
2024/12/11
This Month in the DuckDB Ecosystem: December 2024
DuckDB news: Query Bluesky social data via SQL. LLMs clean CRM data inside queries. Google Sheets extension launches. DuckDB-WASM powers sql-workbench.com browser IDE.
The most celebrated architectural improvement in the first wave of Cloud Data Warehouses was that storage and compute were decoupled. Instead of storing the data on the same machine that was running queries, data was stored in a remote object store. While this may seem like a relatively narrow technical difference, it removed a number of constraints in how systems were run.
When you separate storage and compute, the first, most obvious benefit is that you can now scale compute and storage independently. In the past, the storage to compute ratios were limited by the amount of CPUs and disks you could squeeze into a server (or a small cluster of servers). It was rare that this ratio was exactly right, and if you wanted to change it, you had to buy different hardware and rebalance your data. This becomes even a bigger problem as data accumulates over time, since data tends to grow faster than the need for CPUs. But this can be hard to satisfy in a system that combines storage and compute.
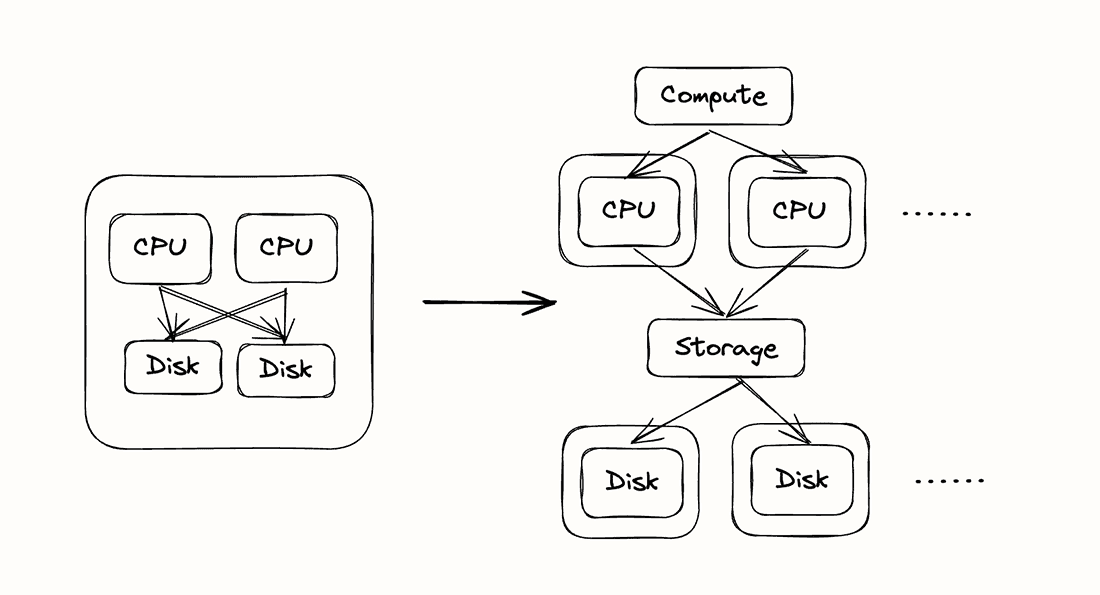
Running in the cloud allows you to to benefit from using elastic services such as containerized compute and object store. If you have very heavy query workloads but not a lot of data, you can spin up additional compute nodes when you need them. And if your data size grows, you can accumulate it in an object store and even if you don't need more compute nodes to handle it. With dynamic resource allocation, we already do not need to provision based on peak usage, but rather as you go. Separating your storage from your compute means that if your compute needs peak, you only need to provision compute. As your storage needs increase, only more storage is needed.
By decoupling storage resources from the compute ones, we can now use specialized hardware. We no longer need to carefully choose the Cloud VM type use, balancing just the right mix of storage capabilities and compute power. We can now use the dedicated storage services, like the inexpensive object storage like S3. These object stores generally have very high throughput by distributing the data across thousands or millions of disks. The resulting bandwidth is thus orders of magnitude higher than more traditional systems where the storage was attached to the compute node running the query. Similarly, we can optimize compute hardware, using GPU heavy VMs for AI workloads, or 256-cores machines for heavy real time analytics.
Using dedicated services for storage also helps with both availability and durability. If your storage is attached to the local instance, you can lose data when a machine crashes. Cloud object stores usually have almost infinite data durability. The disks attached to individual instances are far less durable. And even if you don’t lose data, if a node with attached storage crashes, you’ll have to wait until it restarts before you can query it again, so availability can suffer.
| Local Disk | Object Store | |
|---|---|---|
| Durability | One data loss event / 5 years per disk | 1 data loss event / 1 billion years per object |
| Availability | Lifetime of your VM (99%?) | Availability of storage service (99.999%?) |
| Cost | $$$$ | $ |
The first cloud data warehouse to separate storage and compute was BigQuery, and was outlined in the Dremel paper in 2008. Yes, Jordan is a little bitter about this because Snowflake claimed to have invented it several years later. Of course, as one does, when Jordan mentioned this to some database guru, he was immediately corrected and told that IBM had been separating storage and compute in the ‘80s. So there is really nothing new under the sun.
In practice, separation of storage and compute allowed storage sizes to increase while compute needs grew a lot more slowly. This is one of the key assertions of “Big Data is Dead”: most data is “cold”, and so you might have ten years worth of logs but you only need to provision compute for the “hot” data that you query every day.
MotherDuck is a single-node system, so we don’t need to add additional compute nodes to handle larger queries and don’t have to suffer the overhead of a distributed system typical of Big Data. That said, storage and compute separation is still useful.
First, we do want to be able to scale out to multiple users of the same data. For example, you might want to share data with other people in your company, which is a key feature of MotherDuck . DuckDB, as it is designed for single users, assumes sole ownership of its database file. This only gives you two options: either you copy the data and send it over (looking at you, CSV-over-e-mail), or send everyone to use the same single DuckDB instance. Sharing is caring, but neither seems to be a practical solution. By separating the Storage layer from the DuckDB instances, MotherDuck can share the data through modern zero-copy techniques, while giving each user a dedicated and fast DuckDB instance.
Here is an example to show how separation of storage and storage and compute helps users in MotherDuck.

In this diagram we can see that Alice creates and manages a sales database, under the covers it is stored in two files. She creates a share that can be attached by folks in her team, and they can then use it to query the same data. No copies of the data needed to be made.

Next, we can see that Alice has added data for December, which under the covers gets stored in a separate file (more on that is described below). But she has not yet validated the data, so she doesn’t want it to appear to users and doesn’t update the share that Bob and the rest of the company uses for reporting.

Finally, once Alice completes verification of the data, she updates the share, and the data becomes available to clients, including Bob.
Separating storage allowed us to build a dedicated storage system that allows sharing. In similar fashion, having a separate compute layer gives us the opportunity to get the most of DuckDB’s versatility. We can scale up to give heavy workloads large dedicated nodes. On the other end of the spectrum, DuckDB’s ability to deliver value even in extremely low resource environments (try shell.duckdb.org in your mobile browser) means we can scale down quite low.
DuckDB’s millisecond start up times (together with a shared cache on the storage layer) means that we can scale down to 0 quickly when the service is not used. Cold start is so fast that shutting down instances between queries becomes feasible. As long as you can spin them up again quickly, users won’t be any wiser. At MotherDuck, we aim for the time-to-first query to be less than 200 ms, which is faster than most cloud databases can run a query, and within human reaction time.
There are two main parts to separating storage and compute in DuckDB; first we want to be able to write to a disaggregated storage system in a way that DucKDB can mutate the data. This actually separates the storage from the compute. Second, we want to add synchronization and data sharing mechanisms to allow other DuckDB instances independently read a coherent view of the same data, even while it’s being mutated.
The first part, writing to disaggregated storage is important, because we don’t want to tie the availability of the data to the availability of a particular machine. That means we need to look at one of the ready-made Cloud services or build our own from scratch. External block storage services like EBS have an attractive price but can only be attached to one machine. Distributed file systems like EFS address all the technical needs but tend to be expensive, especially at the scale we’re aiming for. Lastly there are object stores like S3.
If you are building a storage service on top of a cloud object stores like S3; you get a bunch of advantages out of the box. They are able to handle multiple readers, have high throughput, and are inexpensive. However, they have a problem: data in cloud object stores are immutable; that is, once you write a file, you can’t modify it afterwards. This is fundamentally at odds with a database system, like DuckDB that updates data in place.
For databases that use a write-ahead log (WAL), Log Shipping is a common technique for building separation of storage and compute. This means you take the log and replay it somewhere else to generate replicas. However, this doesn’t work with DuckDB, because DuckDB often skips the WAL for batch updates. This is a pretty significant performance optimization for analytics, which often deals with a lot of big updates. If those big updates had to be written to the WAL, it would require duplicating the work as well as bottleneck writes. If we tried to separate storage and compute using log shipping, we would dramatically reduce performance of updates.
Rather than make deep changes to how DuckDB does its writes, we decided to implement separation of storage and compute at a lower level that made changes transparent to the database. We built a Differential Storage engine which sits at the filesystem layer. We built a FUSE-based filesystem that only does appends under the covers, but it makes it look like the data has been updated. To do this, the filesystem keeps track of metadata indicating which blocks are active at a particular time. One of our engineers described it in detail in a blog post here.
To summarize, our differential storage system works by aggregating writes into a single append-only file. We then use a transactional database (currently Postgres), to keep track of metadata like which blocks are live and where to find them. When a block is overwritten, we mark it stale and update the metadata to point to the new location of the data. When DuckDB wants to read a block, all we need to do is resolve what location to read from and then perform a direct read. Since DuckDB always flushes full pages (sized 256KB) this performs pretty well. When writing large blocks of consecutive data it works even better because they can be tracked using ranges rather than individual blocks.
Writing to append-only files has another neat side effect. Since the underlying data is immutable, sharing data and copying files are now just a question of making a copy of the metadata at a specific point in time. There’s no need to copy the underlying data files. They never change. That property allows explaining the name “differential storage”. If two files share common ancestry, the files only have unique reference to the difference between them while sharing the common data.
Last, when an append only file is no longer, a garbage collection process can clean them up. Similarly, we run other maintenance processes, like compaction, to keep the metadata nice and tight.
One of the big advantages of the differential storage system is that it allows someone to read a consistent view of the data even while it is being changed; you just need to look at the metadata as it was at a particular time. We already hinted before that that’s how we do zero-copy and sharing. However it has some other nice side effects. If you’re familiar with functional programming and immutable data structures, using immutable trees is a great way to provide writes and reads concurrently without having to use locks. We’re effectively doing the same thing with on-disk persistent data; the metadata mapping which file ranges are active is effectively an on-disk version of Okasaki’s immutable trees.
Many data tasks involve teams of multiple people; data engineers load and transform the data, analysts and data scientists dig for insights, business users interact with dashboards. Some sort of data sharing is required in order to allow these tasks to flow smoothly. However, DuckDB is an in-process, single-user analytical database, without a concept of users or access control. If you want to use DuckDB in a collaborative setting, you need to figure out how to make it easy to collaborate.
MotherDuck was founded on the idea that you can scale up a single node to handle virtually any workload; however, when you have lots of people using the system, a single node solution may not be able to handle all of their workloads at the same time. So in adapting DuckDB to run in the cloud, we decided to scale it out in a different way; every user gets their own DuckDB instance. This way we don’t have to force the concept of users inside DuckDB, and each user would be able to take advantage of the full power of their own DuckDB instance.
In order to allow different users, each of whom has their own DuckDB instance, to share the same data, we push much of the work of collaboration to the storage layer. We rely on our differential storage engine to give a point in time consistent snapshot of any database. We ensure that each reader of a database sees a “clean” view of the database, allowing us to work around limitations in DuckDB regarding simultaneous readers and writers. Each user can scale up or down to the size of their workload in isolation from other users, while allowing access to data created by other users.
MotherDuck treats all databases as private by default. That is, when you create a database, no one else can access it until you deliberately share it; that is, you create a share. Shares in MotherDuck operate very much like Google Docs; you can choose to share via URL, which means that anyone with the link can access it. You can also share with your organization, which means that anyone in your org with the link can access it. Users can also browse organization-wide shares and discover them on their own. You can also share just with specific users.
There are still some restrictions that remain; in MotherDuck, only one user can have write access to a database. We’ve solved the reading while writing part, but the multiple writer problem remains. This does somewhat limit what kinds of writes you can do, but in practice, very few workloads require simultaneous writes from different users. Generally the model that we tend to see is that data ingestion and transformation is done by a shared service account, whereas reading can be done by lots of different users. It is also often the case that data writes are to separate data universes, so these can be cleanly split between service accounts, giving more write throughput. That data can be then shared with multiple users and combined using DuckDB’s multi-database support. All of these are made possible with the MotherDuck access model.
There is a further caveat; in order to give readers in other instances a clean snapshot of the data, they might not be able to see the up-to-the-moment changes that are being written by the owner of the database. If you create a share with the AUTOUPDATE flag, any changes will be published to readers of the share as soon as possible. However, there can be a small delay before readers see changes.
Sometimes a delay between changes being written and being visible to readers is useful. The writer may be making a handful of changes that they want to appear together. Imagine a pipeline that updates a number of tables and then runs unit tests; they only want to publish the results after the unit tests pass. In this case, they’d create the share as a non-auto-update share, and then call the UPDATE SHARE command when the changes are ready to be published. Once the UPDATE SHARE runs, all changes will be immediately available to readers.
Today, MotherDuck supports two modes for users to publish changes to the data they have shared. In the first mode, a user can explicitly commit changes to be able to be seen in the share (via the UPDATE SHARE SQL command). This gives users control but also requires explicit commands. Alternatively, users can have the shares be eventually consistent, having to wait until a periodic checkpoint operation occurs. This can create some delay if you rely on readers being able to see up-to-the-moment data. We are working to reduce this gap, and will be introducing upper bounds guarantees to how long it takes to publish the data.
Future work in MotherDuck will allow multi-writer by routing writes to a single backend. That is, even if DuckDB doesn’t allow multiple writers, MotherDuck can simulate it by routing updates from multiple different users to the same instance. On the read side, we can do something similar by using a scalable snapshot but also reading deltas from a live instance and directly applying it to another. This would allow us to avoid the heavy flushing and reload of memory on close and reopen of the database.
Additionally, the immutable nature of the underlying storage makes it easy to add support for features like time travel and branching. We will likely be adding those features soon. We will also be doing more work on providing caching to provide faster ‘warm start’ access to data.
Separation of storage and compute is useful for more than just being able handle larger datasets; it also helps you decouple workloads from physical machines and enables new data architectures. Retrofitting Separation of Storage and compute on a database that wasn’t designed for it can be tricky, but also can deliver a ton of benefits.
MotherDuck is standing on the shoulders of giant ducks, namely the DuckDB team, and they move and grow very quickly. We work very hard to keep up with them, and to continue to push the limits of what DuckDB can do.
2024/12/11
DuckDB news: Query Bluesky social data via SQL. LLMs clean CRM data inside queries. Google Sheets extension launches. DuckDB-WASM powers sql-workbench.com browser IDE.

2024/12/12 - Adithya Krishnan
Leveraging LLM workflow in your data pipelines