Quick start
Install from Settings > Community plugins, search for "DuckDB and MotherDuck".

Then paste this into any note:
```duckdb
SELECT
o_orderpriority AS priority,
count(*) AS orders,
round(sum(o_totalprice), 2) AS revenue
FROM read_parquet('https://shell.duckdb.org/data/tpch/0_01/parquet/orders.parquet')
GROUP BY 1
ORDER BY revenue DESC
```
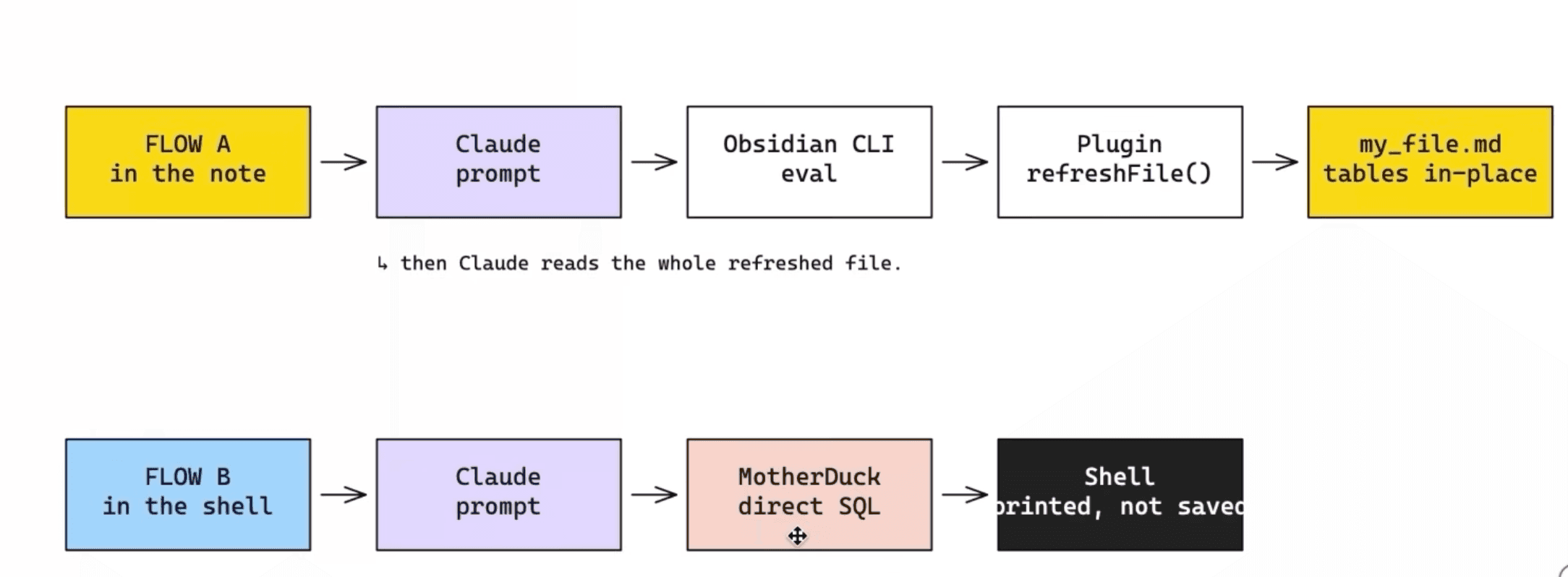
In reading mode the block renders as a SQL panel with Run, Freeze, and Clear freeze buttons. DuckDB WASM range-reads the parquet over HTTP, no token needed. It works with anything DuckDB reads: Parquet, CSV, JSON, Excel, Iceberg, Delta, geospatial files.
Hit Freeze and the result drops in as a markdown table, bracketed by sentinel comments so the next refresh knows what to replace:
<!-- md:cache hash=b54c0ac2 conn=local ts=2026-05-15T09:27:08Z rows=5 -->
| priority | orders | revenue |
| --- | --- | --- |
| 2-HIGH | 3065 | 434187711.87 |
| 4-NOT SPECIFIED | 3024 | 428175171.06 |
| 1-URGENT | 3020 | 426348805.57 |
<!-- md:cache-end -->
The sentinel carries a query hash, connection, timestamp, and row count. In raw mode it's still just markdown: it diffs cleanly in git and renders everywhere, including mobile previews.

For cloud data, swap the fence to motherduck. Every MotherDuck account has the shared sample_data database attached, so this works out of the box:
```motherduck
SELECT
type,
count(*) AS items,
round(avg(score), 1) AS avg_score
FROM sample_data.hn.hacker_news
WHERE type IS NOT NULL
GROUP BY 1
ORDER BY items DESC
```

Both connections can live side by side in the same note. Local DuckDB for files on disk, MotherDuck when you need cloud tables or want to push heavy SQL off your laptop. If you don't have an account yet, you can start with MotherDuck for free.