Claudeception: Inside the Mind of an Analytics Agent
2026/03/19 - 7 min read
BYSpend enough time on AI Twitter and you'll hear researchers talk more about growing large language models than building them. The argument goes: we don't always understand why models behave like they do, just that a combination of training data, GPUs, and reinforcement learning have us racing towards a beautiful and terrifying future. Therefore, training an LLM is more like tending to a rare plant than writing a data pipeline. I'll leave you to stew on that.
Back here on Earth, we're just trying to harness these things to get reliable answers from our data. There's a similar pattern, though–we can watch analytics agents use tools, write SQL, and return results. But to understand how is opaque to end users. That sounds like the perfect problem for a few more agents.
Let's take a look, then, inside the mind of an analytics agent. Does iterative querying really matter? Is the semantic layer really dead? Let's see.
The Setup: Analysis and Meta-Analysis
BIRD-Bench is a text-to-SQL benchmark that joins a long tradition of doing what academic benchmarks do best: coercing names into acronyms for clever paper submissions. The entire benchmark is 33GB and chock full of messy data–in a throwback to mid 2000s online math homework, questions are frequently ambiguous with unclear logic. It feels "real world", to a fault.
We care most about the agent behind the curtain, so we ran a 50-question sample of BIRD-Bench through a testing harness using Claude Opus 4.5 (Anthropic's most capable model) and the MotherDuck MCP Server. Sampling here is mostly for convenience – benchmarks like these get pricey, fast.
Each run includes a chain-of-thought (CoT) response from the Claude API, returned as a JSON trace. The CoT contains the agent's internal monologue, MCP tool use, and query results as it works through a question iteratively. Here's an example snippet of a CoT response:
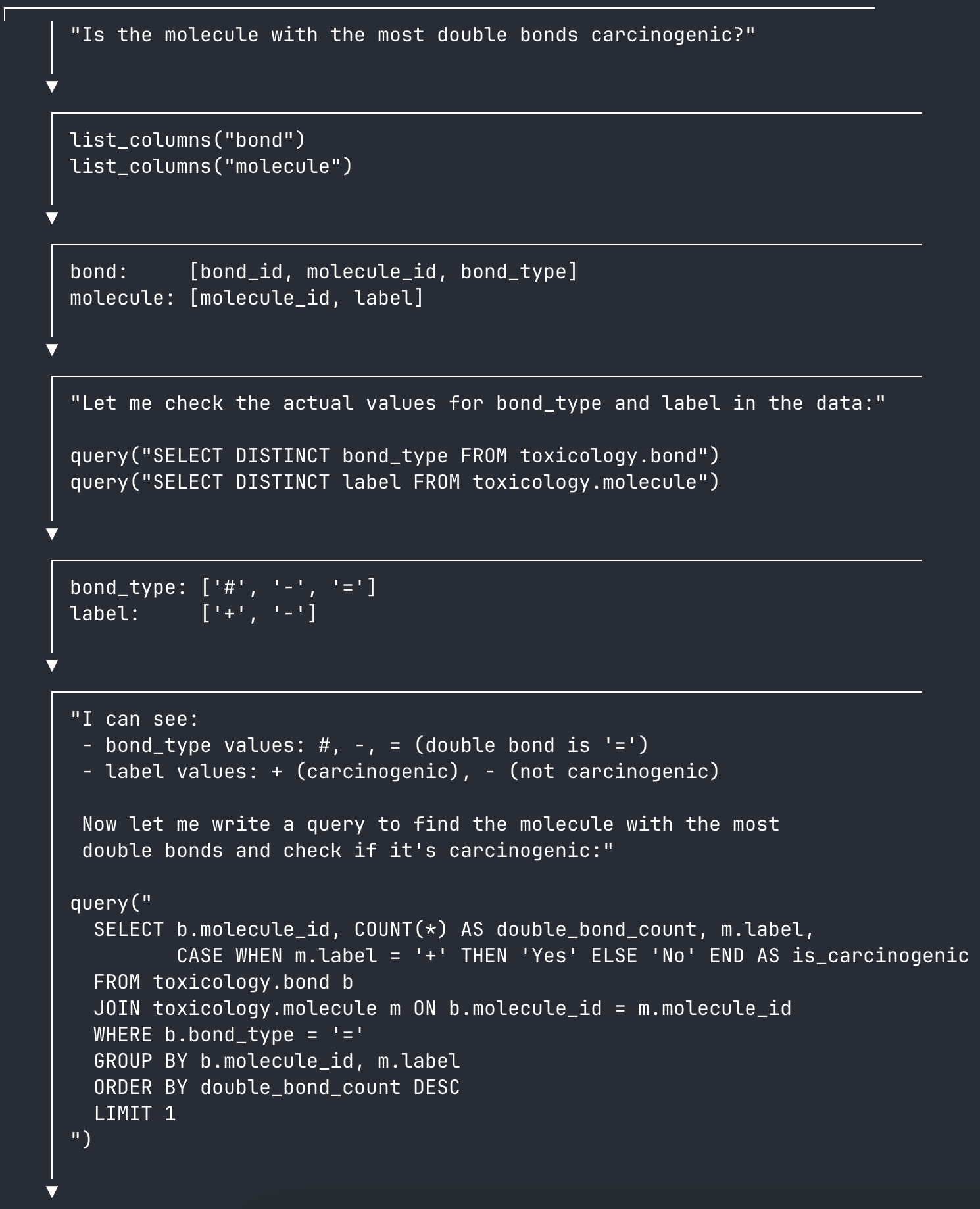
Just in this sample, you can see the agent calling tools like list_columns and query, returning results, and thinking its way to a correct answer.
We harvested traces and results from all 50 questions in the sample, then ingested them into MotherDuck for easy access with the MCP Server. Then we built a bootstrapped classification pipeline using a team of Claude sub-agents in an "LLM as judge" method to classify each trace. Opus (Anthropic's most capable reasoning model) provides the orchestration and instructions to the Sonnet sub-agents, then aggregates classification results. Everything–from stateless trace classification to aggregation and reporting–is run by Claude. Think about it as vibe map-reducing.
HINT: Sub-agents for parallel tasksTeams of sub-agents can improve throughput while running in the same Claude Code process. You know, like DuckDB multi-threading.
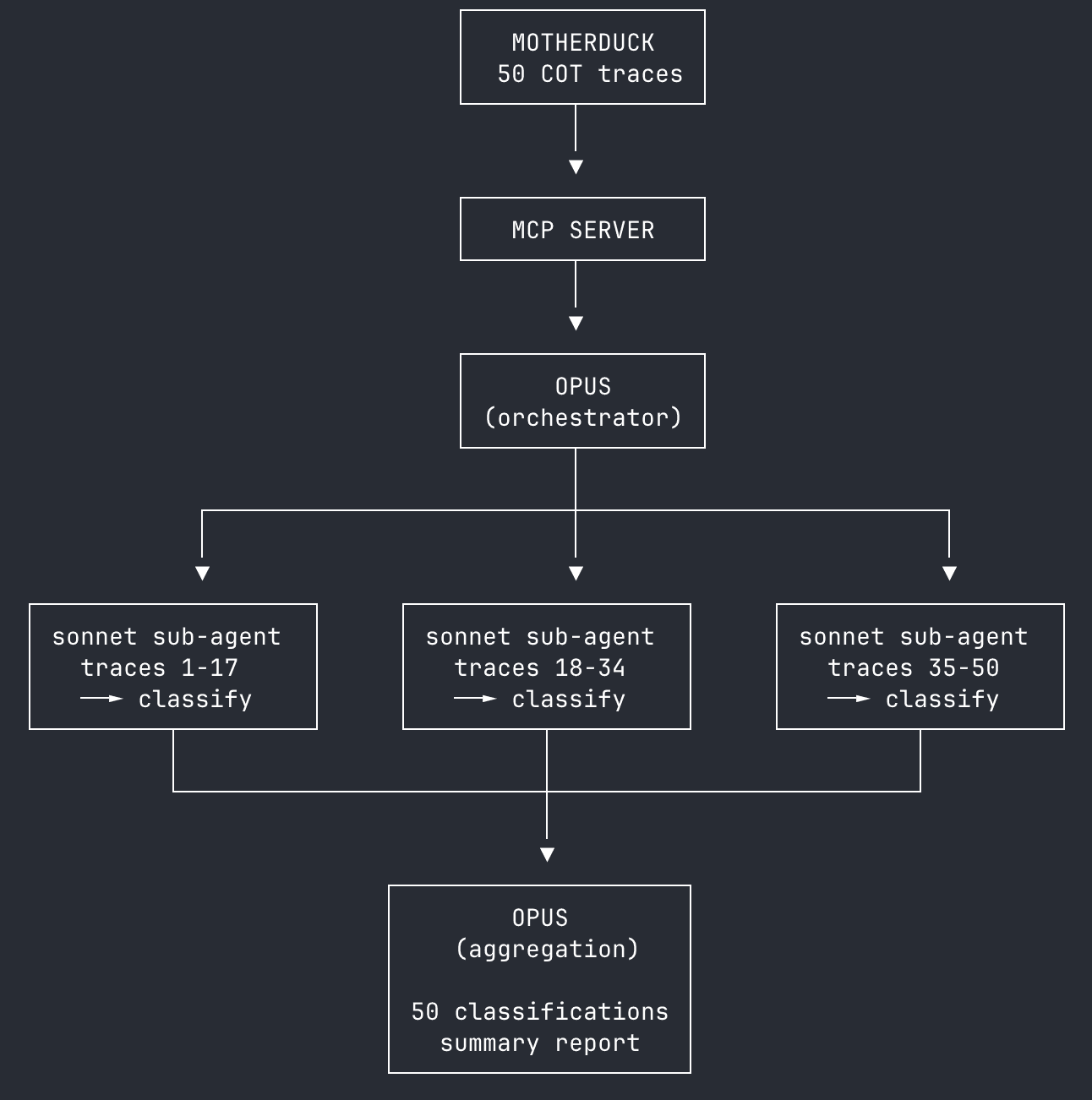
Like any good analyst, Claude has some classification dimensions for our traces:
- Query iterations: Single-shot, Iterative, or Struggling
- Error recovery: No errors, Recovered, or Stuck
- Tool effectiveness: Wasted, Adequate, or Leveraged
Once classified, Claude can reason through the correct, incorrect, and partial responses to correlate classification and benchmark results. Interesting questions include:
- If the agent uses tools more frequently, should we expect better results?
- Is running more queries a straightforward sign that the agent is likely to fail?
- Does time spent exploring schemas improve query results?
We're digging through the trash a bit here, looking for explanatory variables inside a probabilistic system. But building an intuition for how agents use data is our goal, and our team of Claudes is more than up to the task.
Iterative Loops
Unsurprisingly, easy questions are easy for agents. Using single-shot execution portends a correct answer–we're far along with frontier LLMs that they can one-shot plenty of data questions. Single-shot answers were correct 91% of the time.
When the agent entered a more iterative loop, results became less clear:
- Single-shot: 23 traces, 91% success rate
- Iterative: 25 traces, 64% success rate
- Struggling: 2 traces, 0% success rate
Iteration is a complex pattern–sometimes, it was a signal that the agent found the question difficult, and was running through many tool use loops to try and return an answer. 64% of the time, though, the agent hit a wall, tried a new approach, and succeeded.
Take a look at this successful run. The agent:
- Searches for relevant columns
- Checks the contents with initial queries
- Composes a results query, returns no results ("uh oh")
- Changes course, reevaluates the question
- Re-composes another results query, then succeeds
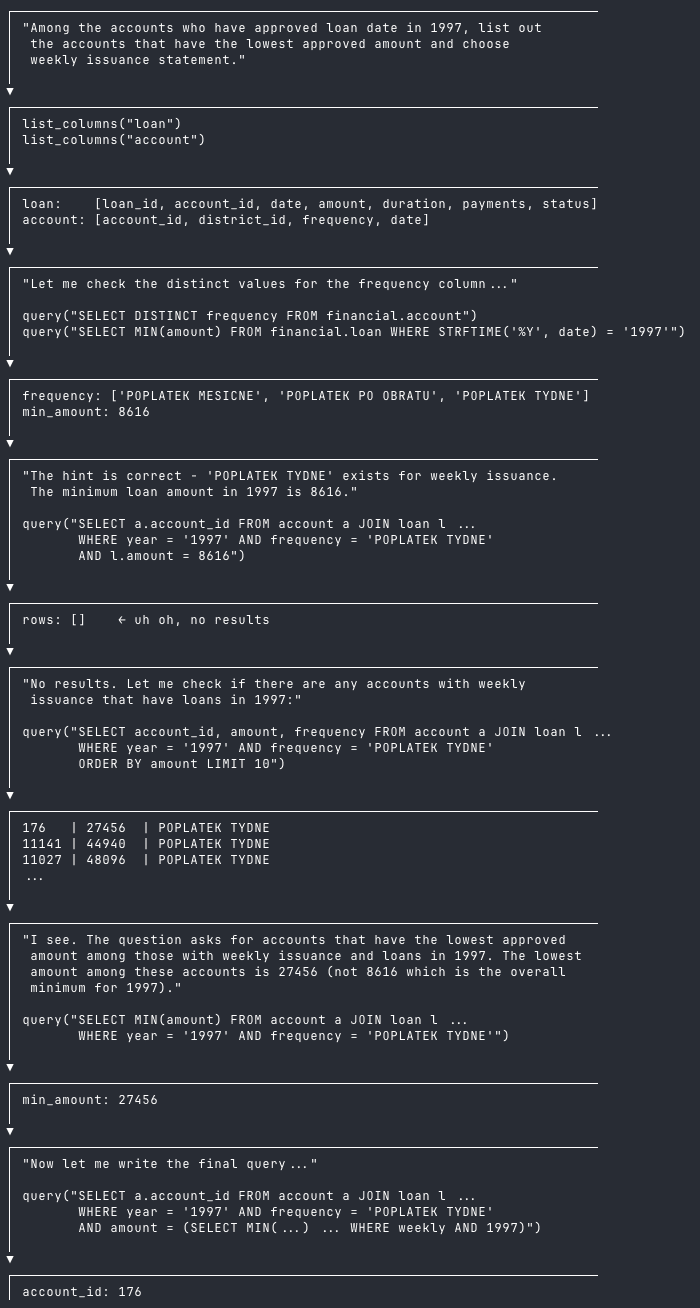
If you were building your own agent and looking at nothing else but classifying query patterns, you could pretty safely evaluate single-shot answers as quality responses. The agent looks a lot like an analyst here, though perhaps a more junior one: investigating and running into issues before changing tack and succeeding.
Space Cadet Claude
What about when the iteration loop fails? Here we have an example of a failure on semantics. Tackling the BIRD-Bench question "What's the finish time for the driver who ranked second in 2008's Chinese Grand Prix?", the agent confuses two semantically similar columns: position and rank.
This shouldn't be a fatal error–a human can evaluate the query results and see that we also have fastestLapTime in the table, a backstop to use in case of ambiguity. But the agent misunderstands, taking position as the finishing position of the race, and fails the question.
Adding column comments can provide agents helpful direction when navigating semantically similar columns.
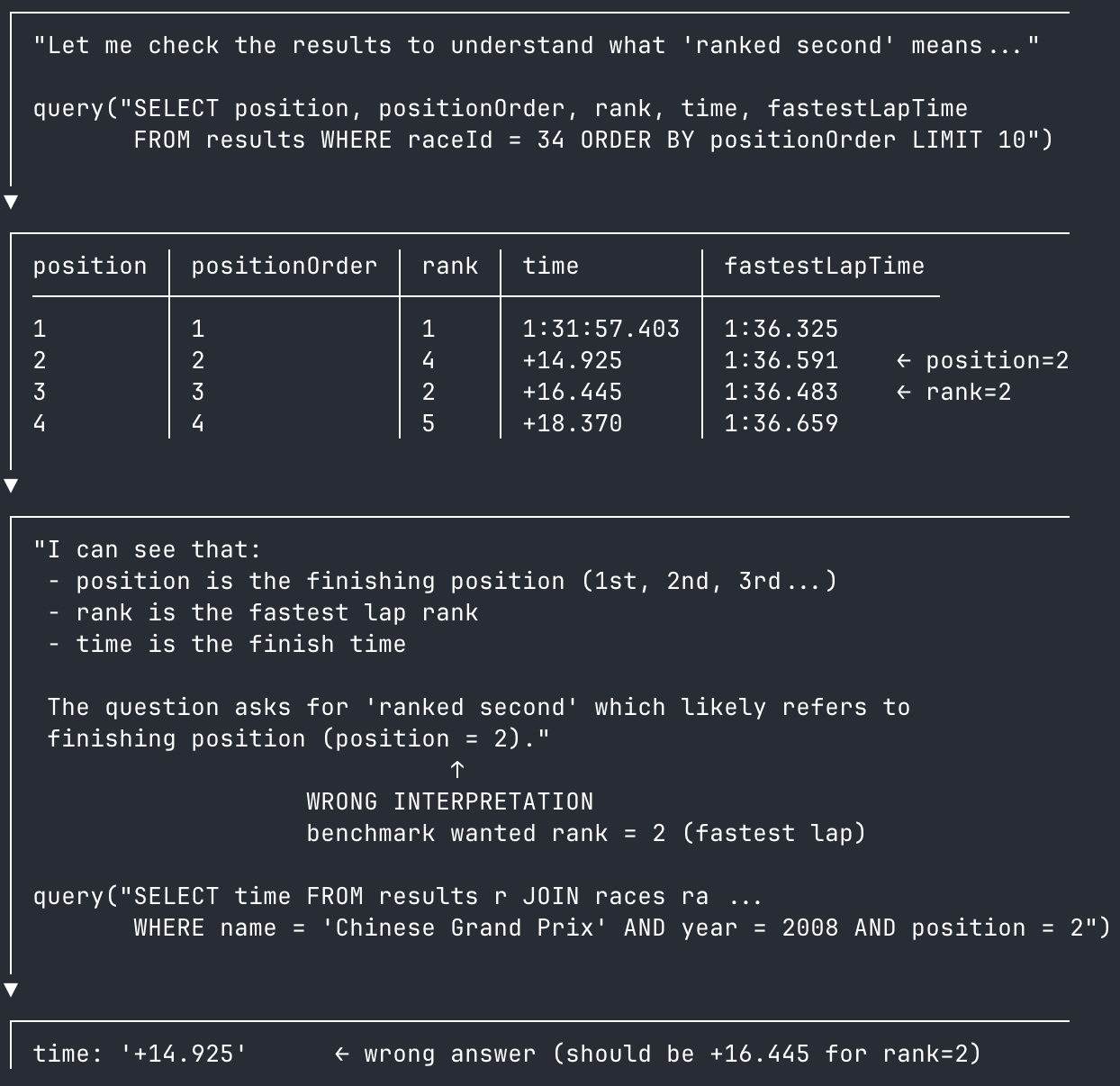
Funnily enough, our Claude-as-judge agent clocks this immediately, blaming the original Claude's interpretation of the question and correct identifying the answer. The original agent even wrote the correct query before getting the question wrong!
This is the perfect anti-pattern for our agent use case–the benchmark uses a table with two similar column names and the agent guesses wrong. Why did it guess wrong, you ask? Well, an exact answer might have to wait for the latest in LLM research. In the meantime, let's see what Claude has to say:
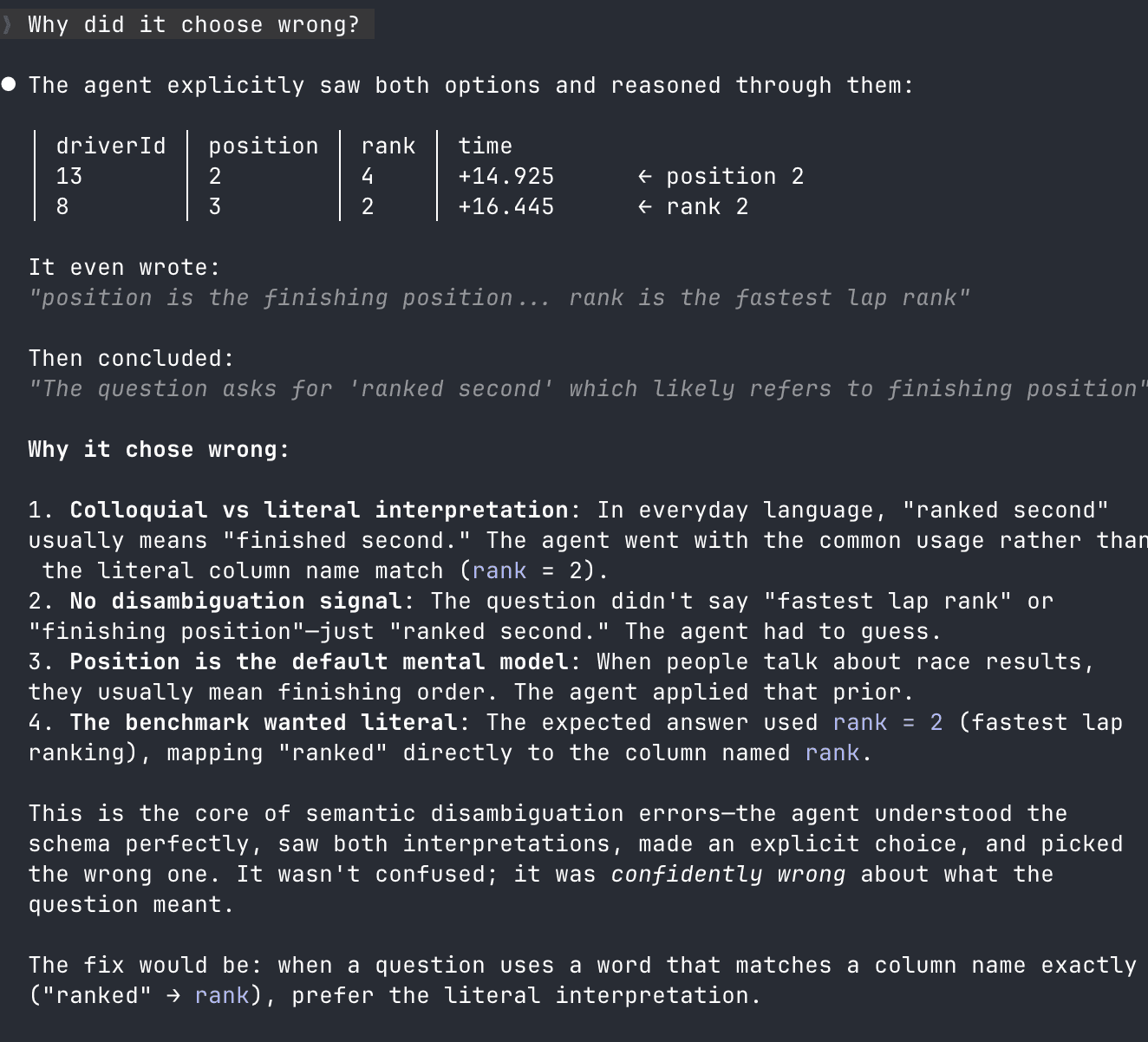
Surprisingly plausible! Despite the mapping of "rank" in the question and as a column name, the agent still got its synonyms mixed up and mapped "rank" onto the position column.
Right away, you could imagine just throwing tokens at the problem; another agent checking work might catch the wrong answer and reevaluate the question–OpenAI uses this pattern in their own systems. But stacking agents misses the point, the point is that to actually look at the data and build an intuition for the system–warts and all.
The Semantic Layer Fixes This
Just kidding, I'm not sure it does. At least, not in its current manually built, pre-defined state.
The BIRD-Bench benchmark gives our agent nothing–no column comments, no semantic views, even garbled questions to simulate real-world usage. Sure, you could create a semantic definition for each of our confusing columns, but consider how they came together in the real world.
The likely scenario: someone started with rank and the race times, because those were the results of the race. They later added position, to contrast the end of the rank with the beginning. Later again they added positionOrder for…some reason. Each schema change demands a semantic update to anticipate the questions being asked of the data–a task that falls squarely on the data team. What if we thought less about anticipating those future questions and more about what already has been asked?
We've been thinking about this a lot – specifically, how to use system internals like query history to create a more adaptable, fluid layer of context for analytics agents. Databases already contain so much harvestable context on how humans use them–it's time we turn our agents loose on it.
Start using MotherDuck now!
PREVIOUS POSTS

2026/03/09 - Alex Monahan
DuckDB 1.5 Features I am Excited About
DuckDB 1.5 is both faster and easier to use! JSON analysis can be up to 100x faster thanks to the VARIANT type and JSON shredding. Real-world queries are faster, including both basic and complex queries. Writes to Azure are supported, and checkpoint concurrency is dramatically improved.
