The data warehouse that helps you fly faster
Dual execution with local processing and cloud scale
Give power back to analysts
Say goodbye to competing for central resources and knocking elbows with your teammates and their huge transformation jobs. With the efficiency of DuckDB, the data warehouse is finally personal, with user-level configuration and plenty of room to stretch your wings.

Each user gets their own compute instance “duckling”
MotherDuck’s per-user tenancy model enables teams to configure each org member individually. By default, each user in an Organization, or team, has their own dedicated, serverless isolated runtime. CPU visibility is provided per-user for simple, straightforward cost attribution and usage auditing.

Push work down to the client
MotherDuck turns users’ laptops into local, easy-to-use execution nodes. DuckDB’s unique portability enables teams to work locally and in the cloud with the same database. Since queries process closer to where data is stored, local compute is saved for analytical processing.

Boost productivity
MotherDuck’s features and UI are designed with data teams in mind. From taking in a birds’-eye view of your data with Column Explorer, to writing SQL queries with FixIt, our notebook-like interface ensures your data explorations are smooth sailing, and we’re constantly making improvements to keep you in the flow.

AI-enabled UI and workflows
As the primary work surface for many analysts, our mission is to make MotherDuck’s UI your preferred place to quickly hone in on the data that matters. Stay focused on getting answers quickly and editing complex SQL queries auto-magically with FixIt. Alternatively, use the Column Explorer’s automated sparklines and summary stats to hone your analysis. Once added to your data toolkit, we think you’ll take to it like a duck to water.

Versatile SQL and Python Support
MotherDuck builds on DuckDB’s portable nature and allows you to integrate it directly into your data analysis workflows. With comprehensive support for enhanced and traditional SQL, users do not have to compromise on query readability, even in a Python environment. You can even run Python scripts and Jupyter notebooks or transfer data between DuckDB and pandas dataframes. For additional flexibility, DuckDB also has a dataframe-style API, giving SQL and Python users something to quack about.

Backed by the modern duck stack
MotherDuck complements and integrates with your existing data stack. Thanks to DuckDB’s momentum, our flock of partners is ready to ensure your analytics workflows take flight with local and remote queries. Many of our partners already support DuckDB, and some even use it in their core product as a cache or batch processing engine. For DuckDB users, getting started is as easy as executing ‘.open md:’ in the CLI.

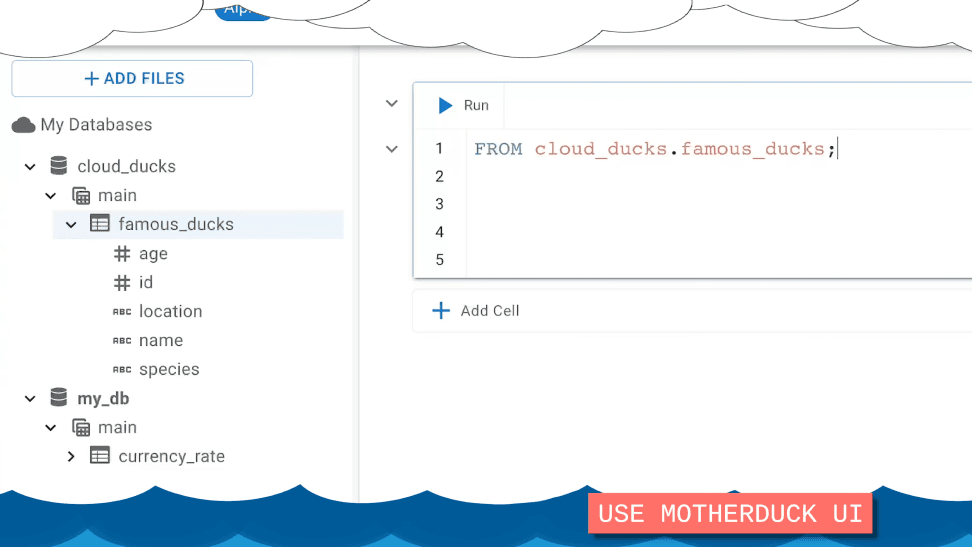
MotherDuck UI
See it in action!
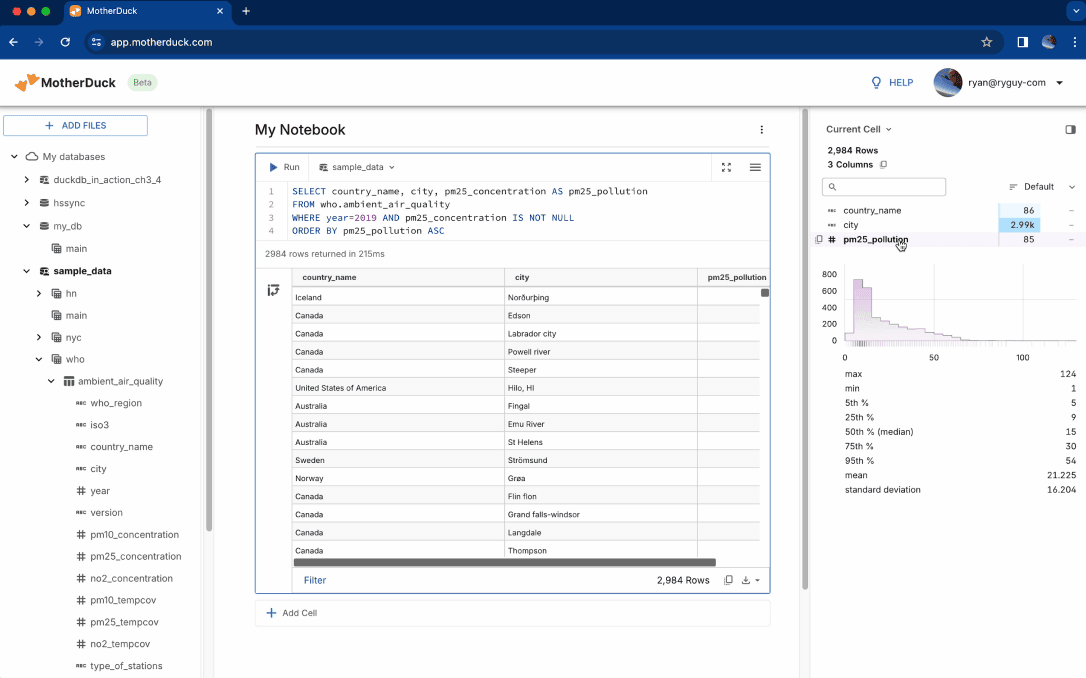
Query, Upload, share
Join MotherDuck Co-founder, Ryan Boyd, for a tour of the MotherDuck UI and see how you can:
- Query data from the public_data share
- Get a bird’s eye view of your data with the Column Explorer, and see how result sets are stored in DuckDB running in the browser to enable faster filtering and pivoting
- Upload data from the local machine to MotherDuck
- Write basic analytic queries and use FixIt to catch SQL syntax errors
- Share uploaded data with colleagues
Not just for small data
MotherDuck takes advantage of DuckDB’s portable, embeddable architecture to deliver analytics virtually anywhere. While DuckDB is best known for its efficiency and suitability for small datasets and in-memory processing, it is powerful enough to efficiently handle a wide range of data sizes and types. Customers are using MotherDuck with many terabytes of data to streamline their workflow and maintain high performance.

DuckDB’s feather-light Efficiency Punches above its weight
MotherDuck is built on DuckDB’s highly performant architecture, designed for analytical workloads where low latency query performance is crucial. Data is stored in a columnar, vectorized format that streamlines query execution and uses CPU and memory more efficiently for analytics than any transactional database.

Unique architecture handles large scale
Your laptop isn’t just a dumb terminal. It’s as fast, or faster, than a state-of-the-art cloud data warehouse. MotherDuck’s unique architecture takes advantage of this untapped and rapidly improving processing power at your fingertips with a dual execution query engine. By making full use of advances in hardware and network speeds to reclaim unused compute on users’ local machines, MotherDuck routes each stage of query processing to the optimal location across your local machine, the cloud, or by splitting a single query across both where needed before combining and returning end results to the user.

Features





Architecture
Managed DuckDB-in-the-cloud
Ecosystem
Modern Duck Stack





























