



2026/06/08 - Jacob Matson
The Surprising Truth About AI-Native Semantic Layers
Benchmark-maxxing DABstep to 100% and learning that an AI-native semantic layer isn't a description of your data — it's coupled to the model that reads it.
Announcing Data Outpost - The conference for data people in a world being rebuilt by AINov 4-5 | San Francisco
I hope you're doing well. I'm Simon, and I am happy to share another monthly newsletter with highlights and the latest updates about DuckDB, delivered straight to your inbox.
In this June issue, I gathered the usual 10 updates and news highlights from DuckDB's ecosystem. This month leans into the plumbing that is turning DuckDB into a real client-server citizen: the new Quack client-server protocol and the first production-grade OAuth/OIDC layer built on top of it, a local-first drag-and-drop ETL/ELT studio, DuckLake inlining for the small-file problem, a tour of DuckDB internals, and even raster files queried as plain SQL tables.
Btw, MotherDuck just launched an interesting feature called Flights, agent-native data pipelines that let an AI agent build, deploy, and operate your ingestion for you. More on that later in this issue.
📍 PS If you're in Amsterdam on June 24, DuckCon #7 is back at the Royal Tropical Institute with the State of the Duck keynote from Hannes and Mark, plus talks, lightning sessions, and drinks. More in Upcoming Events below.
If you have feedback, news, or any insights, they are always welcome. 👉🏻 duckdbnews@motherduck.com.

Ryan is a longtime BI and analytics voice and co-host of the Super Data Brothers show and author at Super Data Blog . Lately he has been stress-testing what "vibe coding BI" can really deliver. In a recent experiment, he stood up a full BI stack in under 24 hours with Claude and MotherDuck: pulling data with MotherDuck Flights, modeling it in MotherDuck, and building interactive reports with Dives, even adding PDF bursting with identity-based filtering. His point: the governance and automation gotchas that keep people from going AI-first are now well within reach.
Connect with Ryan on LinkedIn.
TL;DR: Drag-and-drop visual pipeline designer that compiles to SQL and runs on DuckDB. Tiny desktop app, no servers, git-friendly JSON workspaces.
Sourav built Duckle around DuckDB's extension model, using httpfs for S3/GCS/Azure reads, ATTACH for Redshift and pgvector connectivity, and pre-fetching vss, fts, iceberg, and delta at install time to eliminate mid-pipeline network pauses.
A React frontend talks to a Rust core over Tauri commands, with DuckDB as the engine. The engine topologically sorts the graph, lowers each node into SQL, and executes by shelling out to the downloaded DuckDB CLI. Non-sink nodes materialize as tables so later stages can reference them, sinks become COPY ... TO statements. No statically linked database keeps the binary small.
TL;DR: A new HTTP-based DuckDB extension providing a client-server protocol that uses DuckDB's internal serialization for single-round-trip queries and parallel bulk transfer.
Probably last month's biggest news: DuckDB added native client-server support. Quack lets one instance act as both client and server such as CALL quack_serve('quack:localhost'); and ATTACH 'quack:localhost' AS remote; then FROM remote.query('SELECT s FROM hello'). It runs over HTTP, defaults to localhost port 9494, generates a random startup token, reuses DuckDB's binary serialization (the same primitives as the WAL), and allows parallel fetches to minimize round trips.
On m8g.2xlarge VMs it moves 60M rows in 4.94s (Arrow Flight 17.40s, PostgreSQL 158.37s) and hits ~5.4k small INSERT tx/s at 8 threads (Postgres ~4.3k). This opens many new use cases.
See Hannes's presentation at AI Council, his hands-on session building everything from scratch on EC2 for inspiration, or read Jordan's perspective on Quack, and the 1.5.3 announcement shipping Quack as a core extension.
TL;DR: Adds local DuckDB WASM and MotherDuck-backed SQL blocks to Obsidian.
Mehdi's plugin offers streaming query execution, inline markdown caching (freeze), scheduled refresh, and build/runtime optimizations to cut memory and startup costs. Local queries use DuckDB-WASM (defaulting to :memory:), and cloud queries use a MotherDuck WASM extension.
It can query local CSV and XML, plus remote files via extensions such as HTTP(S) or Hugging Face (hf:). Freeze the output to keep results in your notes without rerunning, or set auto-refresh. More in his blog post.
TL;DR: An Arrow Flight SQL server fronting DuckDB that delivers TPC-H SF1000 (1TB) in ~161 s for ~$0.17 on Azure.
Built on Apache Arrow and DuckDB, GizmoSQL adds authentication, session instrumentation, and queuing to make DuckDB usable as a shared, multi-client OLAP server. Clients connect via CONNECT TO 'jdbc:gizmosql://gizmosql.example.com:31337' USER 'user' PASSWORD '...'; and run standard SQL.
It even runs on iPhone and iPad if that is your thing 😉. This video walks through setup step-by-step. Practical for a low-latency, low-cost shared SQL endpoint for DuckDB analytics or multi-agent workflows.
TL;DR: The first production-grade OAuth2/OIDC validation and SQL-native authorization for the new Quack protocol.
It replaces Quack's stubs (default secret token) with real validators (JWKS per-kid cache, RFC7662 introspect, Google tokeninfo, GitHub token validation) and client flows (client_credentials, refresh_token, RFC8628 device_code). It registers server and client SECRET types, installs callbacks, classifies actions via DuckDB's parser, and evaluates a hot-reloadable SQL policy table. Probably the first extension to try for proper authentication to Quack.
TL;DR: Exposes raster datasets as SQL tables (one row per tile) with datacube-aware operators and IO, so pixel- and tile-wise raster workflows run entirely in SQL.
RT_Read opens rasters or mosaics and returns rows with geometry, bbox, band metadata (JSON), and per-band datacube columns, with filter pushdown to skip tiles before pixel reads. Band algebra and nodata-aware arithmetic operate directly on datacubes. Export results with COPY (...) TO './ndvi.tiff' WITH (FORMAT 'RASTER', DRIVER 'COG', ...) or as vector-friendly tables (GeoParquet, GeoPackage).
TL;DR: DuckLake's data inlining keeps small, frequent commits in the catalog instead of writing tiny Parquet files, moving them to Parquet only when a per-transaction threshold (default 10) is exceeded or on explicit flush.
Hoyt deep dives into the inlining features after 1.0 DuckLake released that feature, and explains how inlining addresses the small-file problem. Inlined rows (and tombstones) live as regular catalog tables, so queries read one unified logical table while physically combining Parquet files and metadata-resident rows. Deletes and updates create inlined delete records rather than rewriting Parquet (the tombstone pattern). Per-transaction row counts above threshold write Parquet immediately. Otherwise, rows stay inlined. Consolidate manually via CALL ducklake_flush_inlined_data('lake', table_name => 't') or CHECKPOINT (flush plus cleanup). A video version is also available.
TL;DR: DuckDB achieves high single-node analytical performance by running in-process (no client-server serialization), using columnar row groups with zone maps and Parquet statistics to prune I/O, and a vectorized/morsel-driven execution model with pipeline parallelism.
In Part 1, Kyle explains that DuckDB parses SQL with a Postgres-derived parser, binds types, then runs ~30 small optimizer passes (disable specific ones with SET disabled_optimizers = 'filter_pullup, join_order'). Optimization usually finishes in about a millisecond. Columns sit in row groups (up to 122,880 rows) mapped into ~256 KB blocks with checksums, each carrying min/max/null zone maps that enable row-group skipping, and Parquet exposes equivalent per-row-group stats. CSVs use a sniffer (default 20,480-row sample) to detect dialect and types. DuckDB often achieves zero-copy reads via replacement scans or Arrow-backed buffers, avoiding a second copy when formats align.
TL;DR: An Arrow Flight SQL gateway in front of DuckDB/Quack with multi-tenant pools and per-tenant DuckLake catalogs.
A single uber-jar combines a REST API, React admin UI (/ui/), and an Arrow FlightSQL gateway that streams zero-copy results with TLS on by default (auto-generated self-signed cert). The router classifies statements as READ/WRITE/DDL and routes to nodes labeled READONLY, WRITEONLY, or DUAL, enabling role-aware routing and per-tenant pools that run as local child processes or Kubernetes pods. State and grants live in Postgres alongside the DuckLake catalog, with principal expansion to user/group/role at validation. Auth is pluggable: database (bcrypt), JWT (HS256/RS256/PEM), and OIDC (Keycloak ROPC, Google, Azure AD, AWS Cognito).
TL;DR: Extends DuckDB to Cloudflare Workers, adding Durable Objects support and JWT-based authentication.
This Cloudflare Workers service uses DuckDB's Quack HTTP protocol and integrates with Durable Objects for distributed catalog management and execution in serverless environments. Attach a catalog with ATTACH 'ducklake:quack:<worker-host>:443' to manage data across R2-backed DuckLake DATA_PATH instances, with scalable catalog handling and fine-tuned auth policies.
TL;DR: Flights are scheduled Python jobs that run on a managed runtime inside MotherDuck, built so an AI agent can write, deploy, and operate your ingestion pipelines straight from a chat session.
This is the one I teased up top. Moving data into a warehouse has always been the unglamorous part: pick a tool, wire up credentials, hand-code the glue, babysit the schedule. Flights flips that around. You point Claude, Cursor, or your agent of choice at MotherDuck's MCP server, describe the source (a CRM, a database, an API), and the agent generates the pipeline code, deploys it to the Flights runtime, schedules it, and can even read the logs and patch itself when a run fails. Under the hood it is a general-purpose Python runtime, and dlt is the recommended ingest library, so you get declarative pipelines with schema evolution, incremental loading, and a first-class MotherDuck destination. Pair it with Dives and you can go from raw source to live dashboard in a single conversation.
2026-06-17. h: 09:00. Online
A live walkthrough of Flights: why it exists, the three ways to create one (MCP server, SQL table functions, or the MotherDuck UI), deploying a production pipeline from a Flight Plan template, and how Flights pairs with Dives to go from raw data to a live dashboard in one chat session.
2026-06-24. h: 15:00. Royal Tropical Institute, Amsterdam
The official DuckDB community conference returns to Amsterdam. Catch the State of the Duck keynote from Hannes Mühleisen and Mark Raasveldt, talks on migrating PySpark to DuckDB with SQLFrame, how Spotify built a SQL layer for agentic access, and DuckDB in cancer genomics, energy policy, and rally racing telemetry. Capped off with drinks and snacks.
2026-07-08. h: 09:00. Messe Berlin, Berlin, Germany
The world's largest gathering of developers, software architects, and tech leaders, with 15,000+ attendees from 100+ countries. MotherDuck is a sponsor, so come say hi.
2026-08-04. h: 09:00. The Venetian, Las Vegas, NV
America's largest AI conference. Catch MotherDuck CEO Jordan Tigani on the Data Engineering panel: "Building the Modern Data Stack for AI: What's Working and What's Not."
2026/06/08 - Jacob Matson
Benchmark-maxxing DABstep to 100% and learning that an AI-native semantic layer isn't a description of your data — it's coupled to the model that reads it.
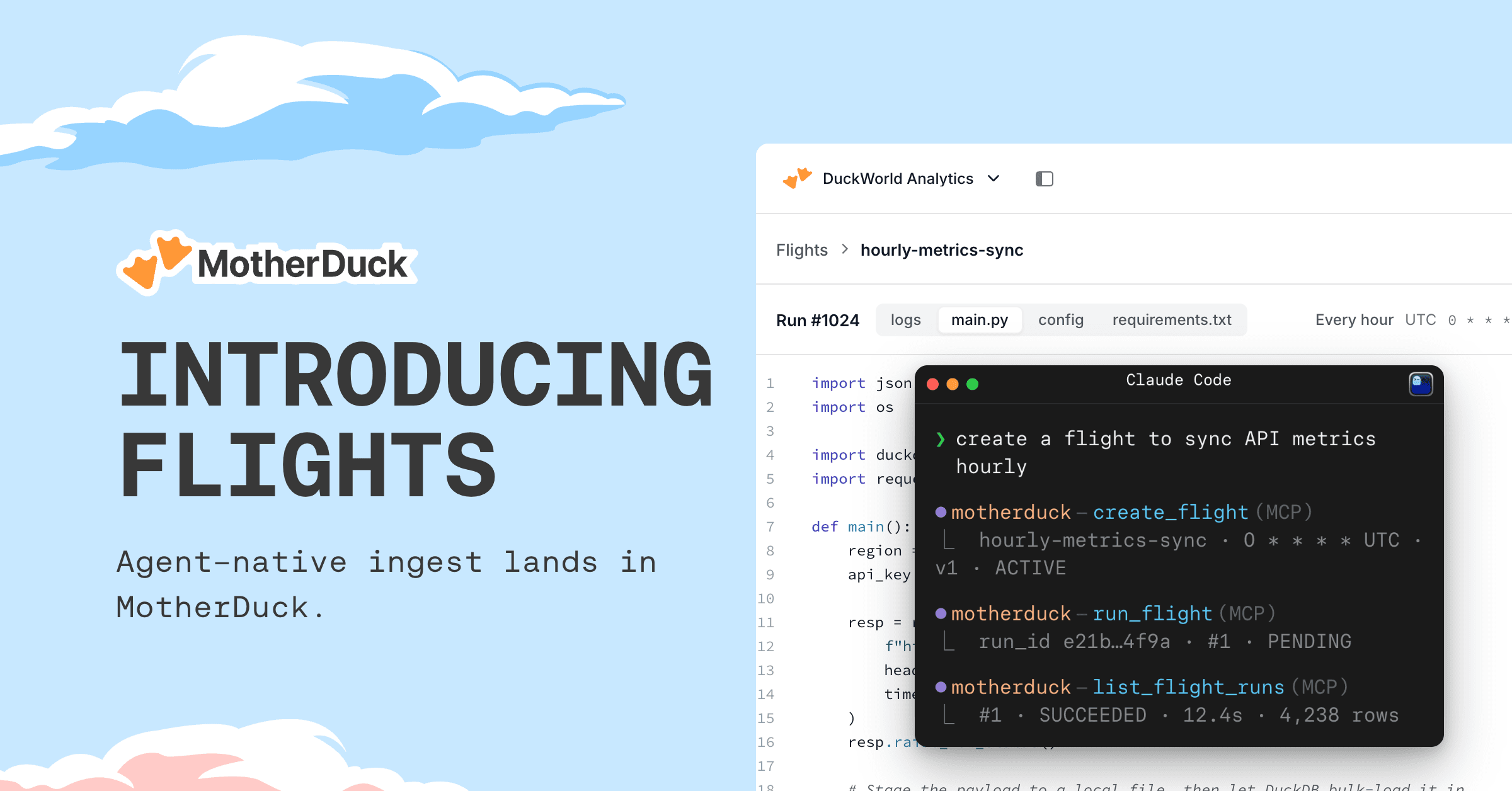
2026/06/10 - Doo Shim, Miguel Miranda
Build, deploy, and schedule Python data pipelines from a prompt, a SQL function, or the MotherDuck UI.