
Hazel built an AI co-worker for consumer brands on MotherDuck — a hypertenant data stack where dbt models in a central warehouse fan out to isolated per-customer databases, powering an agent that answers business questions end to end.
Hazel is an AI co-worker purpose-built for consumer brands. Instead of hiring a data team, consumer brands connect their various data sources and get Hazel — an agent that ingests their data, builds their warehouse, and answers business questions with charts, deep analysis, and modern tools. MotherDuck powers the analytical backend: a central multi-tenant warehouse, hypertenant individual databases, and the query engine behind every answer Hazel delivers.
- Full data stack as a service — ingestion, transformation, and analytics powered by MotherDuck + dbt + Dagster
- Hundreds of dbt models running on a central warehouse, fanning out to isolated per-customer databases
- Small team shipping a production AI analytics platform, launched January 2026
- Local DuckDB for dev, MotherDuck for prod — enabling rapid iteration on integrations and data models
"I think the thing that people underestimate is how much data DuckDB and MotherDuck can handle. The gut instinct may be like, I need a BigQuery, I need a Snowflake. But a lot of people would be surprised at how much can fit into these in-process OLAP engines."
From LTV Predictions to AI Co-Worker
Patrik Devlin and co-founder Clint Dunn started Hazel as a data-science-in-a-box product focused on lifetime value predictions for e-commerce brands. They'd plug into a customer's warehouse, run models, and send results back. Soon enough, a bigger opportunity revealed itself.
"We felt like we weren't solving a big enough problem for folks," Patrik explains. The pivot: build an AI agent that acts as a full co-worker — not just a model, but a teammate that understands your business data end to end.
Today, Hazel sits on top of a unified data layer and works as a data analyst. Hazel answers questions about revenue trends, investigates why marketing spend spiked, identifies anomalies, and produces visualizations — all grounded in the customer's actual data across every integration they've connected.
Why MotherDuck
The team started with DuckDB locally and loved the speed of iteration. But when they moved to production, they hit the concurrent writers limitation — multiple services needed to write to the same database simultaneously, and local DuckDB couldn't support that in a cloud environment.
"We couldn't make it work in a production cloud environment," Patrik recalls. "Just being able to handle concurrent writers was important."
MotherDuck solved that while preserving everything they loved about DuckDB. The team still runs DuckDB locally for development — especially for iterating on their dbt stack — and deploys to MotherDuck for production.
"The biggest win from using DuckDB locally has been speed of iteration on our dbt stack. Even our CEO Clint, he's a data guy by trade, so he's in there as well. It's really a velocity thing."
The Duck Stack
Hazel's architecture starts with integrations. Consumer brands typically anchor on Shopify, then layer on marketing platforms, web analytics, and other tools. Hazel pulls data from these sources using a mix of homegrown ingestion and Fivetran, with DLT handling additional data jobs.
- Data Lake: Raw data lands in S3 as Parquet files
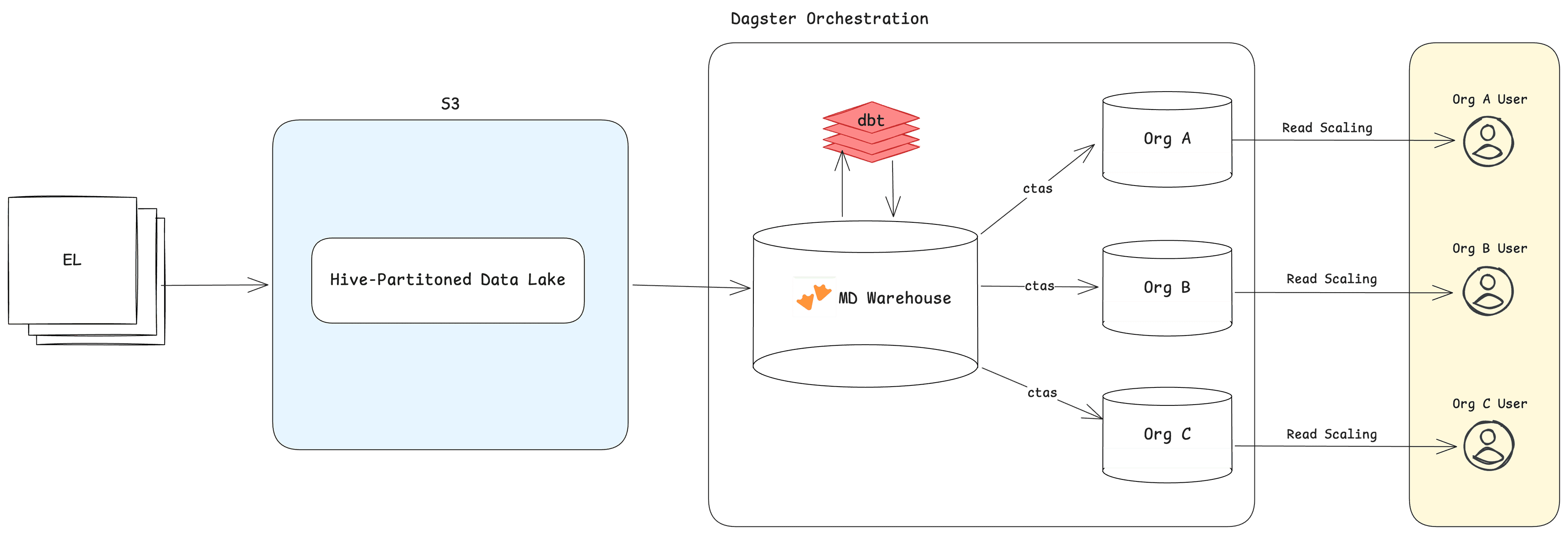
- Central Warehouse: MotherDuck sits on top of S3. Dagster orchestrates hundreds of dbt models that transform raw data into analytics-ready tables
- Hypertenant Customer Databases: CTAS statements push transformed data from the central warehouse into isolated customer databases, filtered by organization, maintaining a high level of security and reducing any chance of cross-pollination
- Agent Layer: Hazel connects to each customer's read replica and queries their data to answer questions, generate charts, and surface insights
Letting the Models Drive
Hazel's data philosophy is decidedly future-forward. Rather than building elaborate transformation layers to normalize every edge case, they push more raw data through to the customer-facing layer and let the AI agent reason over schema differences.
"Our stance is: let's expose as much of the raw information as we can and let the models do the work. This leads to much more interesting analysis vs. trying to predict an endless number of possibilities."
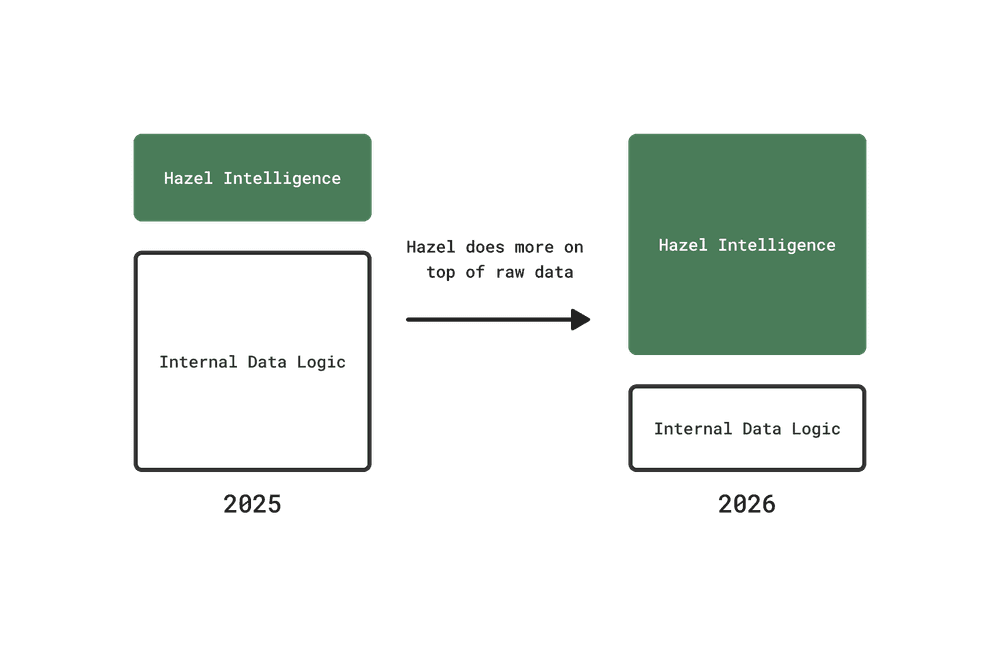
Patrik sees this as the future of data engineering for AI-native products. As LLMs get smarter, Hazel can shift the balance between internal data logic and AI-driven intelligence for each customer. Today, a significant share of the work goes into transforming and structuring data before the agent sees it. Over time, Hazel expects to push more raw data directly to the AI layer — letting the model handle interpretation that transformation pipelines used to own.
"The amount of data manipulation and transformation we have to do is going to decrease because the models themselves are getting better over time."
CTAS: Low-Tech, High-Impact
The mechanism for moving data from the central warehouse to per-customer databases is refreshingly simple: CREATE OR REPLACE TABLE AS SELECT with a WHERE clause on the organization ID, orchestrated by Dagster on a refresh cadence.
"You'd be surprised — the create table or replace is one of the best tools DuckDB and MotherDuck has provided. It allows us to just shift data around so seamlessly."
The team also uses CTAS combined with MotherDuck shares for third-party data enrichment workflows — isolating data for an external vendor, letting them enrich it, and piping the results back into the warehouse.
What's Next
Hazel is exploring DuckLake and Iceberg to improve their data lake layer, particularly around small Parquet file compaction.
"MotherDuck gives us the compute power of DuckDB, scaled up into a production-grade platform. It makes it simple to iterate while solving for the concurrent writes limitation of local DuckDB." — Patrik Devlin, Co-Founder & CTO