This series interviews real practitioners to extract the patterns behind how they actually use AI in their data work today. This is the third interview in 'How to use AI with DE, and this time we have none other than Wes McKinney.
Creator of Pandas, probably the most widely used data analysis library for Python, Wes has shaped the era of data and is co-creator of Apache Arrow. He also created Ibis to address these issues with a different approach to Python dataframe libraries, by decoupling the dataframe API from the backend implementation.
The article is structured in four parts: (1) how to trust the outcome, (2) knowing what not to build, factoring in cost-per-token among others, (3) accountability of agents and the code they generate, and (4) philosophizing about the future of agentic engineering.
Introducing the Guest: #3 Wes McKinney
Besides creating the most popular dataframe libraries used by most data people, Wes McKinney now focuses full time on agentic engineering with his newly founded company Kenn Software, which focuses on the promise of building a new stack of development and knowledge systems for the agentic era. He's also doing AI and Python at Posit, where they work on a data science IDE. He's a part-time investor in various startups.
Wes has been running Claude Code, Codex, and Gemini CLI for months. Thousands of sessions, hundreds of thousands of messages. He has released multiple tools that help the agentic work (more on this later), and he is at the forefront of what's going on with his recent blog posts about "Why he uses programming languages built for agents, not humans" and Mythical Agent Month, with his recent insights into how to work with agents. Find all his takes at Wes McKinney.com.
I had the pleasure of asking Wes more about these topics, and we'll go into more details, plus many other things. Let's get started.
How to Trust the Outcome?
We started the interview with a critical question that stands above all others in the current AI landscape, and I asked him: "Can we trust the outcome?". What if we need something important, other than a hobby project? What if the data must be correct (hospitals, banks)?
Similar to what Mark Freeman told us in our last interview about using spec-driven development with spec-kit, Wes uses a similar approach, but with an agentic skill framework called superpowers (currently 216k stars on GitHub). Compared to spec-kit, it specs out the requirements differently by (A) guiding you through the conversation, asking you the right questions to get to what you want to build, and (B) once you fire it off, it spawns a sub-agent that keeps the implementing agent on track. Wes said, "Superpowers looks for drift", and course-corrects if the implementing agents drift off to non-relevant, or not even specified, tasks.
Wes spends a lot of time in this specification phase, sometimes hours, very detail-oriented and engaged. Even before he starts speccing, he has subconsciously worked over the topic and idea for a long while. He will not start implementing something when he doesn't know super clearly how it fits together. The insights, the architecture, come from him. But the interview style by superpowers helps him clarify his thinking.
He doesn't only give his feedback to the questions, but sometimes also fires up multiple agents and integrates their feedback. Codex models especially seem to work well for design questions.
He puts a lot of importance on the spec being:
Spec conformant: Meaning the agents act in accordance with your specific set of rules, standards, or specifications.
Code correctness and quality: This is where Wes uses e.g. Roborev, his own created AI-reviewer.
Correctness is crucial, which led to creating Roborev. Wes developed many tools that help him work agentically, and we'll hear about many more later. Roborev, for example, is a code reviewer that can be initialized with a hook on a git repository, and from that moment on, every commit will be auto-reviewed by Codex (the default, but you can choose others too).
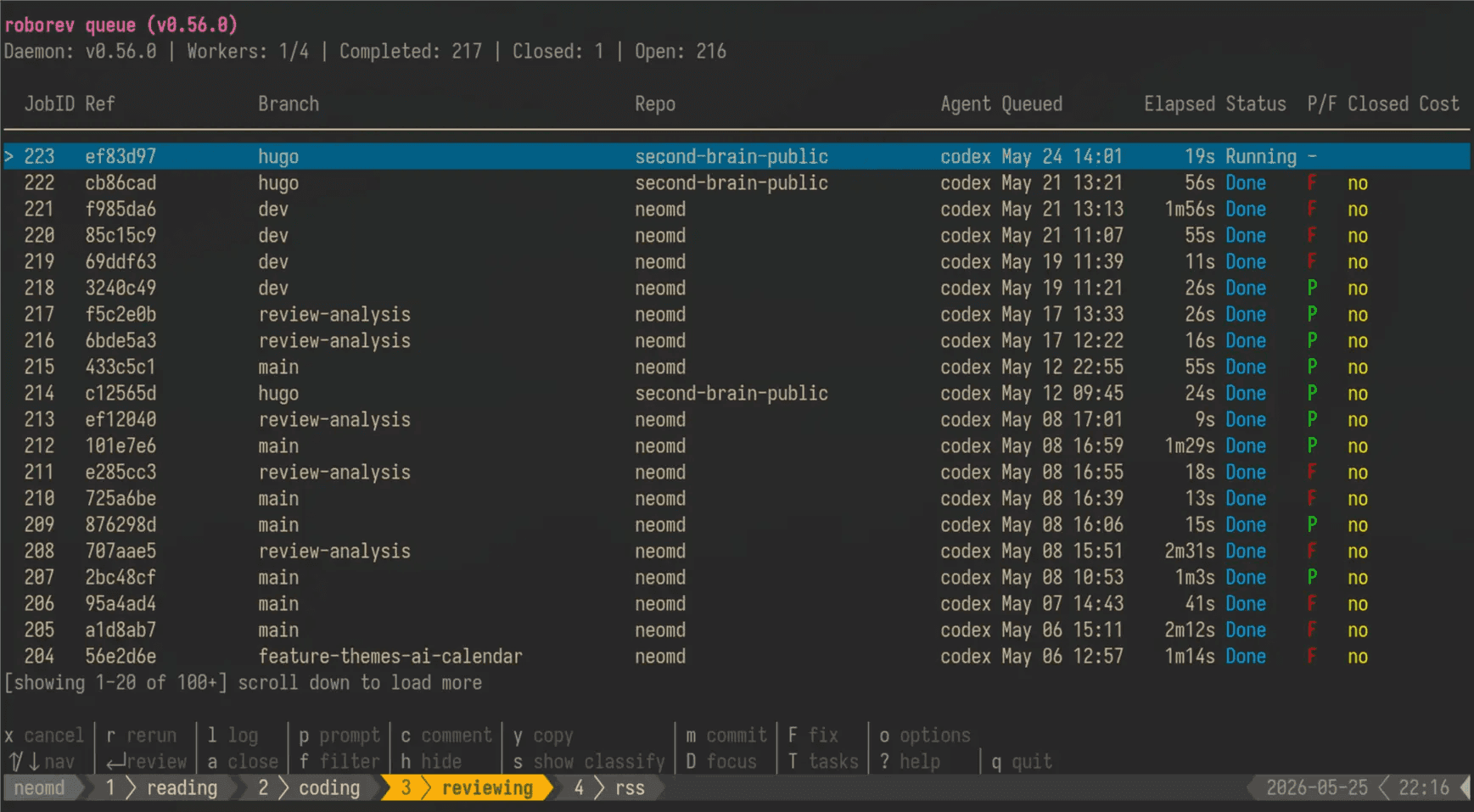
I use Roborev myself, and this is what the interactive TUI looks like - showing the most recently fired hooks with their running status, but most importantly, whether the review passed (P) or failed (F):
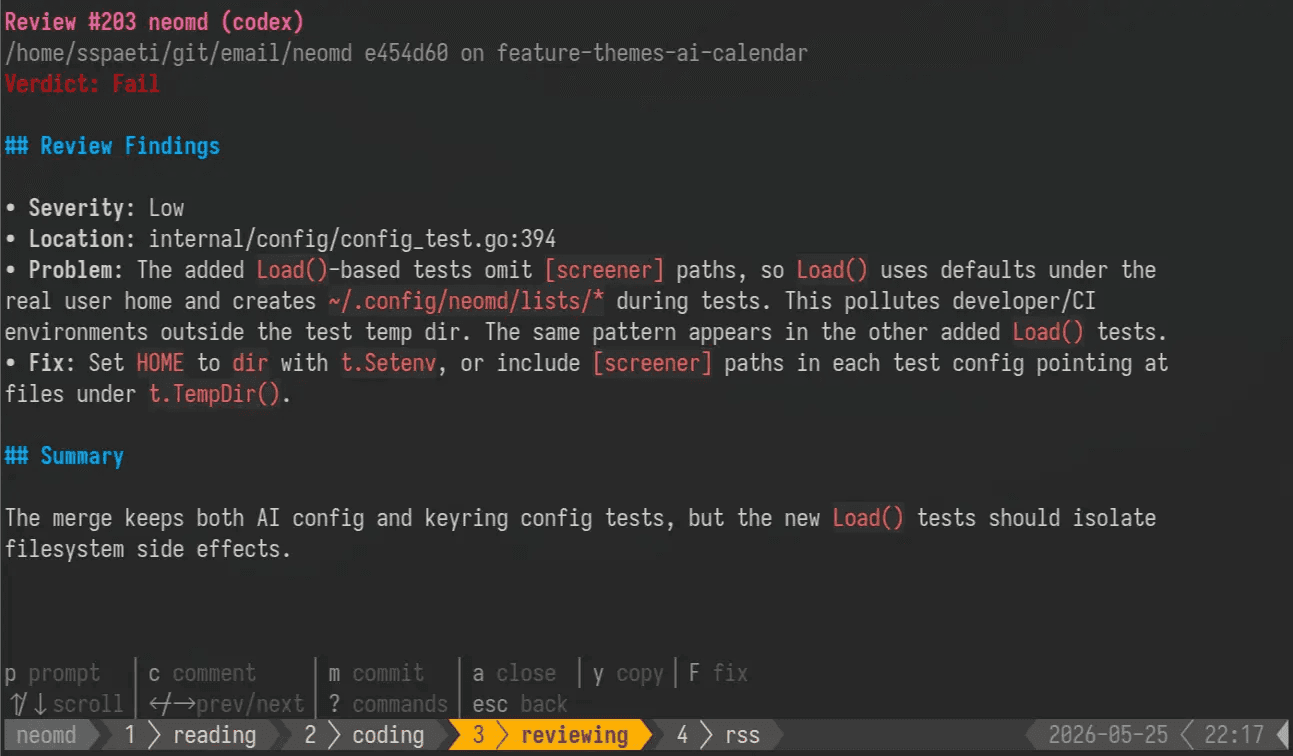
If it failed, you can open the review and see detailed findings categorized into severity low, medium and high:
The convenient workflow is that you copy the review with y and feed it back to your running agent to let it fix things directly. The current agent that created the change works best, as it already has all the context, compared to starting a new one that needs to load context and what has been done.
Roborev also helps to review a smaller part at a time. Wes also says it will never catch all the errors, but LLMs are very good at pattern matching, which is what error finding is, and they find many that might be missed. On top, he adds reviewers with different roles, e.g. giving agents roles such as focusing on security, CI, software development, or performance, which gives much more accurate feedback than a general reviewer.
After having gone through the spec intensively, having made sure that drift happens as little as possible, and having auto-reviewed each commit by Roborev, what is left for him to review is much less now, and of high quality. He then reviews the code and checks that it looks and does what he expects or envisioned.
Wes has a very clear problem or idea that he then solves meticulously. However, at the same time, he runs agents in parallel and works on many projects concurrently, context-switching between them1.
NOTE: Rigorous process in place needed: Changing models
The rigorous process he does is also needed because the models are constantly changing and are very unpredictable. It is hard to have a consistent outcome if you do not have reviewers and processes in place. And Wes says these AI reviewers are much better than just static analysis.
How to Maintain Agentic, or General Projects over Time?
The second question was about maintaining projects and how Wes handles maintenance, as creating projects is usually the easy part, but maintaining them for years to come is difficult. And how does he see that in combination with AI? Will that be outsourced to AI?
First of all, Wes uses his own projects and tools. That's the reason they exist, and it helps him find bugs. This is why he fixes errors or bugs when he runs into them. Besides Roborev, which helps tremendously to review and have fewer errors while developing, he uses Middleman to keep an eye on his agents and projects. It's another tool he built that gives him a local-first GitHub dashboard and triages what to maintain or fix from other users.
He automated repetitive work such as releasing with a full release script so he can release fast and fix bugs fast. The Changelog on GitHub is fully streamlined, too. He is also careful about what comes into the main branch, only changes he has verified and assessed as "pass".
To illustrate what Wes is maintaining, here are some of the projects Wes built recently, some of which he might not have built without AI:
roborev: Continuous code review for AI coding agents. Runs in the background and surfaces issues per commit before they compound.
middleman: Local-first GitHub dashboard for maintainers to triage, review, and merge PRs and issues across repos.
agentsview: Local coding agent session viewer for Claude, Codex, and Gemini with analytics and full-text search.
msgvault: Archive a lifetime of email and chat locally, with full Gmail backup, DuckDB analytics, a TUI, and an MCP server for AI queries.
moneyflow: Personal finance data interface for power users, supporting backends like Monarch Money and YNAB.
Spicy Takes: LLM-analyzed blog posts from 20+ prolific tech writers, each with a TL;DR, key quotes, and a spiciness rating.
VibePulse: Simple macOS menubar app to monitor Claude Code and Codex token consumption.
kata: Local-first issue tracker for AI-assisted software work, with an agent-friendly CLI and human-facing TUI.
NOTE: Earlier Tools and Frameworks Wes Has Built
Positron: A next-generation data science IDE built on VS Code, supporting Python and R.
pandas: The most widely used data analysis library in Python.
Apache Arrow: Language-independent columnar memory format for analytics.
Ibis: Portable Python dataframe API that works across any backend.
Building for Maintainability: Modular?
I asked him if he builds for better maintainability, e.g. builds in a modular way so the AI agents can easily fix something or create a feature in a dedicated area without breaking the full program.
He didn't answer the modularity part directly, but Wes implements and uses tests extensively. If something needs to exist, he writes a test for it. But even more, by investing in test infrastructure, regression tests help prevent bugs and protect existing features during rapid development.
He also mentions that bugs are created faster these days, but also fixed faster.
How to Decide what to Build? Saying No!
Given that AI can get addictive, and in a time when you can build almost anything, I asked Wes how he knows what to build, and when to say no to avoid building the "wrong things".
He said that:
It's not the ideas on their own, he's thinking a lot about what he wants to build.
Again, it is in his subconscious. He thinks and asks himself all day: "How is it beneficial for agents? For humans? How can it be applied?"
If he can't explain it, he will think more. For example, msgvault didn't have a web interface, and he could have easily added one from the very beginning, but he didn't have a clear picture. So he just postponed it until later, when he had a use case, a pain point, or a real need.
"Those are the constraints", Wes adds. "Because if you don't, AI will bring in lots of crap".
Superpowers also helps him with guardrails by keeping the AI on track. Besides, Wes has a perfectionist mindset, making him want to perfect the tool that works for him and improve the workflow.
When He Was Building without AI: Pandas
It was the same when he was building Pandas: he was building it for his use case when fiddling with Excel. Then there is taste.
Every prompt, every decision in the spec phase adds up to 100s or 1000s of small decisions, essentially manifesting one's taste. That's why the product comes out differently from two people, even though they use the same LLM models.
NOTE: Find more at AI Council Talk about the Scope, Design and Taste in the Mythical Agent Month
Wes gave a very insightful talk at AI Council 2026 about this very topic, called the Mythical Agent month. He said what is left is "Scope, Design and Taste" with Conceptual Integrity (from the book by Fred Brooks).
Saying No is Our Last Defense
In his recent slides, he shares "When code is free, saying no is our last defense":
Every new feature is cheap to create but expensive to maintain. Each one adds surface areas for bugs, confusion, and future agent mistakes.
TIP: "Hell Yeah or No": A similar term by Derek Sivers
Similar to Wes's figuring out and saying no as our last defense, Derek Sivers said something similar before, where you say no to everything until you feel "Hell Yeah". This Hell Yeah or No approach doesn't seem to have changed much with AI. This doesn't apply only to AI, but also to life and career, in my opinion.
Cost-per-Token at True Price Will Stop the Waste
A very current topic is how the growing cost-per-token factors into this decision of what to build. Or does it not? There's even a term called token maxxing that encourages programmers to use more tokens, whether by the company or by peer pressure on X/Twitter.
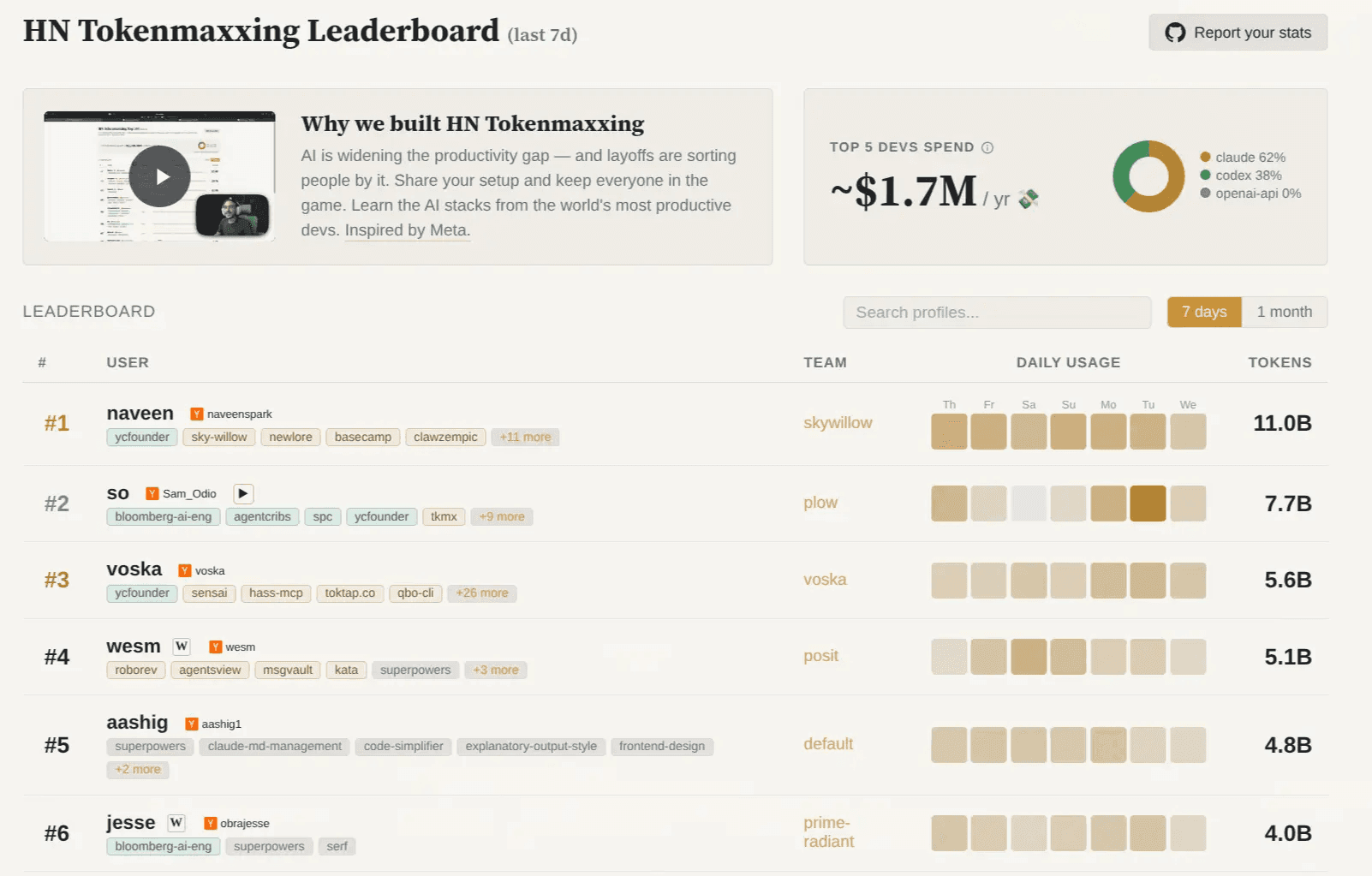
Wes was at the top of the HN leaderboard at some point, currently on #4:
Wes's current usage is ~$20,000/month at API rates, which he sees on another tool he built called AgentsView. He said that
He thinks that all his high-quality output through the shared tools or the work he does is higher than the invested money.
But on the economics side, he thinks that:
Subscriptions go away, and pay by usage, a good thing. AI slop and low-value projects go away. This helps pay the true cost of tokens, which isn't the case for now, making the consumption (or even waste) of lots of tokens non-problematic.
Enterprise Token per Employee: Clarify Useful vs. Vanity AI Work
This was actually one reason why he built AgentsView: to have an overview of your own usage, a better "token intelligence", but also at a larger company to measure each developer's usage. It could be part of performance reviews, showing each user's token spend vs the value generated.
You'd have to justify your tokens, the opposite of now, where developers at Meta or Amazon are expected to burn tokens without incentives. Right now, it's the wild-wild-west (something previous interview guest Chris Riccomini also said).
Accountability of Agent-generated Code? Who is Responsible?
My next question was how do we make people accountable for things they didn't create (vibe coded)? I gave the example of self-driving cars: who takes accountability if a Tesla hurts someone? (That's one reason full self-driving is still not allowed in Europe, as it's legally not settled who is accountable.)
Vibe Coding ≠ Vibe Coding: But Agentic Engineering
Wes made clear that what he does is not vibe coding, but agentic engineering. All the planning and architecting with superpowers and his newly created tools is not the same as vibe coding.
The term vibe coding to him means when you just one-prompt it, don't look at the code, and ship it. Again, this is not what he does.
He says:
We can't disengage from planning and writing specs. We can move much faster, but don't vibe code. Vibe coding is very dangerous and irresponsible.
Like the Coinbase example, he finds letting non-technical employees push to production highly dangerous. We humans, with fundamental understanding and seniority, need to be more engaged in designing and testing, as coding is essentially "cheap" now.
He continues:
Automated code review certainly helps, but it isn't a substitute for engineering experience.
Philosophize about the Future with Agentic Engineering
Wes is also an investor, a person who foresees the landscape well with his involvement in major data libraries. I asked him: "If you think about AI, where would you invest your money? What do you trust will have the most benefit or will work well with AI?"
Where do you see the future heading, or where does this end? Especially when we talk about data engineering?
Future of Data Engineering
He says that he is not involved too much in data engineering anymore, but that he is an investor in dlt, MotherDuck, and Bruin. But his main focus is on agentic work, somewhat on top of the "dbt legacy"3.
But what he sees as currently the hot topic is Headless BI, custom dashboards, and building a semantic layer for better context for agents. Things like business rules and sending the "right" queries. Building new knowledge systems for companies. For example, through msgvault, which extracts value from years of emails and easily makes them searchable.
He saw people building personal CRMs on top of msgvault and their emails. That's the current direction we are heading, he says.
How Do We Still Learn? By Learning by Osmosis
The challenge will be: how do we develop senior engineers without writing code anymore? Wes himself doesn't write much code anymore, but reviews, guides, and adds taste. I asked him how someone can gain the work experience he has without the coding or going through the pain of coding, while avoiding the danger of not learning anything new, or getting overwhelmed with constant stimulation and potentially becoming addicted.
He says the hard labour goes away, which is where we usually learn. This is the way of learning by osmosis2, where we acquire knowledge while failing or naturally through exposure and immersion. He thinks the focus needs to be on design patterns and understanding architecture, to have the technical vocabulary to guide or understand the agents.
Next Interview
I hope you enjoyed this interview number 3 with Wes. Huge thanks to Wes for taking the time to speak with me and for sharing his experience with all of us. Follow him on Website, LinkedIn, X/Twitter, or on Bluesky, and follow along on his new company Kenn Software, or check out his agentic engineered tools he built at GitHub.
There is one more interview already lined up with none other than Maxime Beauchemin, so please share feedback, questions you might want to ask, or just your experience on how to work with AI in the data space. We're all in this together, figuring it all out. The more we can learn from each other, what's important, and maybe also what's not, the better.
1.On the podcast with Joe Reis, Wes shared that he was very locked-in, always had running agents, building things, which was "terrible for his sleep schedule", but very fun.
2."Learning by osmosis" is an idiomatic expression drawing on the figurative sense of osmosis: the gradual, often unconscious absorption of knowledge through exposure rather than deliberate study. Collins English Dictionary
DiveMaxxing is an online data viz competition for MotherDuck Dives. Three categories, duckified Mac Minis on the line, and a community vote. Free to enter through June 22.
Run DuckDB SQL inside your Obsidian notes and freeze the results as plain markdown tables, local files or MotherDuck cloud data alike. Your vault becomes a local knowledge base your AI agent can read without ever querying the warehouse