2024/02/14 - Hamilton Ulmer
Introducing the Column Explorer: a bird’s-eye view of your data
Column explorer : fewer queries, more insights
- 10 min read
BY- 10 min read
BYDuckDB is portable, easy to use, and ducking fast! We at MotherDuck put our money where our beaks are and embarked on a journey to build a new type of serverless data warehouse based on DuckDB. This means extending DuckDB beyond its design as an embedded, local, single-player analytics database, and turning it into a multi-tenant, collaborative, secure, and scalable service.
Today we’d like to talk about Differential Storage, a key infrastructure-level enabler of new capabilities and stronger semantics for MotherDuck users. Thanks to Differential Storage, features like efficient data sharing and zero-copy clone are now available in MotherDuck. Moreover, Differential Storage unlocks other features, like snapshots, branching and time travel which we’ll release in the coming months.
Folks over at DuckDB Labs, the team behind DuckDB, have a strong conviction for what DuckDB is - a powerful in-process analytics database. Crucially, they have an equally strong conviction for what vanilla DuckDB is not - a central collaborative data warehouse.
We decided at MotherDuck to implement a new copy-on-write storage solution named Differential Storage to solve a number of problems that arise when running DuckDB as a central collaborative data warehouse, such as:
The rest of this blogpost will dive into the actual implementation of Differential Storage and how it enables us to solve these problems.
Differential Storage is implemented as a FUSE driver (FUSE is a framework for implementing userspace file systems) that provides a file-system interface to DuckDB. Thus DuckDB interacts with files stored in Differential Storage just as it would with files on any other file system, this provides a very clear interface between the two systems. Because of this we were able to implement Differential Storage without modifying any DuckDB code.
With Differential Storage, databases in MotherDuck are now represented as an ordered sequence of “layers.” Each layer corresponds to a point in time (a checkpoint) and stores differences relative to the prior checkpoint. Since each layer stores differences between that checkpoint and prior layers, we call this system “Differential Storage.”
Differential Storage allows us to store many point-in-time versions of a database, without needing to duplicate the data that those versions have in common. That same capability makes it possible to efficiently store many copies (or clones, forks, branches, whatever term you like) of a database. This by itself gives us a coarse implementation of time-travel (at checkpoint granularity), where we can instantly re-materialize a database at the point of any prior checkpoint.
But we can do even better by exposing per-commit granularity snapshots of the database. We provide this full-fidelity time-travel by also keeping a redo-log of the commits that occurred between checkpoints, which can be applied to the corresponding base snapshot to reach the target point-in-time.
Before we deep dive into the different request flows for Differential Storage (read, write, fork, etc.) - it would be helpful to define some key concepts:
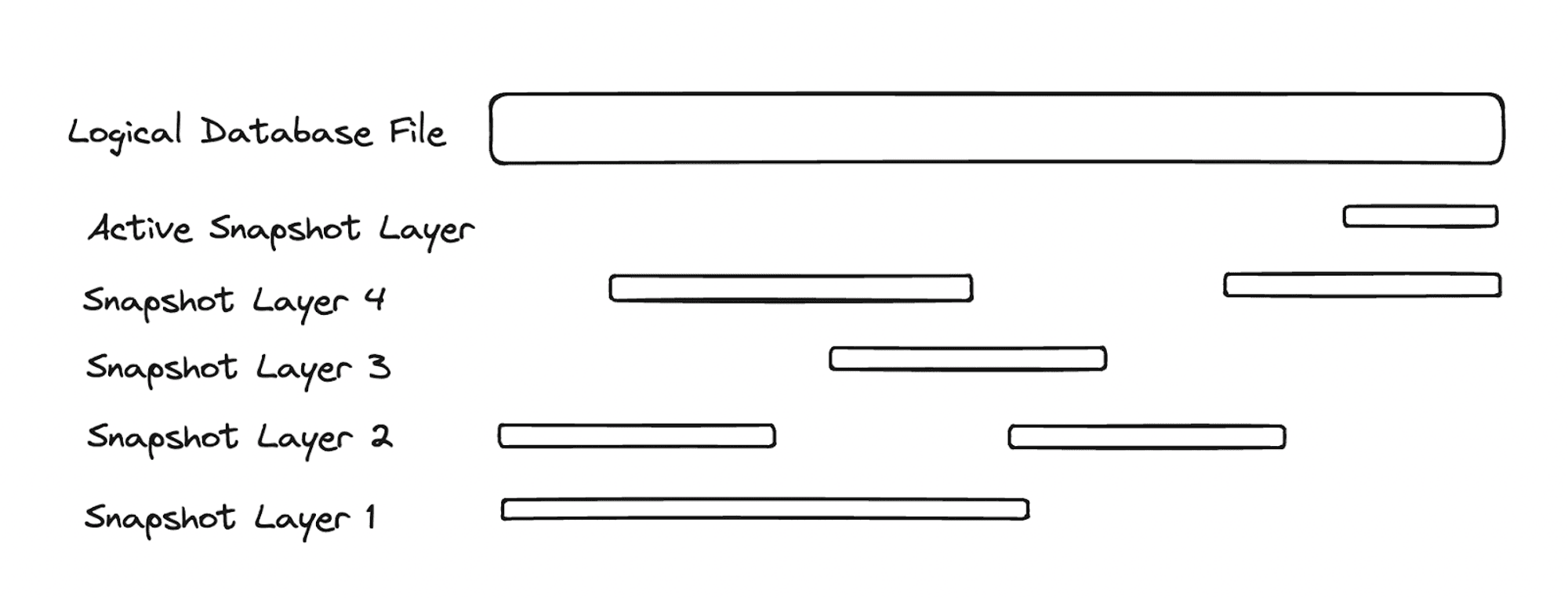
In the following diagram - you can see the logical database file spanning some range. The logical database file is the file that DuckDB sees and interacts with. Note that the logical database file does not correspond to an actual single, physical file, but is instead composed of a sequence of snapshot layers (from 4 -> 1), as well as an active snapshot layer representing the set of writes that have occurred since the last checkpoint.
Differential Storage will load the current snapshot and the corresponding sequence of snapshot layer metadata for a given database before it begins performing read/write operations on it. The database snapshot and snapshot layer metadata is persisted in a separate OLTP database system.
The following sections will trace through how Differential Storage performs some common operations: read, write, checkpoint, snapshot, and fork.
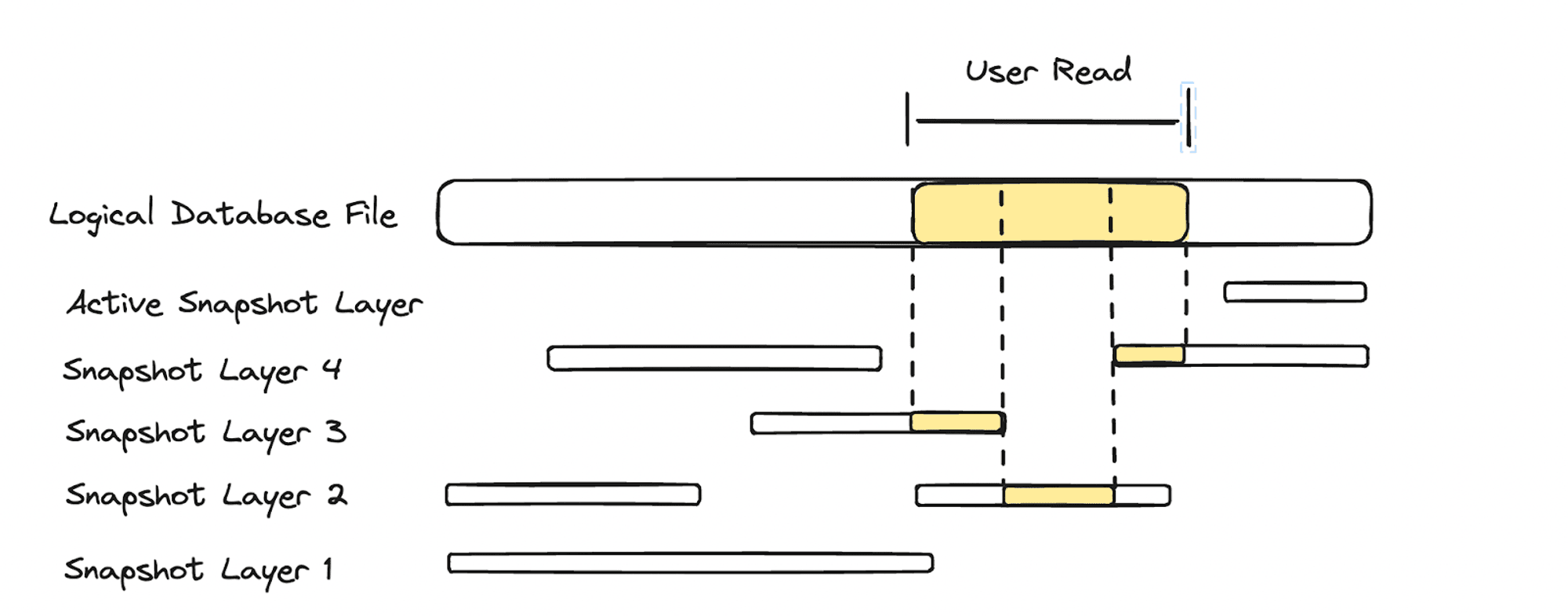
When DuckDB attempts to read some range of bytes from the logical database file, Differential Storage will split up the total read range into subranges and loop through them. For each subrange, Differential Storage will find and read from the newest snapshot layer (starting from the active snapshot layer) that contains the sub-range. It’s important to use the newest snapshot layer, because this layer represents the most recent bytes written to the logical database file for that given subrange.
In the following diagram, we see that the read for range [start, end] ends up being split into 3 separate reads across snapshot layers 3, 2, and 4.
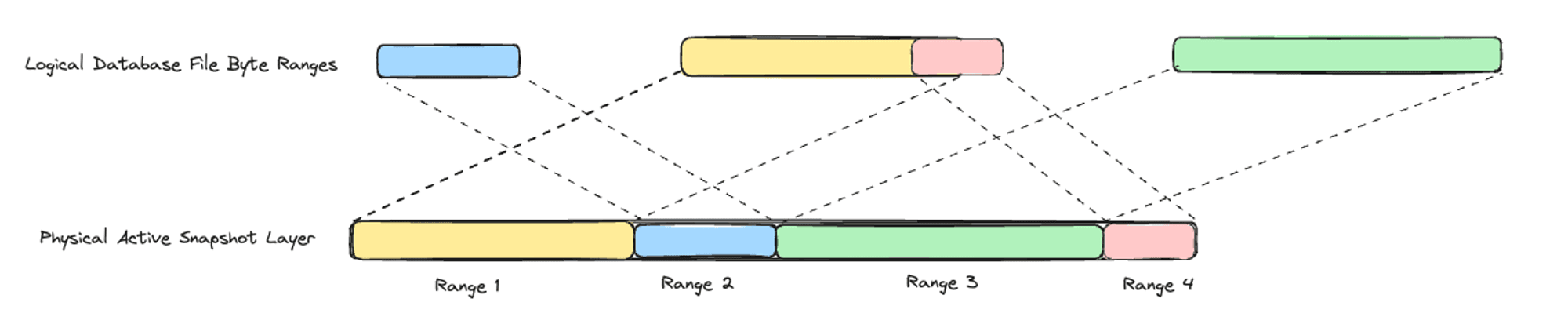
When DucKDB writes data to a random offset in the database file, Differential Storage appends the data to the end of the active snapshot layer file. Differential Storage writes in an append-only fashion so that the generated snapshot layer files are contiguous. Also by relying only on appends, we open the possibility to switching to an append-only storage system in the future. But because DuckDB writes to random offsets in the database file, Differential Storage must actively track of the mapping between the offset of writes into the logical database file -> their offsets into the physical active snapshot layer file.
This mapping logic is demonstrated by the following diagram. In this example, DuckDB has written the following byte ranges in the following order since the last checkpoint:
These bytes are appended to the active snapshot layer file in the order in which they occur:
Now if DuckDB attempts to write 50 bytes to the database file from range [575, 625]:
A DuckDB checkpoint will trigger Differential Storage to perform a snapshot. A DuckDB checkpoint will apply all commits recorded in the WAL to the database file. This means that once a checkpoint completes, DuckDB can load a database from just the current database file without having to access the WAL to perform WAL replay.
To perform a snapshot, Differential Storage has to upgrade the current active snapshot layer to become the newest snapshot layer. Differential Storage does this by transactionally recording the newly upgraded snapshot layer and snapshot (containing this new snapshot layer), and updating the database to point at this new snapshot. Once this is complete, Differential Storage will open a new active snapshot layer file and WAL file for accepting new writes.

Because all the previous snapshot layers are stored, it is an inexpensive metadata-only operation to materialize previous snapshots, which are simply subsequences of the current snapshot’s snapshot layers. The following diagram demonstrates how Differential Storage can easily time-travel to the state of the database file two snapshots ago by loading a snapshot composed of layers 3 -> 1.
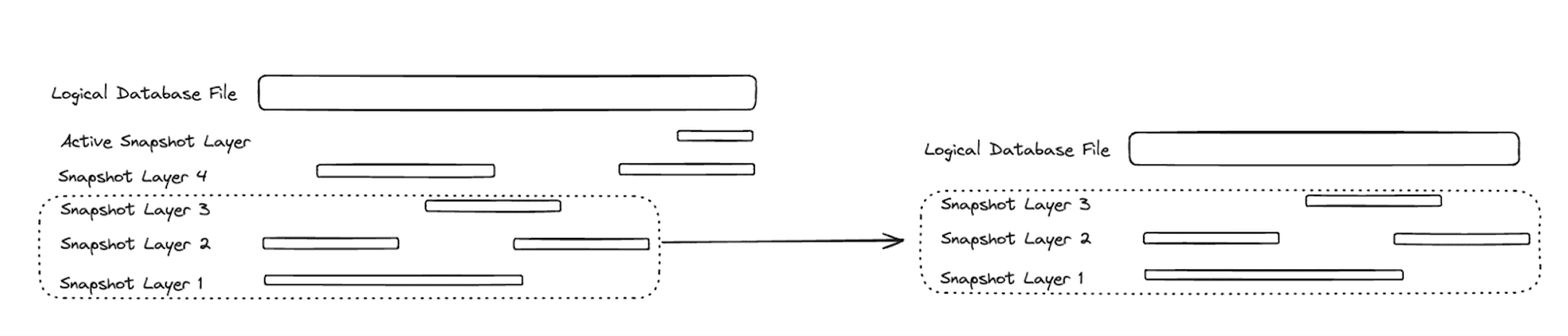
Now that we have the ability to easily materialize a fixed snapshot of the current database by selecting a subsequence of the snapshot layers, we can implement “forking” a database by applying a different set of changes (represented as snapshot layers) on top of one of its previous snapshots. The following diagram demonstrates how we can implement database forking (CREATE DATABASE Y FROM X) without performing any data copies.

The primary property of Differential Storage that enables a number of new features and optimizations is that past snapshot layer files (and thus snapshots) are immutable. Some of the most important new features and capabilities are:
Starting today, zero-copy snapshots and forks are available to all users of MotherDuck. Operations CREATE DATABASE <name> FROM <name> and CREATE SHARE <share> FROM <database> are now metadata-only operations, creating zero-copy forks of the source databases.
As previously mentioned in this blogpost, Differential Storage enables MotherDuck to easily materialize previous snapshots of a database. This capability will enable MotherDuck to provide powerful time-travel and backup/restore capabilities in a fast and inexpensive manner. Stay tuned, as time travel features are on MotherDuck’s near-term roadmap!
Because snapshot layer files are immutable it becomes quite easy to cache snapshot files. This drastically improves the efficiency of database sharing and opens the door for a number of performance and efficiency optimizations.
Today MotherDuck initially writes the active snapshot layer files to EFS. But because snapshot and WAL files become immutable post-snapshot, it is possible to swap them out to a cheaper object store (such as S3) post-snapshot. This setup results in EFS acting as a fast, SSD-based write cache in front of S3. This provides MotherDuck the ability to quickly commit new writes to EFS, while batching together larger amounts of data for writing to S3.
MotherDuck has implemented a new storage solution, Differential Storage, that solves a number of challenges of running DuckDB as a central collaborative data warehouse, around concurrency, performance, scalability, and unlocking new user capabilities for both collaboration and backup/restore.
We just rolled out this feature last week on MotherDuck - so we encourage you to try out our new zero-copy clone capability! We will continue rolling out exciting new features (as mentioned above) in the near future!
MotherDuck is on a mission to make analytics Ducking awesome for every kind of user:
attach md:, and your DuckDB instance suddenly becomes MotherDuck-supercharged.Come try our product for free, join our Slack for a chat, or shoot us a note!
2024/02/14 - Hamilton Ulmer
Column explorer : fewer queries, more insights

2024/03/01 - Ryan Boyd
DuckDB news: v0.10.0 adds backwards-compatible storage and faster CSV parsing. PyAirbyte uses DuckDB as default cache. DuckDB-NSQL-7B LLM generates SQL locally.