Stop guessing whether your AI analytics stack works.
Run your first eval this week.
Free PDF. 7-step eval playbook. Works on any warehouse.
The eval in action
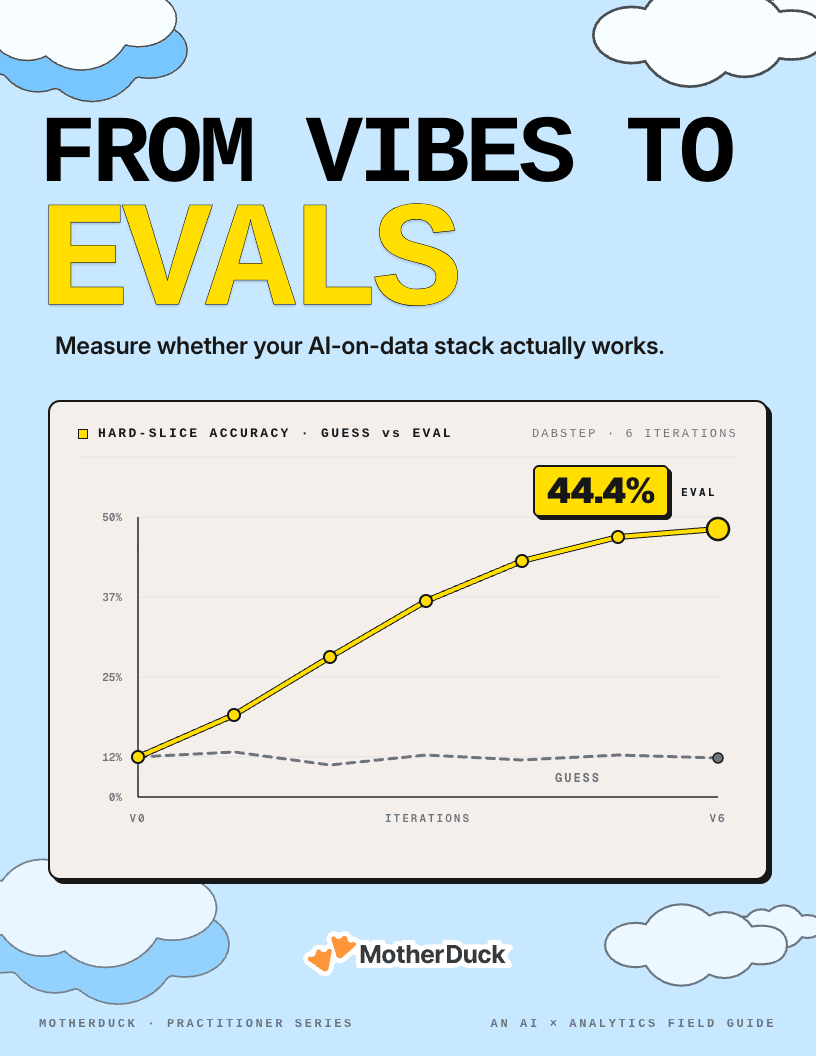
We ran the playbook against a public benchmark. Same questions, same agent, one schema change. The lift held across four model families without retuning.
7 steps
A complete eval playbook for AI-on-data.
3 dimensions
Accuracy, speed, and cost — measured together.
4 models
Lift held across four model families.
−$30
Cost savings on Opus, with higher accuracy.
You don’t need a better opinion about your AI analytics strategy. You need a way to measure whether it works.
The answers keep coming — semantic layers, RAG, MCP, agents writing SQL. Some are good. Some are expensive theater. Most are impossible to judge from a demo, because the demo isn’t running against your data.
This guide is the eval framework. How to run controlled experiments on your own warehouse, what to measure, where the traps are, and how to turn results into something you can keep improving.
What most teams get wrong
Batching Changes
Five changes in one test means a number you can’t explain. One change per eval run.
Stale Context
More context helps — until it disagrees with your schema. Then it actively hurts. We tested this and the result flipped on us.
Time Drift
Baseline today, intervention three weeks later. The model provider ships a snapshot between them. Now you’re measuring two moving targets.
Swapping the Model First
Model swaps are cheap. Recipe wins compound across model generations. Fix the recipe first.
What’s inside the guide
An eval playbook, a worked example, and a Monday checklist.
The playbook
Seven steps. The first six get you to a real lift number. The seventh keeps it improving.
Build the question set
Start with 20–30 questions from someone who knows the business. Keep train and held-out separate. Coverage matters more than count.
Stabilize your data
The data has to hold still across re-runs. Version the held-out set alongside the harness.
Define the baseline
Run the held-out set against your current setup. Log accuracy, speed, and cost per question.
Apply the lever
Pick one variable. Fork the data, apply the change, re-run. Only the lever moves.
Train the lever
Read failures, propose fixes, re-run on the train set. Stop when improvement plateaus, then score the held-out set once.
Iterate the recipe, not the model
Recipe changes compound across model generations. Model swaps don’t. Fix the recipe first.
Close the outer loop
Ship with telemetry. Mine production traces for new eval questions. Re-train when the score drifts.
Get the guide
Enter your details and we’ll send you the complete guide as a free PDF.
Get the guide

Thanks for requesting the guide - you'll be taken there shortly! Redirecting you—One sec