “web-scale” went through its own exponential growth progression.
In order to be able to index every website everywhere, Google invented a new model for computation; by applying functional programming and distributed systems algorithms, they achieved almost infinite scale without requiring the purchase of “big iron” hardware. Instead of bigger computers, they could just tie together a lot of small computers with clever software. This was “scaling out” to more machines instead of “scaling up” to bigger ones.
Google published a series of three papers in rapid succession that changed the way people build and scale software systems. These papers were GFS (2003) which tackled storage, MapReduce (2004) which handled computation, and BigTable (2006) which had the rudiments of a database.
Doug Cutting, who implemented the techniques in these papers and released them as open source, said, “Google is living a few years in the future and sending the rest of us messages.” (Unfortunately, Google didn’t get very far in the time travel business, having devoted much of their development efforts to their bug-ridden Goat Teleporter.)
Reading the MapReduce paper for the first time, I felt like Google had created a whole new way of thinking. I joined Google in 2008, hoping to be a part of that magic. Shortly thereafter, I started working on productizing their scale-out query engine Dremel, which became BigQuery.
It is difficult to overstate the impact of the architectural change heralded by the scale-out revolution. If you’re building “serious” infrastructure, these days, you have to scale out via a complex distributed system. This has led to popularization of new techniques for consensus protocols, new ways of deploying software, and more comfort with relaxed consistency. Scale up was limited to legacy code bases that clung to their single-node architectures.
My workload couldn’t possibly fit on one machine [❌]
The first and primary rationale for scaling out is that people believe they need multiple machines to handle their data. In a long post, I argued that “Big Data is Dead,” or, specifically, that data sizes tend to be smaller than people think, that workloads tend to be smaller still, and that a lot of data never gets used. If you don’t have “Big Data,” then you almost certainly don’t need scale-out architectures. I won’t rehash those same arguments here.
I can start with a simple chart, which shows how much bigger AWS instances have gotten over time. Widely-available machines now have 128 cores and a terabyte of RAM. That’s the same amount of cores as a Snowflake XL instance, with four times the memory.
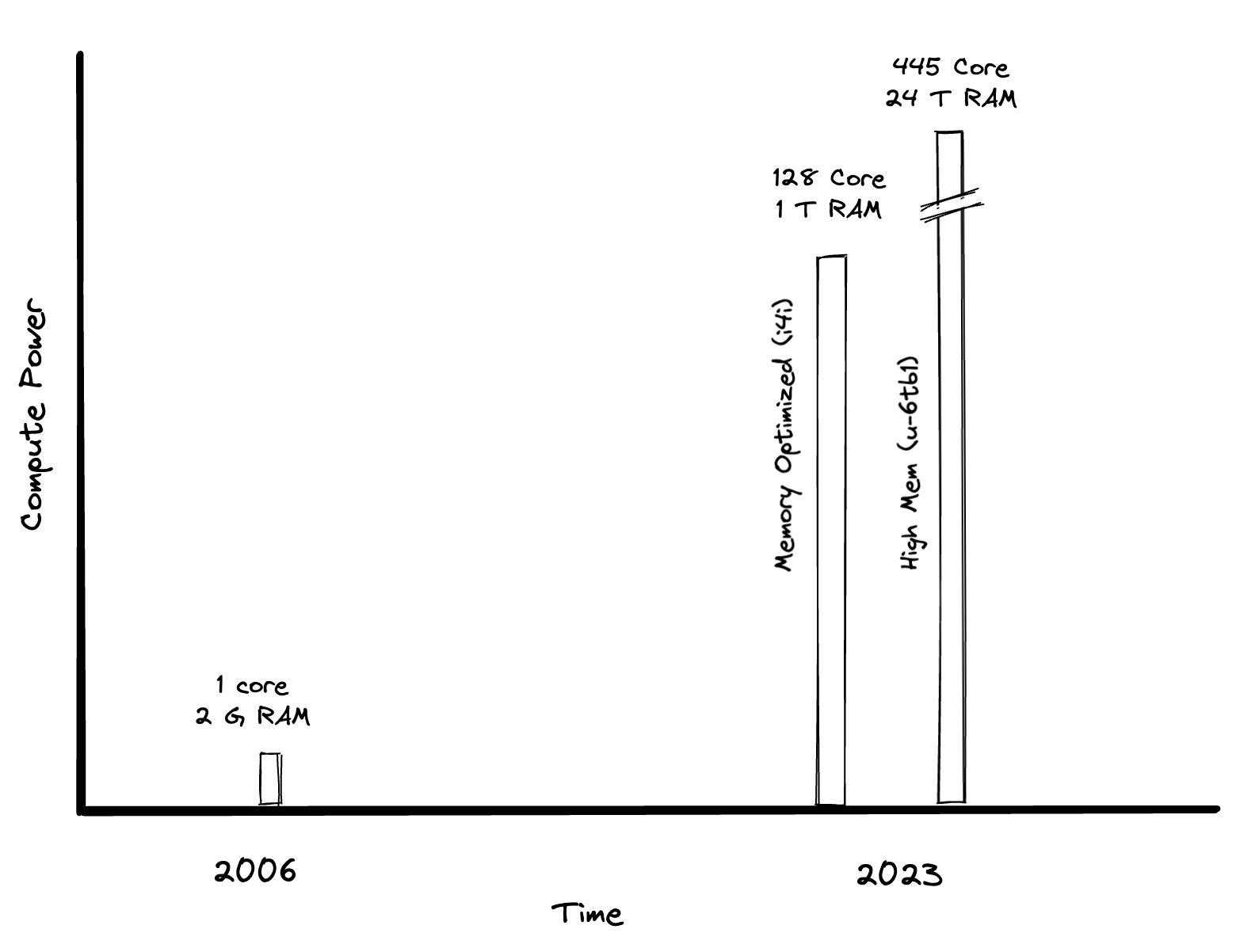
The Dremel paper, written in 2008, included some benchmarks running a 3,000 node Dremel system against an 87 TB dataset. Today you can get equivalent performance on a single machine.
At the time, Dremel’s capabilities seemed impossible without indexes or pre-computed results; everyone else in the database world was trying to avoid table scans, but they said, “Nah, we’re just going to do table scans really fast and turn every query into a table scan.” By throwing huge numbers of machines at problems, they were able to achieve performance that seemed like black magic. Fifteen years later, we can get similar performance without resorting to any magic at all, or even a distributed architecture.
In the appendix, I walk through the math to show that it would be possible to achieve this level of performance in a single node. This chart shows various resources and how they compare to what would be needed to achieve equivalent performance from the paper. Higher bars are better.
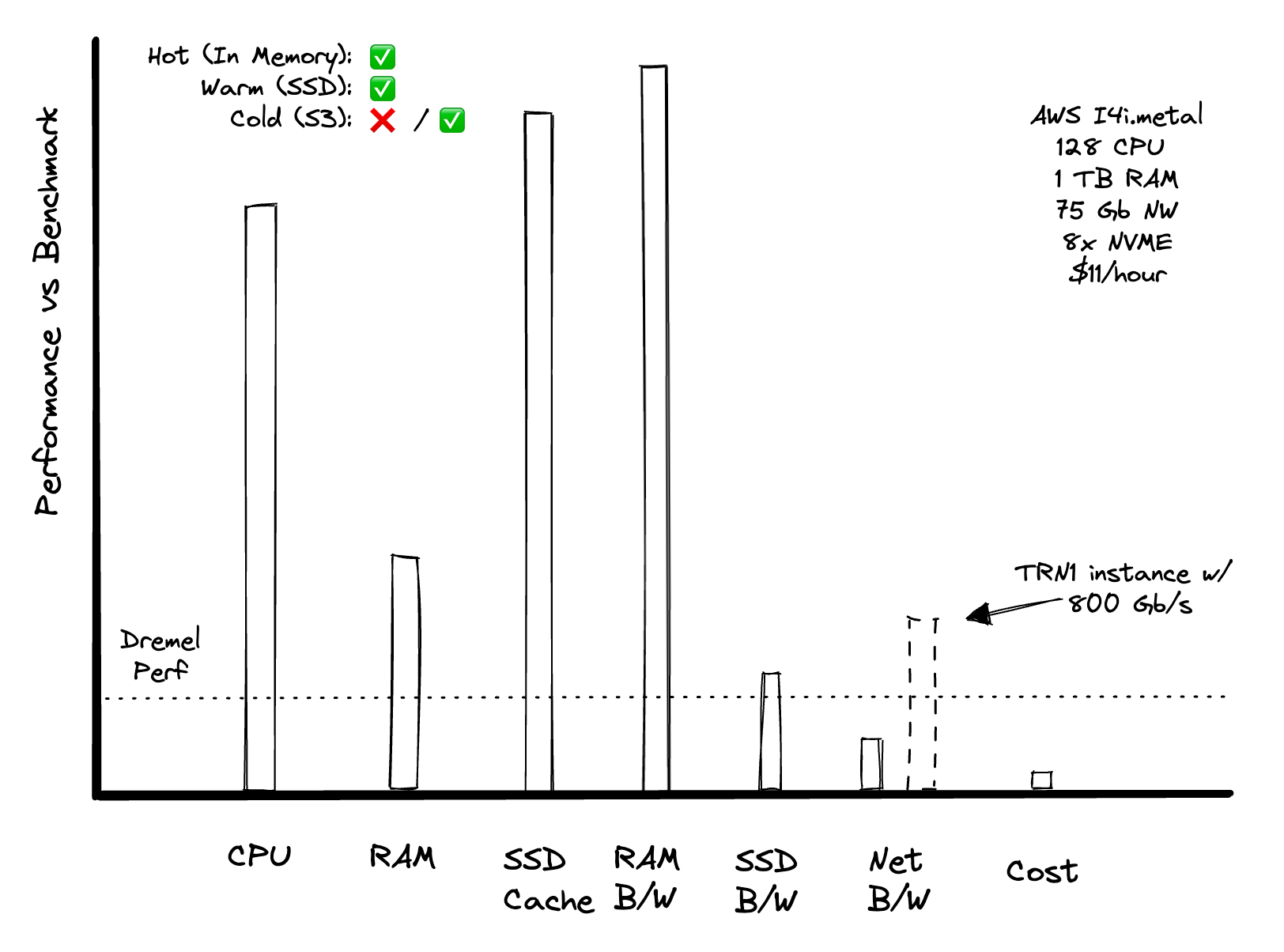
In this we see that one machine can achieve performance of the 3,000 node Dremel cluster under “hot” and “warm” cache conditions. This is reasonable given that many scale-out systems, like Snowflake, rely on local SSD for cache in order to get good performance. If the data was “cold” (in an object store like S3) we could still achieve the requisite performance, but we’d need a different instance type to do so.
I could scale up but larger machines are too expensive [❌]
Scaling up used to mean dramatically increasing your costs. Want a machine that is twice as powerful? It might have cost you several times as much.
In the cloud, everything gets run on virtual machines that are small slices of much larger servers. Most people don’t pay much attention to how big these are, because there are few workloads that need the whole machine. But these days, the physical hardware capacities are massive, often having core counts in the hundreds and memory in the terabytes.
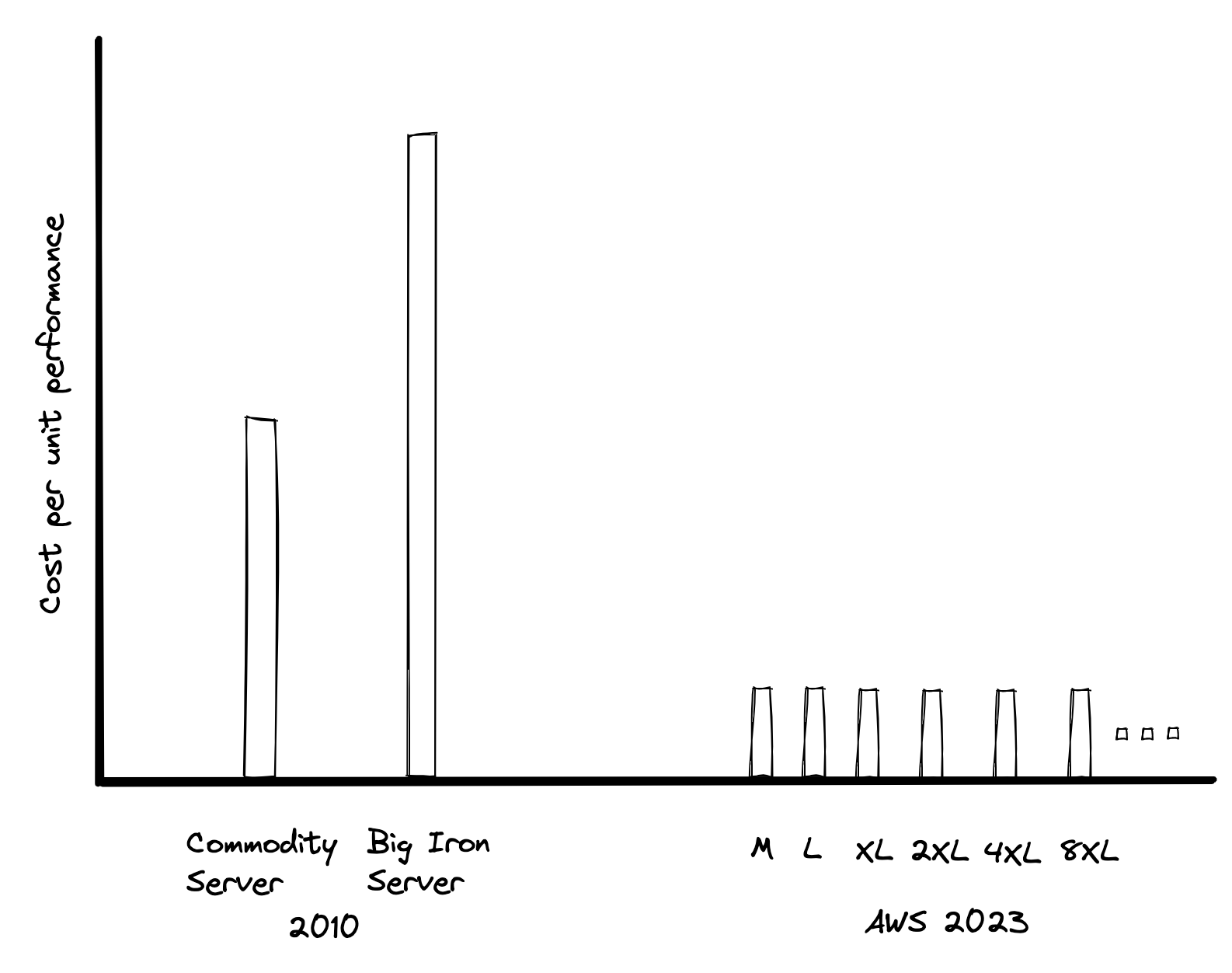
In the cloud, you don’t need to pay extra for a “big iron” machine because you’re already running on one. You just need a bigger slice. Cloud vendors don’t charge proportionally more for a larger slice, so your cost per unit of compute doesn’t change if you’re working on a tiny instance or a giant one.
It is easiest to think about the problem in terms of cost to achieve a given level of performance. In the past, larger servers were more expensive per unit of compute power. Nowadays, in the modern cloud, the price for a given amount of compute on AWS is constant until you hit a very large size.
The other advantage that you have in the cloud is that you don’t need to keep spare hardware around. That’s your cloud provider’s job. If your server crashes, AWS will respawn your workload in a new machine; you might not even notice. They’re also constantly refurbishing the datacenter hardware, and a lot of important improvements get done without any work on your part.
Cloud architectures also enable separation of storage and compute, which means that compute instances often store very little data. This means that in the event of a failure, a replacement can be spun up very quickly since you don’t have to reload any data. This can reduce the need for a hot standby.
Scaling out is more reliable [—]
Scale out architectures are generally considered to be more reliable; they are designed to be able to keep running despite lots of different types of failures. However, scale out systems haven’t significantly improved reliability, and you can get good enough reliability from scaling up.
Availability in the cloud is often dominated by external factors; someone fat-fingers a configuration and resizes a cluster to 0 (this happened briefly in BigQuery several years ago), network routing gets messed up (the cause of historical multi-service Google outage), the auth service you rely upon is down, etc. Actual SLA performance can be dominated by these factors, which can cause correlated failures when failures happen across multiple systems and products.
As a rough rule of thumb, cloud scale-out databases and analytics providers offer a 4-9s SLA (99.99% availability). On the other hand, people running their own scale-up systems have been holding themselves to at least that threshold of availability for a long time. Many banks and other enterprises have 5- and 6- 9 mission critical systems that are being run on scale-up hardware.
Reliability is also about durability as well as availability. One of the knocks against scale-up systems was that in the event of a failure, you needed to have a replica of the data somewhere. Separation of storage and compute basically solves this problem. Once the final destination for storage is not in the same machine where you perform the compute, you don’t have to worry about the lifetime of the machine running the compute. The basic shared disk infrastructure supplied by cloud vendors, like EBS or Google Persistent Disk, leverages highly-durable storage under the covers so that applications can get high degrees of durability without needing to be modified.
How to stop worrying and love the single node
So we’ve seen that the three main arguments for scale out – scalability, cost, and reliability – are not as compelling as they might have been decades ago. There are also some benefits of scaling up, that seem to have been forgotten, that we’ll discuss here.
KISS: Keep it Simple, Stupid [✅]
Simplicity. Scale out systems are significantly more difficult to build, deploy, and maintain. As much as engineers love to debate the merits of Paxos vs RAFT, or CRDTs, it is hard to argue that these things don’t make the system significantly more complex to build and maintain. Mere mortals have a hard time reasoning about these systems, how they work, what happens when they fail, and how to recover.
Here is a network diagram from Wikipedia describing the “simple” path of the Paxos distributed consensus algorithm, showing no failures. If you are building a distributed database and want to handle writes to more than one node, you’ll need to build something like this:
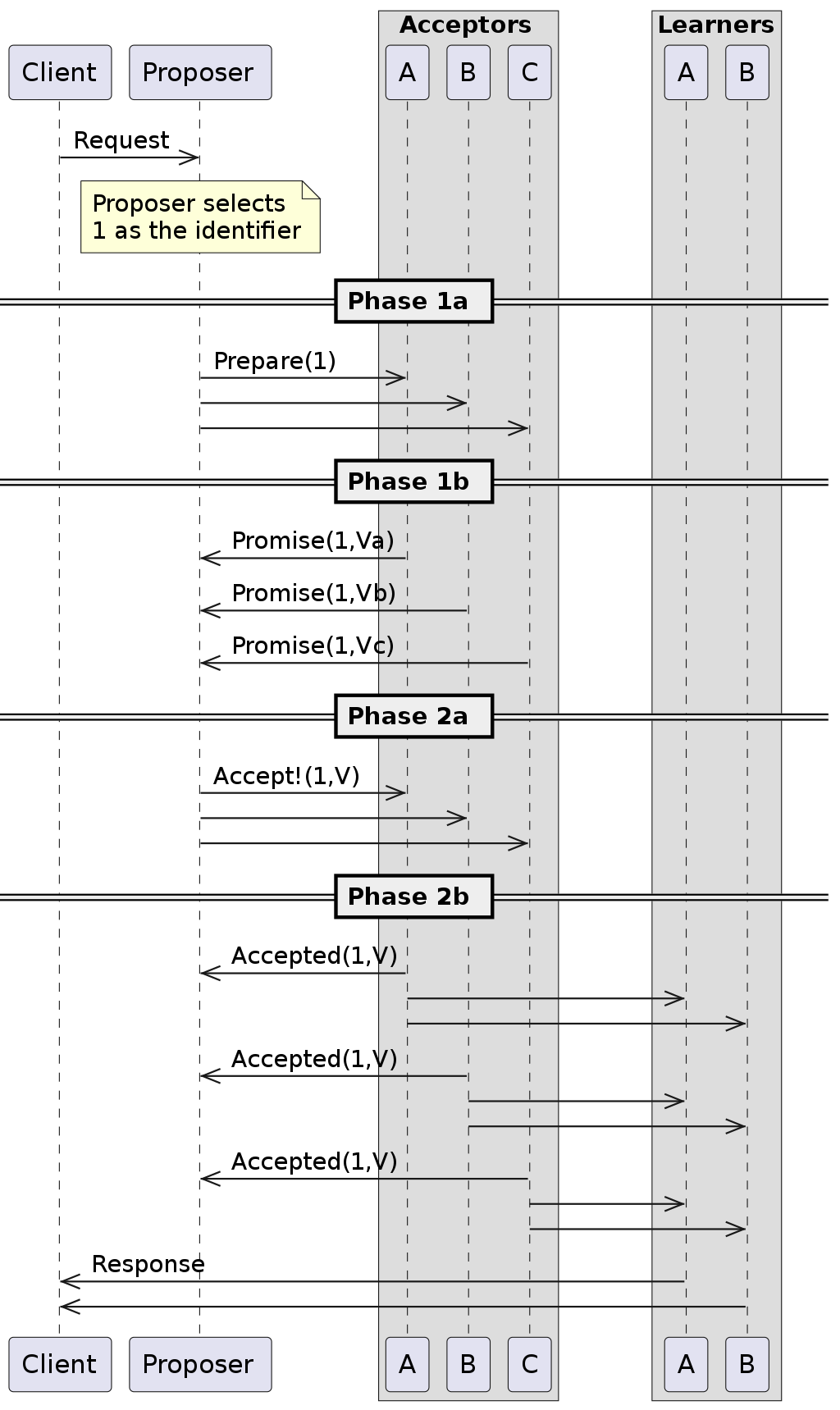
The actual protocol here is not as important as the fact that this is the simplest case of one of the more basic algorithms for distributed consensus. Engineering millenia have gone into implementing these algorithms. On a single node system, these algorithms are generally unnecessary.
Building software for distributed systems is just harder than building on a single node. Distributed databases need to worry about shuffling data between nodes for joins, and aligning data to particular nodes. Single-node systems are dramatically simpler; to do a join you just create a hash table and share pointers. There are no independent failures that you have to recover from.
The downsides of complexity aren’t just felt by the programmers building the systems themselves. Abstractions leak, so things like eventual consistency, storage partitioning, and failure domains need to be handled by developers and end users. The CAP theorem is real, so users of distributed systems will need to make active tradeoffs between consistency, availability, and what to do when you get network failures.
Deploying and maintaining single node systems are generally a lot easier. They are up or they are down. The more moving parts you have, the greater the number of things that can go wrong and the higher the likelihood. Single nodes have one place to look for problems, and the problems they have are easier to diagnose.
Perf: The Final Frontier [✅]
Given a choice between faster or slower, nearly everyone will choose faster. Single node systems have important performance advantages over distributed systems. If you just think about it in a vacuum, adding a network hop is going to be strictly slower than avoiding one. When you add things like consistency protocols, this impact can get much worse. A single node database can commit a transaction in a millisecond, whilst a distributed one might take tens or hundreds of milliseconds.
While distributed systems can improve overall throughput when the system is network bound, they also generate significant additional network usage for non-trivial work. For example, if two distributed datasets need to be joined, if they haven’t been carefully co-partitioned, data shuffling will add considerable latency. There really isn’t a viable way to make arbitrary distributed joins as fast as they are on a single node system.
To show an example of why a distributed architecture is going to have limitations on performance, take a look at BigQuery’s stylized architecture diagram:
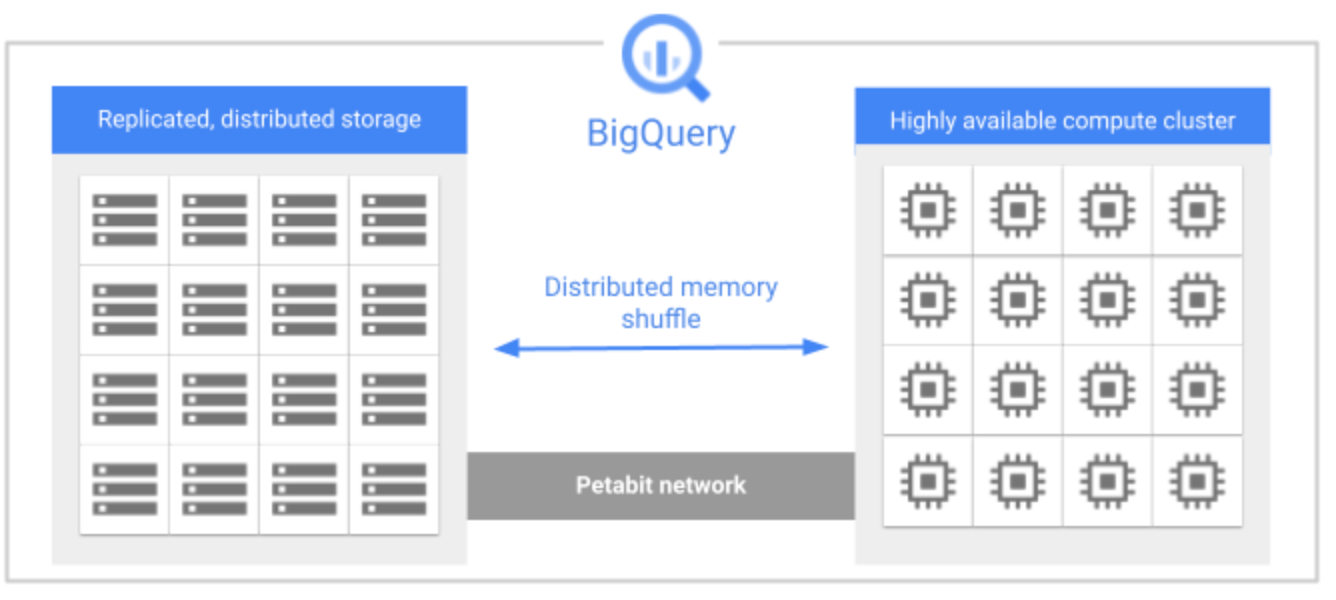 Image by Google Cloud, https://cloud.google.com/bigquery/docs/storage_overview
Image by Google Cloud, https://cloud.google.com/bigquery/docs/storage_overview
The petabit network that connects everything may sound fast, but it is still a bottleneck because so many operations need to move data across the network. Most non-trivial queries are network bound. A single node system would need to move far less data since there is no need to do a shuffle.
Waiting for Mr Moore
We looked at the rationales behind scaling out and saw that they are much weaker than they had been in the past.
- ❌Capacity. Modern single-node systems are huge and can handle almost any workload.
- ❌Reliability. Scaling out doesn’t necessarily lead to more robust systems.
- — Cost. Cloud vendors don’t charge more per core for larger VM sizes so cost is a wash.
We also talked about some of the benefits of scale up:
- ✅Simplicity. Simple systems are easier to build, operate, and improve.
- ✅Performance. A distributed system will almost always display higher latency, especially tail latency, than a single node system.
Let’s say you’re not convinced, and you need to scale out. But what about in 5 years, when machines are an order of magnitude bigger?
We’re ready for a new generation of systems that take advantage of single-node performance. Innovation will move faster, and you’ll be able to focus on actually solving problems rather than in coordinating complex distributed systems.
Appendix Dremel in a box
This appendix compares the benchmark results from the Dremel paper with running a similar workload on a single large machine on modern hardware. While it would be nice to have a practical outcome to demonstrate it, it is easy to argue with benchmark configurations and whether something is actually a fair comparison. Instead, we’ll show that modern hardware should be up to the challenge.
The paper authors ran on a 3,000 node Dremel cluster. For the record, this much hardware in BigQuery would cost you more than $1M a year. We’ll compare it to an i4i.metal instance in AWS that costs $96k a year, has 128 cores and 1T of RAM. We’ll use this to run a side-by side bake-off.
Here is a snippet from the paper that shows the computation that they ran to benchmark against MapReduce:


In the Dremel paper, the main performance result showed being able to do a scan and aggregation query over 85B records in about 20 seconds, reading half a terabyte of data. This was orders of magnitude faster than MapReduce-based systems. It was also far beyond what you could do in more traditional scale-up systems at the time.
In order to match the level of performance in the paper, you’d need to be able to scan 4.5B rows and 25GB of data per second.
CPU
SingleStore has an old blog post and demo showing that they can scan more than 3B rows per second per core, which would mean that on a machine the size of our I4i you’d be able process 384 B rows per second, almost two orders of magnitude more than we need to match Dremel. Even if it takes 50x more processing power to count the words in a text field, we still have a comfortable buffer.
Memory
Memory bandwidth on a single server is likely going to be in the TB/s, so that likely isn’t an issue. As long as the data is staged in memory, we should have no problem at all reading 500 GB in 20 seconds. The columns used in the query would take up half of the memory in the machine, so if we have those pre-cached, we’d still have half a terabyte of memory in order to do the processing or to store inactive cache. However, this feels like cheating, since it relies on having the exact columns needed in the query cached in memory ahead of time.
Local Disk
What if the data that we need were stored on the local SSD? Many databases, Snowflake, for example, use local SSD as staging locations for hot data. The I4i servers have a total 30TB of NVMe SSD, which means we can fit 30 times more in the cache on SD than we could in memory, and 60 times more than we need for this query. It doesn’t seem unreasonable that the active columns in this query would be cached in the SSD under a reasonable caching policy.
If capacity isn’t an issue, what about bandwidth? NVMe drives are fast, but are they fast enough? The 8 disks in these instances can do a total 160k IOPS per second, with a maximum size of 256KB for each operation. This means we can read 40 GB/second, which is more than the 25 we need. It isn’t a whole lot of headroom, but it should still work.
Object Store
Finally, what if we wanted to do it “cold,” where none of the data was cached? After all, one of the benefits of Dremel was that it could read data directly from object storage. Here is where we’re going to run into a limitation; the I4i instance only has 75 Gigabits/sec of networking capacity, or roughly 9 GB/s. That’s about a third of what we’d need to be able to read directly from object storage.
There are instances that have much higher memory bandwidth; the TRN1 instances have 8 100-gigabit network adapters. This means you can do 100 GB/sec, significantly higher than our requirements. It would be reasonable to assume that these 100 Gb NICs will be more widely deployed in the future and make it to additional instance types.
We acknowledge that just because you have hardware available in a machine doesn’t mean that it is all uniformly accessible and that performance increases linearly with CPU count. Operating systems aren’t always great at handling numbers of cores, locks scale poorly, and software needs to be written very carefully to avoid hitting a wall.
The point here isn’t to make claims about the relative efficiencies of various systems; after all, this benchmark was performed 15 years ago. However, it should hopefully demonstrate that workloads that operate over a dataset nearing 100 TB are now reasonable to run on a single instance.
Start using MotherDuck now!

