MotherDuck Integrates with PlanetScale Postgres
2025/12/16 - 8 min read
BYIt’s no longer a hot take to say that PostgreSQL is popular. Everyone knows! A large share of our customers rely on it for low-latency performance across transactional workloads.
One consistent pattern is that as an application scales, so too does the demand for performant, user-facing analytics. Building a next-generation ERP system? You’re going to need aggregations and reporting for your admin users. Scaling up your mobile event-tracking platform? Users will expect real-time filters over everything.
If you're growing quickly, you'll eventually find your analytical queries competing with transactions for the same resources. At that point, you face a familiar choice: double down on Postgres tuning, or accept the complexity of maintaining a separate analytical database along with the application changes to query it.
We don’t think you should have to choose. MotherDuck now integrates with PlanetScale Postgres, the fastest Postgres on, well, the planet. The integration lets you keep your Postgres cluster tuned for millisecond transactional performance while pushing analytical workloads to MotherDuck’s serverless compute while keeping your existing Postgres interface in place.
Benchmarked analytical queries are over 200x faster on MotherDuck versus Postgres alone, and MotherDuck’s serverless architecture means they’re a small fraction of the cost and effort you’d expect if you scaled your Postgres cluster to achieve the same performance.
A duck within an elephant
The integration uses pg_duckdb, an open-source Postgres extension that embeds the DuckDB engine inside a Postgres process. Running locally, pg_duckdb accelerates analytical queries on your existing Postgres server. You can also join Postgres tables with external data, like Iceberg and Delta Lake formats, using DuckDB extensions.
Where the integration really takes flight is when pg_duckdb connects your PlanetScale Postgres cluster to MotherDuck. Pg_duckdb hydrates your Postgres catalog with MotherDuck metadata, then pushes analytical queries to MotherDuck before returning results over the Postgres wire protocol.
The embedded nature of DuckDB is key. While Postgres extensions to other analytical databases exist, query patterns are limited by pushdown support or lack thereof. Complex operations like window functions and CTEs may execute in Postgres rather than the remote analytical engine, consuming CPU and memory allocated for transactional workloads.
Embedding the DuckDB engine inside a Postgres process supports a cross-database query pattern, so you can run complex operations across multiple large tables (e.g. events, sales) in MotherDuck before joining with Postgres tables (e.g. users,accounts).
Consider the following simplified reference architecture. Pg_duckdb is embedded in one of many Postgres processes, where the Postgres query planner routes incoming queries by evaluating the physical location of a given table. Queries against local tables are executed on Postgres, while queries on tables that exist in MotherDuck are routed through pg_duckdb to be executed by MotherDuck remotely. Results are then returned to Postgres, where the remainder of the query joins with Postgres tables (if applicable) before completing.
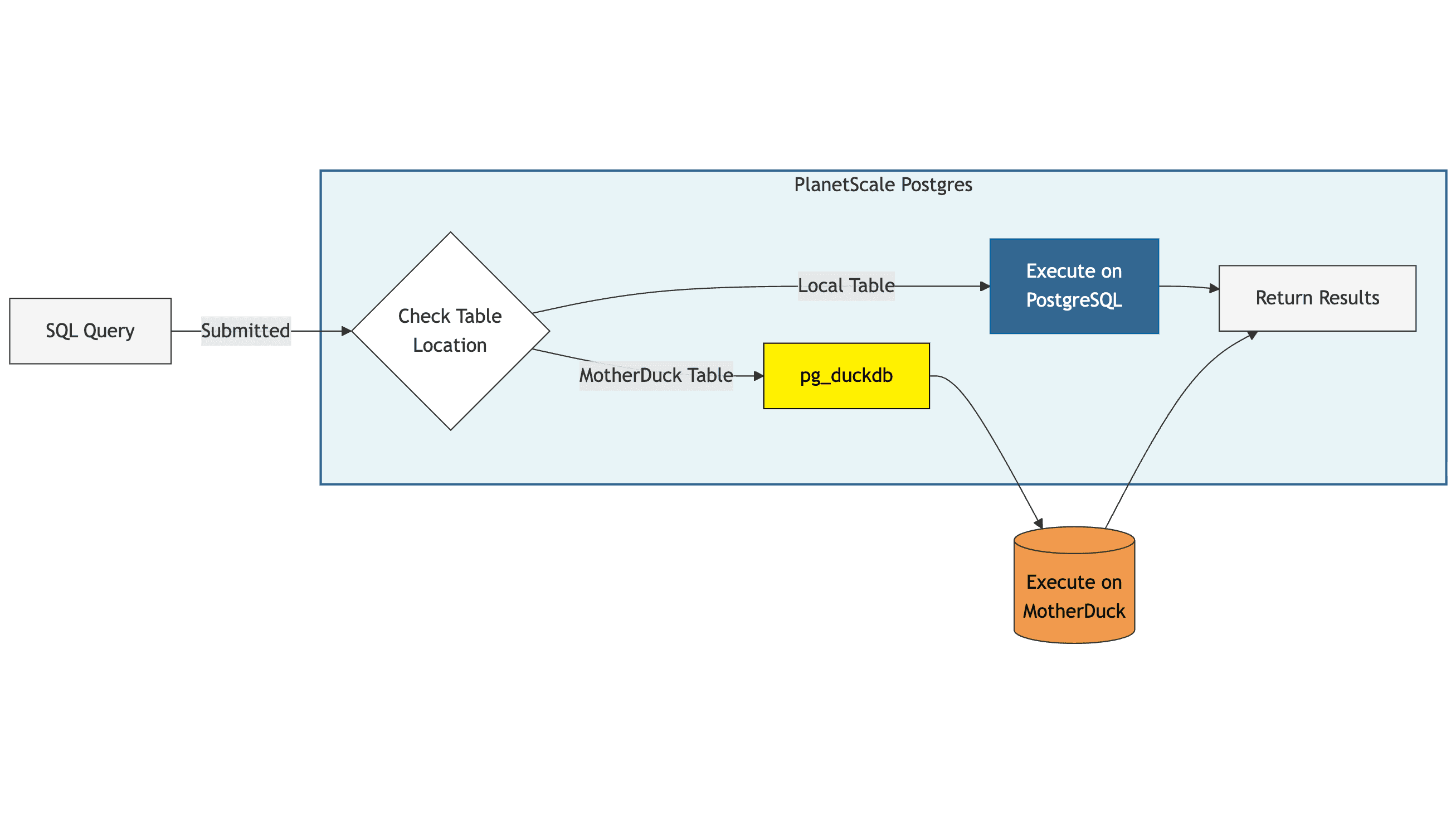
Integrating PlanetScale with MotherDuck for analytics doesn’t require a rearchitecture of your application logic. Connecting to MotherDuck hydrates the Postgres catalog with MotherDuck metadata, so you can query your main MotherDuck schema through your existing public Postgres schema, while utilizing the same queries you’ve already written. Querying across multiple MotherDuck databases is also supported by using ddb$<duckdb_db_name>$<duckdb_schema_name>, see the documentation for reference.
Speed, glorious speed
Speed matters to analytics users, whether you’re serving complex result sets in real-time or a simple reporting dashboard. As a performance test, we compared stock PlanetScale Postgres instances, pg_duckdb running locally, and pg_duckdb plus MotherDuck across the ClickBench and TPC-H analytical benchmarks.
To be clear, this is a bit apples-to-oranges comparison; PlanetScale Postgres is the fastest Postgres across transactional benchmarks, but Postgres wasn’t designed for large-scale analytical workloads. OLAP systems like DuckDB and MotherDuck have a significant advantage in this regard.
We tested across three tiers of PlanetScale instances, from the smallest PS-5 instance at $5 per month(!) to the larger M-320 PlanetScale Metal instance with ultra-fast NVMe drives. Here are the specs:
- PS-5: 1/16 vCPU, 512MB RAM
- PS-80: 1 vCPU, 8GB RAM
- M-320: 4 vCPUs, 32GB RAM
For PS-5 and PS-80, we tested Clickbench queries on 1 and 10 million row datasets, respectively. TPC-H queries at scale factor 10 didn’t complete on these instances in under an hour, so we ran these on the M-320 instance only. We added indexes on all datasets in Postgres as well.
Pg_duckdb uses the same local Postgres resources, so test runs with pg_duckdb as the compute engine have identical specs.
On the MotherDuck side, we tested a representative setup for read-heavy analytical application workloads: two Jumbo ducklings (instances), executing in parallel as a read scaling flock with four threads each.
Comparisons are measured in total execution time; we used Python threadpools for parallelism.
PlanetScale PS-5
At $5 per month, the single-node PS-5 instance is an incredible value. On the 1 million row hits dataset in Clickbench, it ran in 261 seconds using the Postgres engine. Pg_duckdb was actually a tad slower, at 273 seconds (~4% slower). In MotherDuck, the benchmark queries took 11 seconds (96% faster).
While pg_duckdb alone is slower, this isn’t too surprising. DuckDB was designed to run in parallel across many CPUs, and the PS-5 instance includes 1/16th of a vCPU - economical for lightweight OLTP use cases, but not sufficient for speedups with DuckDB.
| Instance | Compute Engine | Execution Mode | Total Time (s) | Delta |
|---|---|---|---|---|
| PS-5 | postgres | 4 parallel | 261.4 | - |
| PS-5 | pg_duckdb | 4 parallel | 272.9 | 4.40% |
| PS-5 | motherduck | 8 parallel (2x jumbo) | 11.29 | -95.68% |
PlanetScale PS-80
Stepping up to the 10 million row hits dataset, the PS-80 instance clocked 1738 seconds via the Postgres engine and 1787 seconds on pg_duckdb (3% slower). Again, not too surprising for pg_duckdb as the PS-80 instance has only 1 vCPU.
MotherDuck completes the benchmark queries in 16 seconds, 99% faster than the Postgres engine.
| Instance | Compute Engine | Execution Mode | Total Time (s) | Delta |
|---|---|---|---|---|
| PS-80 | postgres | 8 parallel | 1738.7 | - |
| PS-80 | pg_duckdb | 4 parallel | 1787.3 | 2.80% |
| PS-80 | motherduck | 8 parallel (2x jumbo) | 16.21 | -99.07% |
PlanetScale M-320
This is where things got interesting, as we could finally run TPC-H at scale factor 10 (10 GB dataset). With 4 vCPU cores on hand, pg_duckdb was significantly faster than Postgres (70% faster), running in 858 seconds.
MotherDuck took only 13 seconds, 99.5% faster than Postgres.
| Instance | Compute Engine | Execution Mode | Total Time (s) | Delta |
|---|---|---|---|---|
| M-320 Metal | postgres | 16 parallel | 2832.2 | - |
| M-320 Metal | pg_duckdb | 8 threads (4 per replica) | 858.3 | -69.69% |
| M-320 Metal | motherduck | 8 parallel (2x jumbo) | 13.05 | -99.54% |
So, pg_duckdb offers some real performance improvements starting with the 4 core M-320. Why not use pg_duckdb on Postgres, add DuckDB’s Iceberg extension, and bootstrap a data warehouse?
There are several major drawbacks here. Concurrency and cost stand out. DuckDB is a multi-threaded analytical engine and will quickly max out CPU when given the chance, functionally restricting you to a single query at a time and introducing replication lag during long-running queries. During testing, our Postgres replica utilization regularly looked like this:
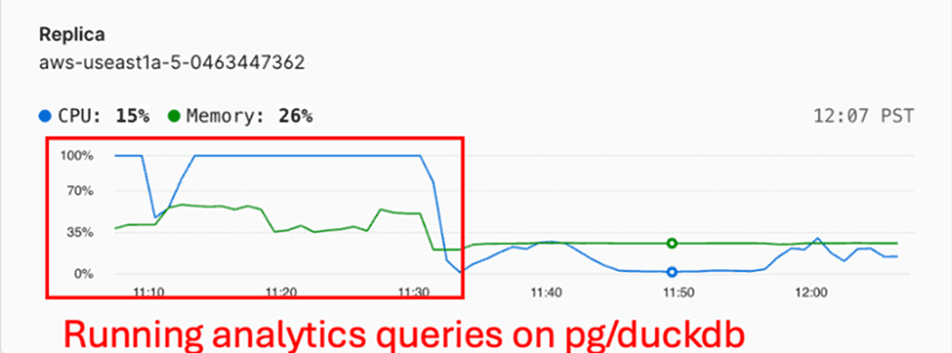
The other concern here is cost. Our testing assumed a fixed cluster size, with benchmark datasets chosen to fit the allocated resources. This isn’t quite how application workloads operate–analytical queries are bursty and larger in scale than their transactional counterparts. PlanetScale Postgres is cost-efficient for transactional performance (you can get a Metal instance for 50 bucks!), but scaling a cluster–accounting for multiple identical replicas– to meet peak analytical load is another tier of cost.
Is this HTAP?
Well, no. But maybe yes? Consider the following query - TPC-H Query 3.
Copy code
SELECT
l.l_orderkey,
SUM(l.l_extendedprice * (1 - l.l_discount)) AS revenue,
o.o_orderdate,
o.o_shippriority
FROM top_tests.customer c -- pg table
JOIN public.tpch_orders_100m o ON c.c_custkey = o.o_custkey -- md table
JOIN public.tpch_lineitem_100m l ON l.l_orderkey = o.o_orderkey -- md table
WHERE
c.c_mktsegment = 'BUILDING'
AND o.o_orderdate < '1995-03-15'
AND l.l_shipdate > '1995-03-15'
GROUP BY l.l_orderkey, o.o_orderdate, o.o_shippriority
ORDER BY revenue DESC, o.o_orderdate
LIMIT 10;
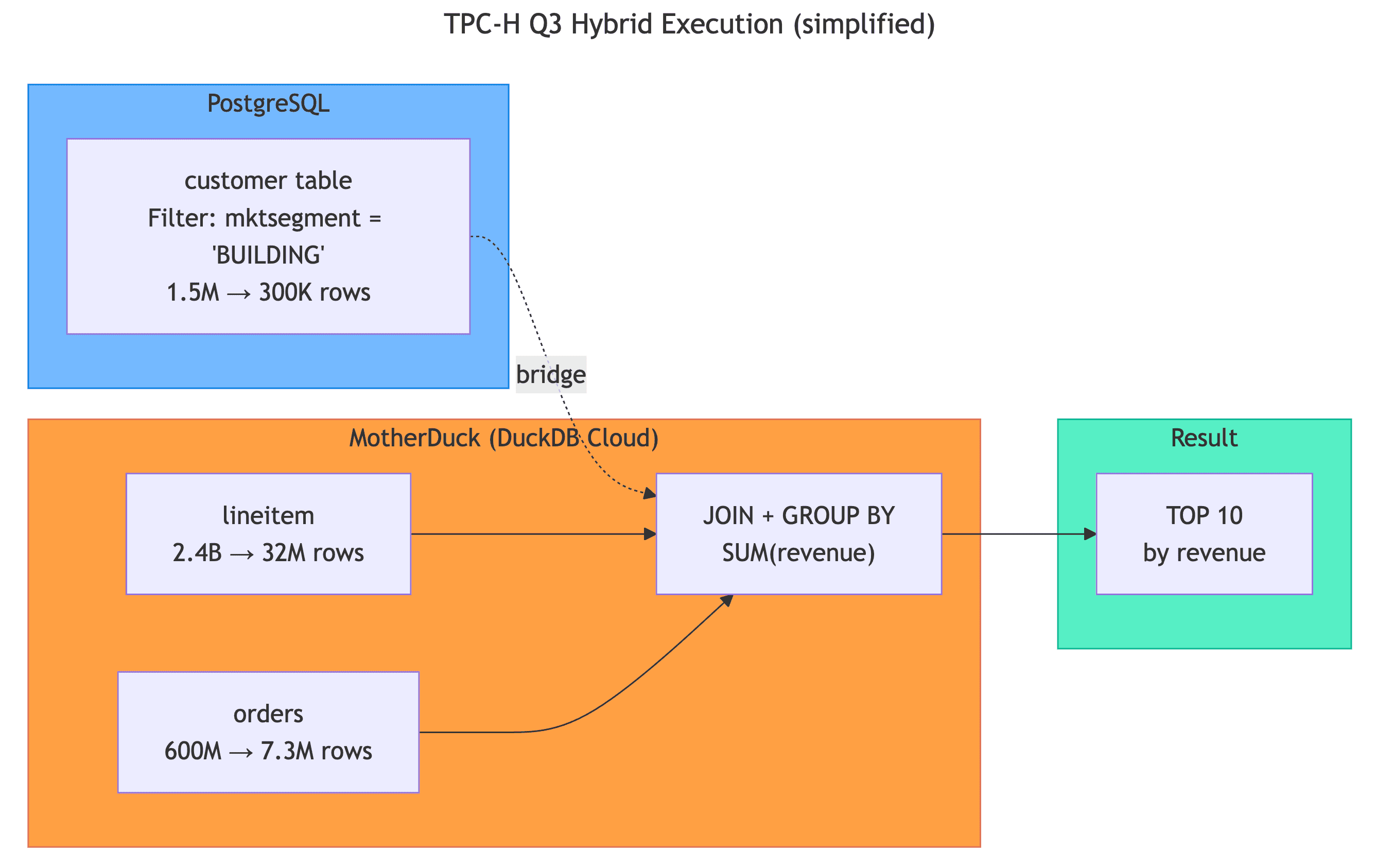
This query finds orders placed before March 15, 1995, that still have line items that hadn't shipped by that date, calculates the total revenue for each order, and ranks them. This is a classic fulfillment prioritization report: if you can only ship 10 orders today, these are the ones that matter most to your bottom line.
Now, let’s look at a simplified query plan. The query planner is smart enough to get the 300k rows it needs from Postgres, load the data into MotherDuck, and then do the rest of the heavy lifting outside your Postgres server before returning the results. Mind. Blown.
DuckScale? PlanetDuck?
Integrating MotherDuck with PlanetScale Postgres feels inevitable, in a way. Developers shouldn't have to accept tradeoffs when building for OLTP and OLAP workloads. With pg_duckdb connecting the fastest Postgres to serverless analytics on MotherDuck, you get the best of both: millisecond transactional performance where it matters, and sub-second analytical queries without maxing out your cluster or your budget.
We’re incredibly excited to let this feature fly, and we’re hard at work cooking up the next round of performance and usability improvements. Read the MotherDuck feature docs and PlanetScale documentation to get started and join our pond in MotherDuck Slack–we’d love to help get you quacking.
Start using MotherDuck now!