2026/06/10 - Doo Shim, Miguel Miranda
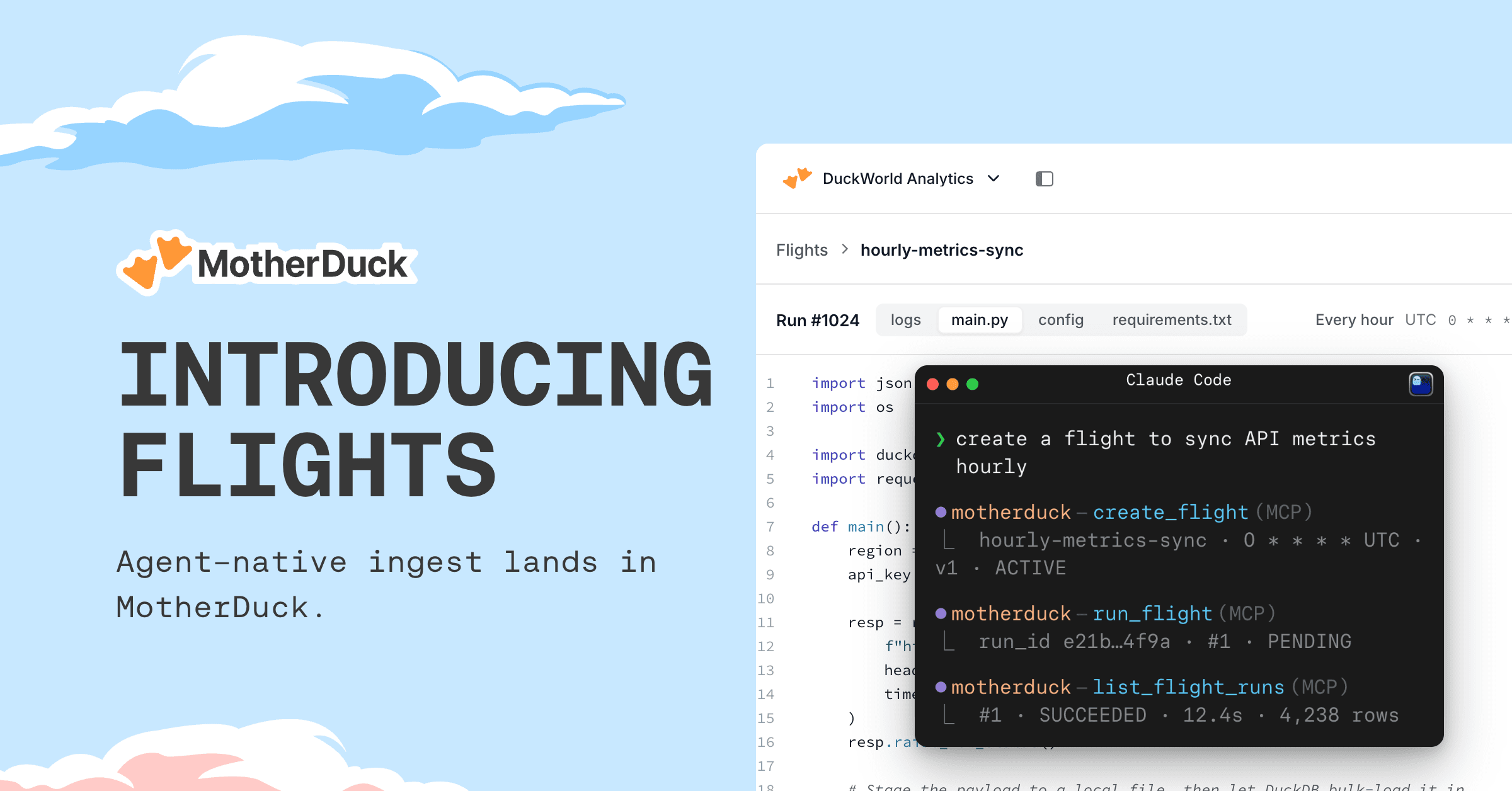
Introducing Flights: Agent-Native Ingest in MotherDuck
Build, deploy, and schedule Python data pipelines from a prompt, a SQL function, or the MotherDuck UI.
Announcing Data Outpost - The conference for data people in a world being rebuilt by AINov 4-5 | San Francisco
When we first launched Dives in February, everyone at MotherDuck expected it to be a useful tool for ad-hoc data analysis, but not up to the task of a fully-featured dashboarding solution. Many of us have deep experience working at BI companies and were intimately familiar with the complexity of those products. We were all surprised when, only three months later, it became a full replacement for our own BI tool. Our BI tool had 90% of the company as weekly active users, with hundreds of active dashboards. A year ago I would have estimated such a migration to take at minimum six months of full-time focus from at least three people. Fast forward to May of 2026, and it ended up being a part-time project that a couple of people completed in less than a month. In this post, I'll walk through our thought process going into the decision, describe the technical details of the migration itself, and offer some thoughts on what this means for the future of software and SaaS.
Our internal usage of Dives took off immediately after launch. Some of the most insightful and valuable Dives were built by salespeople with limited technical background: our top two Dive builders had never once built a dashboard in our legacy BI tool. That was a signal we'd unlocked something significant.
We started off thinking that Dives would mostly be for ad-hoc analysis, but a few engineers quickly added structure that made them suitable for business-critical reporting. Because Dives are just React and SQL, we could manage them like any other codebase: a GitHub repository called "Blessed Dives" gave us source control, a lightning-fast local development loop with Claude Code, and GitHub Actions for deploying changes to the entire company. Company-critical dives with vetted numbers use this toolset, while non-technical users are still able to create lightweight ad-hoc Dives simply by chatting directly with Claude. Internal usage grew incredibly quickly, with the entire company dog-fooding it, and every person reporting that they preferred the Dives authoring experience over the existing BI tool.
Early on, I was skeptical that we could fully replace our BI tool. It was a mature product built by a talented team, and I suspected there were many features we relied on without realizing it, but seeing the creativity and productivity Dives unlocked across the team convinced me. Even if we didn't reach full feature parity, the upside would far outweigh the downsides. We were also hearing from many of our early-adopter customers that after experiencing Dives, they were also considering reducing or fully eliminating their BI spend.
Once we made the decision to migrate, the next step was mapping the mission-critical jobs our BI tool handled and figuring out where Dives fell short. The gap list from our initial launch included URL-encoded shareable Dive state, usage statistics, and scheduled delivery of reports via Slack. This list aligned nicely with the most commonly requested features we heard from our customers, which made prioritization easy. Within a few weeks our engineering team shipped fixes for the hard blockers, and we implemented workarounds for everything else. Seeing this velocity gave us even more confidence that the migration would not only be feasible, but would probably happen even faster than we'd anticipated.
Creating new things is fun and exciting. Migrating existing dashboards to a new system is slow and tedious, requiring extreme attention to detail while tracking down minute differences in key metrics. This turns out to be the perfect application for AI agents, because an old dashboard can be used as ground truth. An agent can iterate on creating a specific query and visualization until either the numbers match exactly, or it can prove that the old dashboard was wrong.
To accomplish this, we built a simple system: a high-level orchestration agent responsible for overall dashboard creation, and sub-agents responsible for recreating individual tiles. Dashboard tiles are mostly independent, which let us parallelize the work and keep each sub-agent's context narrowly scoped to the tile it owned.
To migrate a single dashboard, we gave the top-level agent the dashboard URL, read-only API access to the BI platform, and access to a Chrome MCP integration.
We iterated on this process over a period of a few days, using one of our more complex dashboards as a test case. Once the workflow was reliable enough on the test case, we triggered it for all our critical dashboards. While a handful needed someone to step in and resolve issues the agent couldn't handle on its own, the vast majority came back ready to use without any human intervention.
Our most complex dashboard is our internal Customer 360. It contains both high-level and detailed drill-down information about the current state of a MotherDuck customer, pulling data from every one of our business and production systems. To migrate this dashboard, the workflow above ran for about an hour, spawned 32 sub-agents, and consumed about $75 of Claude Sonnet 4.6 usage: ~150M cache read tokens, ~5M cache write tokens, ~50k input tokens, and ~500k output tokens. The cost was dominated by cache reads, which is a fairly typical pattern of agentic loops, where the same context gets referenced repeatedly.
In total, our BI deployment had hundreds of dashboards, many of which were no longer used. We migrated 45 in total, most considerably simpler than our Customer 360, averaging ~$40 of Sonnet 4.6 consumption each. I estimate we spent around $2,500 in Claude API credits across the migration.
For any labor-intensive project, the biggest cost is human time. At our scale, I estimate that a BI platform migration in the pre-agentic AI era would have taken three full-time employees around six months to complete, for a total cost likely north of $500K. With the help of Claude Code, this turned into a part-time project for a few people over the course of a month. Easily 15-20x cheaper in labor terms.
The cost savings and velocity were striking, but my biggest takeaway thus far is what this exercise implies about an entire category of software. At MotherDuck, we're saving roughly $35K annually on software licensing fees for a BI tool that previously felt indispensable. This feels like a sign that certain products are far less durable than they used to be – specifically, low and no-code tools that give human users abstractions for quickly building digital interfaces. These abstractions provide leverage, allowing non-engineers to build things they otherwise couldn't, but now that AI agents can write the underlying code directly, those same abstractions have become dead weight. The cost of code has dropped by several orders of magnitude, and this category is stuck in no-man's-land, restricting the flexibility of its output while optimizing for a constraint that no longer exists. The flip side is that an enormous amount of work just became economically viable. Lots of internal tools and migrations that used to require a major commitment now fit into a side project. Watching this play out in real time inside MotherDuck has been a strange and exhilarating experience, and I can't help but wonder: what category is next?
2026/06/10 - Doo Shim, Miguel Miranda
Build, deploy, and schedule Python data pipelines from a prompt, a SQL function, or the MotherDuck UI.

2026/06/12 - Simon Späti
The June 2026 DuckDB Ecosystem Newsletter: a local-first ETL/ELT studio, the Quack client-server protocol and its OAuth layer, DuckLake inlining, DuckDB internals, MotherDuck Flights for agent-native ingest, plus a community spotlight on Ryan Dolley.