There's so much going on in the AI space, and how to work with AI agents is changing every day. Everyone is overwhelmed and almost numb from so many possibilities, yet you need to find a way to work with AI, not to get left behind, right?
You might use AI agents all day long, parallelizing them with AI orchestrators like Agent Teams, Gastown, tmux, git worktree, and AI-based IDEs, but in the end, you just coordinated an AI. You still have to learn what it created, understand it, check for hallucinations, and verify that it built the right thing. We've all become senior reviewers, more exhausted than before, with less of the work that made this fun in the first place. Meanwhile, we are also more distracted than ever. No time to think, with Copilot, Grammarly, or something else constantly asking and suggesting.
This series interviews real practitioners to give you the best tips on how they use AI in their data work today, extracting as many patterns behind them as possible. The article is structured in four parts: (1) how Mark is using AI, (2) what he has learned working with it, (3) what he is specifically using it for, and (4) what he thinks about AI in general and the future.
Introducing the Guest: #1 Mark Freeman
The start of this series is none other than Mark Freeman. He is currently the Head of DevRel, Employee 1 and GTM at Gable. Mark has gone through three career roles as clinical researcher, data scientist, and data engineer, which is helping him greatly in his current position to navigate the unknown of generative AI. We'll go more into it later.
Mark has also co-authored a book with O'Reilly about Data Contracts (with Chad Sanderson and B.E. Schmidt), and is helping build Gable with the best possible data flows and data quality for enterprises.
INFO: TLDR
To set the stage, in this interview we talk about how to use Spec-Driven Development workflow with Claude Code and agent teams to produce high-quality, reproducible outcomes. We cover Mark's use of ExcaliDraw diagrams and JSON schemas to define requirements upfront, how he parallelizes agents with tmux to compare outputs, why AI benefits senior engineers more than juniors, and where he sees data engineering heading.
How Mark's Using AI
Let's start with the general setup Mark uses when working with AI, and how he uses generative AI.
How Mark Changed His AI Workflows
I asked him: "Since you're building a company in the data contract and quality space and have written a book, how has working with AI changed how you use AI at work?"
Mark has been in the data space since 2018 as a clinical research analyst and a data scientist since 2019. In 2022 he shifted over to data engineering, and in 2023 joined Gable to solve the problem of applying data contracts. He was very early in NLP with the major ML project he worked on back in 2021.
He remembers the early days in 2023 when ChatGPT hallucinated and when he used generative AI for the first time. Very much as a chat window co-coding companion, asking them architecture questions and general questions about the code at hand. Fast forward to 2024 and 2025, generating more code, but not full programs and projects, but by function - trying to narrow down the scope.
And then in late 2025, Claude Code came around, and changed the game with better models that could autonomously solve problems for a longer period. And at the same time, everyone provided more CLIs to empower the CLI-first workflow of Claude. Mark started building by giving it instructions, pointers to docs, schema, etc., and letting it independently build data-related work and go fully agentic.
Mark's Spec Driven Workflow
Mark has figured out a very well-working approach that helps him create reproducible outcomes. Not focusing on solutions, but on how the tool works as he relentlessly specs and defines what he wants with the Spec Driven Development (SDD) approach, inspired by Esco Obong and how he used it at Airbnb. He uses the GitHub-provided spec-kit, which is a toolkit to help you get started with Spec-Driven Development.
I hadn't heard of it, and when checking it out, it's super well documented and integrates 1:1 into Claude Code (and many other AI agents), meaning you can use slash commands within Claude and define specs with the help of an existing git repo including docs and code such as:
/speckit.plan: Execute the implementation planning workflow using the plan template to generate design artifacts.
/speckit.tasks: Generate an actionable, dependency-ordered tasks.md for the feature based on available design artifacts.
/speckit.specify: Create or update the feature specification from a natural language feature description.
/speckit.analyze: Perform a non-destructive cross-artifact consistency and quality analysis across spec.md, plan.md, and tasks.md after task generation.
/speckit.clarify: Identify underspecified areas in the current feature spec by asking up to 5 highly targeted clarification questions and encoding answers back into the spec.
/speckit.checklist: Generate a custom checklist for the current feature based on user requirements.
You can define these on a per-project basis, or have some of them defined as a general spec in your ~/.claude/ folder. The outcomes are Markdown files that hold dedicated specifications, based on your goals that can then be further edited and updated based on your iterations.
Working Product-Focused
This helps Mark to focus on product scenarios and predictable outcomes instead of vibe coding every piece from describing his principles from scratch, he continues.
He goes from ideation through specs to dedicated tasks. He likes to always start with an ExcaliDraw diagram, defining more of the flow diagram, rather than architecture or other overviews. For data schema and interface definitions, he defines data structure next to the relevant flow diagram, as ExcaliDraw is JSON, these can be easily integrated. Schema definitions describe accurately what's needed based on stakeholder discussions and his needed requirements.
He then passes that diagram back to Claude Code and iterates on the data model and his key assumptions. Mark takes a lot of time in this process. He will spend hours, days or even weeks in this stage, updating and refining these specs, specifically giving clear and exact information about data schema, tools to use, and architectural choices that he knows as a senior engineer that he wants and needs to have.
This is also where years of experience make the difference.
Using TypeScript for Data Schema Enforcement
An interesting discovery Mark made is that he started using a programming language new to him, TypeScript. Similar to Wes McKinney's From Human Ergonomics to Agent Ergonomics, where he states that "Python Was Built for Humans, Not Agents" and argues that he is using GoLang and Rust for agent work, as it's a better language for agents with minimal dependencies and shorter/better types.
Mark ended up using lots of TypeScript, not because he was familiar with the language, but because it's mostly what his work and that of a data engineer requires: defining data types. Enforcing them, quickly verifying across the data pipeline that we don't get an error before pipeline runtime. Saving a lot of time and upping the quality.
What Mark Has Learned Working with AI
Over the years, Mark has changed his workflow. In this part, he shows how he uses agentic agents with tmux and how he reviews and checks the outcome.
Agent Parallelization and Executing Them: Teams and Tmux
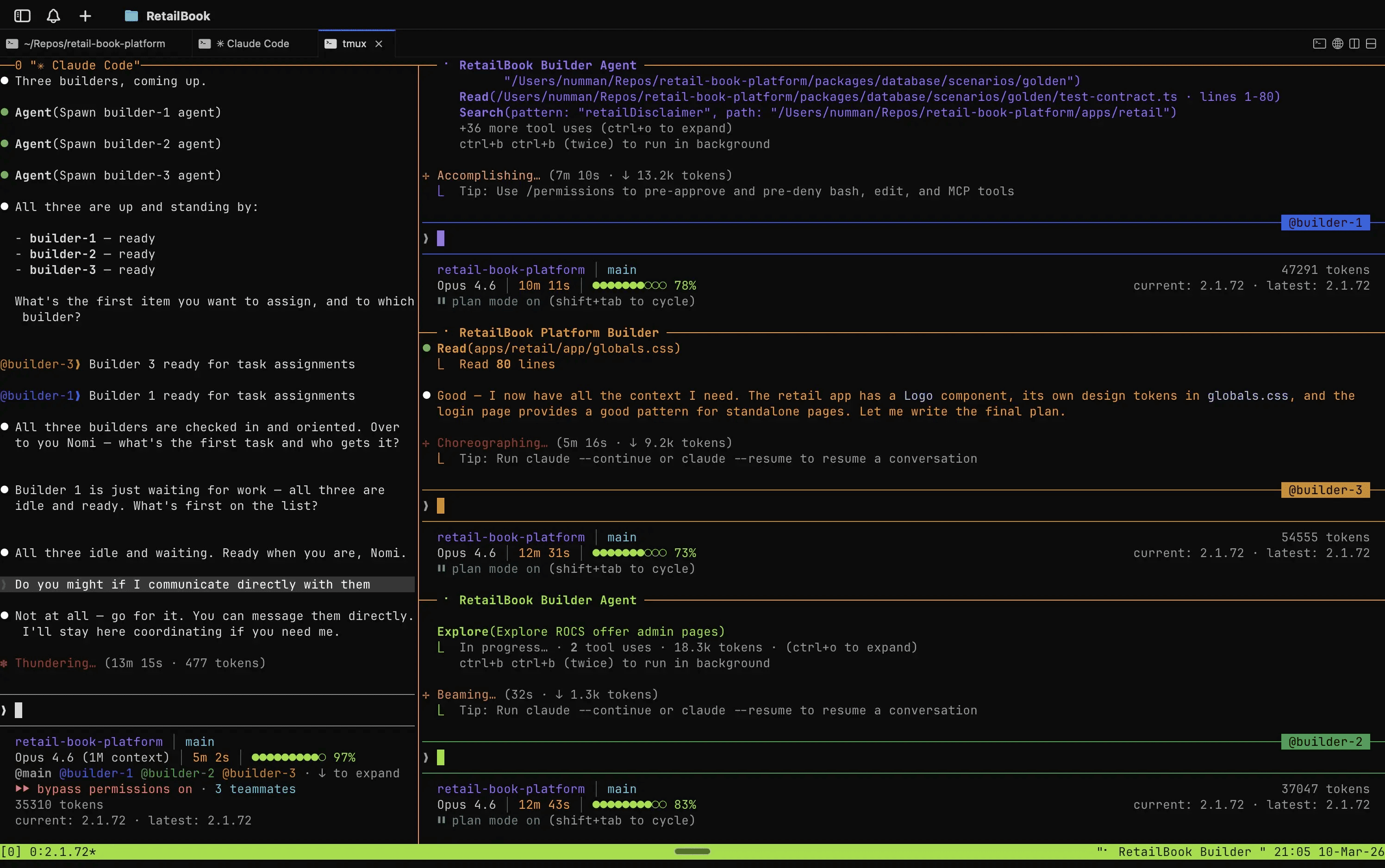
After all the specs and focusing on them once, he uses agents to implement the specs and Claude uses the feature called Agent Teams (which can be activated in Claude settings.json with CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS).
The cool thing about agent teams is that they let you coordinate multiple Claude Code instances working together. One session acts as the team lead, coordinating work, assigning tasks, and synthesizing results. Teammates work independently, each in its own context window, and communicate directly with each other.
Mark spawns multiple agents using iTerm2 and tmux, which I heavily recommend for agent work (also check Zellij for an easier start), and the agent teams feature will automatically open the additional terminals in separate panes:
It shows Claude self-orchestrating his own team. Think of it as similar to Gastown, Agor, and other AI orchestrators, but integrated into Claude.
Mark's workflow with agent teams is deliberately outcome-focused rather than code-focused. Once the agents complete their run, he checks the result against the original specs and JSON schemas, not the code itself. The only thing that matters is whether the outcome does what was defined.
Is Reviewing Code Still Needed?
The tough question was whether Mark still reviews code, especially when Claude can generate more of it in a minute than we can ever review. Mark said: "Not locally or on unimportant projects where I'm exploring the limits and potential traps of these powerful tools."
But for production pipelines or when customers asked him specifically for his opinion, he said:
Along with the wider industry, we are figuring out how to use AI safely at scale.
Also at work when they have mission-critical services such as in a bank, you can't just vibe code something. It comes down to use-cases, he said.
Besides use cases, he tried different ways of reviewing. First he tried a sophisticated process where the above agents would create PRs and he would then comment on these with improvements and changes. The agents would then read them and integrate the given feedback and continue the process. But even that workflow made him too much of a bottleneck. It wasn't scalable enough.
Mark searched for other ways to work with it.
Outcome-Driven Reviews: And Starting from Scratch Again
What he does now is assess outcomes instead. After all the rigorous time in speccing, he tests the result by running the pipeline, creating tests, or checking the code manually the old-fashioned way.
The key mindset shift here is that the first build is deliberately treated as throwaway. It's requirements exploring via building. You implement the spec once, learn what you got wrong, and expect to discard it.
That's why he tests the outcome. And once tested, he might have gotten new learnings that he could have only gotten through implementing or with actual tests. That's when he will feed these learnings back to the specs and update initial requirements, and start all over again, from scratch, letting the agent create a new outcome based on the updated specs. The cycle is: spec → build → assess → improve spec/assumptions → repeat.
This way, he has an approach with a very deep and exact iteration, almost deterministic, where he can re-run the agents with updated feedback and requirements, and get the same or similar outcome with the added updates, because of the spec-driven approach and the structured approach that spec-kit delivers, and the dedicated way he defines his requirements, which won't just be hallucinated as different inputs, end-to-end.
Though this can always happen, this approach served him very well, with a high-quality output he can trust, and a qualitative way to approach a complex problem with the help of agents.
If the outcome meets the quality he expected and it does what he wants, he goes to internal stakeholders to get feedback from them. And then the same process again, updating specs, fixing requirements errors or possible wrong assumptions, and off the agents go again.
Tests and Quality Gates
Tests and QA he writes manually. This is another way to make sure the outcome meets his expectations. Most important is the value, he says:
Value first, then outcome and then worry about other things
If it's not turning out to be valuable to the stakeholders, he wants to avoid spending more time. That's why the agent iterations and building something "quickly", with rigorous specs and definitions in place, worked well for him so far.
Senior vs. Junior: Working with AI
We move on to an interesting discussion of whether AI helps senior engineers or juniors more. Mark says (he also wrote about it) that AI helps more senior engineers, as seniors "understand the trade-offs of tech debt".
He says further that in AI iterations, we move much faster, generating legacy code and architecture constructs in days and weeks, instead of years. If Mark iterates with the spec-driven design explained above, there are multiple different architectures generated, some of which might have been bad from the very beginning.
As a senior, he thinks that we can give the right guidance from the very beginning and exclude bad outcomes and early "legacy code". No doubt, there will be code and architecture to be adapted, too, but if you lack experience, you basically have no chance of knowing.
Framework and Architectures Are for the Experienced
Mark mentions that at Gable, he is building something from scratch. Let's say we are at iteration v4: deep technical architectures are coming up, to choose an Apache Kafka infrastructure, define your schema in JSON or Avro, or use Parquet.
These decisions can only be made with experience. Sure, agents will give you a good middle ground, and with research they will potentially choose the right solution for the current problem. But how do you know what's the best solution for your given business problem? If you have built multiple data platforms and have seen many companies, you just know some of these things or developed an intuition for what's needed.
In combination with the agents, it's just a much better tool for seniors than for juniors who need to more or less blindly trust the assessments the agents made. The quality of outcome depends on frameworks and architectural choices, accumulating legacy code early if a big architectural component is chosen wrong.
In a related but further way, the knowledge is like a linter in an editor that knows things ahead of runtime. It can detect wrong choices directly.
What Mark is Using AI for
Besides the already discussed use cases of general workflow and reviewing outcomes, I asked him about how he uses AI at work, working with data contracts and the non-deterministic outcome of AI, for example.
Integrating AI into Data Contracts
As an author of a book on data contracts, and working in the business, one of Mark's priorities is to somewhat safely use AI agents to either verify contracts or help define them, if in any way possible.
As data contracts are written definitions between two parties, mostly written in YAML or JSON, it's a good medium to iterate on, where agents, humans, and all stakeholders can work on specs that can be versioned. Mark says his focus is on evals, specifically for assessing how well an agent completes a specific task, built around Gable's products or internal workflows.
The main goal of evals is to more confidently know that what AI shipped is any good. Similar to stewardship in Master Data Management (MDM), where humans in the process verified if the data quality was met, with AI generation we need a similar process at a faster pace.
That's also where he draws on his clinical background with an outcome-driven approach, comparing 200 observations from end-to-end coding agent simulations and assessing results against defined criteria. At Gable, they create a Code Graph that helps them get a skeleton view of the full data flow in code, without running any code. Connections, context, and business operations are expressed as code to be verified.
His hypothesis is that with agents at scale, we can gather datasets of behaviors such as logs of data pipelines, network logs, and other information such as agent trajectories and check based on them whether the data pipeline is compliant, like A/B testing AI Agents with a Bayesian Model. This has yet to be proven, but the hypothesis is strong.
Deterministic and Non-deterministic Work in Data Engineering
When asked about his thoughts on functional data engineering where usually jobs are reproducible and restartable with new logic/source data, and how he sees the determinism with AI work (which has a different outcome every time), he said something interesting.
He said non-determinism is a benefit. That's why the setup is specs written in markdown, combined with configs and JSON that are specific, providing precision and accuracy. If anything goes wrong or not according to plan in the generation phase, he can just change the specs and achieve this determinism by spec-driven development.
But there are still some disadvantages from running non-deterministically, that's why he still does tests and comparisons manually, and checks visually whether everything works when running the pipeline.
What Mark Thinks about AI
When talking about the future, learning with AI or where it leads, or also when not to use AI, is what we discuss here.
When not to Use AI
Starting with when he is not using AI, and when it's potentially cheaper or better to do it manually, his answer was:
Requirements finding in an important project, again depends on use cases. For small non-personal projects, not a problem. But requirements need to be defined by stakeholders and come from a real problem
Also, Mark mentioned key decisions for infrastructure code that needs to be stable and reliable. Or if used, he will spend much more time validating that LLM suggestions are correct.
For content online, he noticed that the writing always comes off differently than he would have phrased it. He might give it his insights to check or get feedback, but not the actual writing part.
How Do You See Learning with AI?
There's also the danger of not learning new things, and getting overwhelmed with constant stimulation, potentially getting slightly addicted. I asked Mark if he sees a problem in using agents and LLMs that would prevent us from learning new things as we are just cruising on auto-pilot.
Yes, he agreed. He calls it: "Claude code slot machine", or "Lab rat". "Getting your dopamine hit beyond usefulness" is how he would phrase it. He also thinks that this addictive behavior doesn't exist randomly. He thinks it is intended for us, the users, to use and spend more tokens (ergo money for them).
My closing question was where things are heading, and whether self-healing data pipelines would be a thing. When some say that "Unironically, Rick Rubin is the future of work" (where AI replaced a team of analysts, a strategist, a designer, a project manager, and a few weeks of work in minutes), the same goes for data analytics and data engineering.
Mark explains that when he was a data scientist, getting a nice histogram in Matplotlib or Seaborn took hours. Today he gets that for free, as an afterthought. He has built applications that pull leads from Hubspot, extend and aggregate data through RAG using APIs and pipeline logs, and for a board meeting just generate a static HTML page (with an export to CSV 😉). A custom-made visualization at your fingertips. That's the future, he says. Because below the visualization, there's a semantic model as the base. No one wants to open one more app, so based on well-defined semantics, AI can one-shot the visualization and integrate into existing workflows.
On the local model side, another future he sees (and is exploring himself) involves models running on a dedicated machine while he's away. He said the future is not about how powerful the models are, but how many iterations your spec has gone through. You run them until they are correct. You can also use RAG techniques to augment the model with your own notes and skills, one local model custom-made for you:
You can't compete on compute, but you can use the factor of time, iterating multiple versions for a specified problem, and choosing the best one. Exactly what clinical research is doing and what he learned in his early career comparing studies.
An interesting bleeding-edge area is running agents optimized for concurrency, chunking tasks and parallelizing them with smaller compute resources instead of one big model. Abi Aryan is doing GPU research in exactly that field, and Mark recommends starting with this post. While companies are paying 10x or more for cloud compute, local models with lots of iterations are increasingly feasible, and the economics are starting to make a strong case for them.
Next Interview
I hope you enjoyed this interview with Mark. Huge thanks to Mark for taking the time to speak with me and for sharing his experience with all of us. Follow him on LinkedIn and his Course on data quality and check out his book, its repo, and much more.
There are three more interviews already lined up with great guests, so please share feedback, questions you might want to ask or just your experience on how to work with AI in the data space. We're all in this together, figuring it all out. The more we can learn from each other, what's important, and maybe also what's not, the better.
Learn how MotherDuck's Hosted DuckLake combines lakehouse scale (borrowing the best ideas from Apache Iceberg and Delta Lake) with low latency and agent sandbox isolation, making it the simplest data lakehouse for AI-powered agentic workflows.